This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ScaleGrid MySQL on Azure so you can see which provider offers the best throughput and latency performance. We measure latency in ms 95th percentile latency. During Read-Intensive Workloads, ScaleGrid manages to achieve up to 3 times higher throughput and averages 66% better latency compared to Azure Database.
A significant feature of Chronicle Queue Enterprise is support for TCP replication across multiple servers to ensure the high availability of application infrastructure. This is the first time I have benchmarked it with a realistic example. This is the first time I have benchmarked it with a realistic example.
Redis Server: 5.07, x86/64. MongoDB server: 4.4.2, BangDB server: 2.0.0, We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. Again Yugabyte latency is quite high. The latency table for test D is as below.
Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency. Kafka clusters can be deployed in Kubernetes using Helm charts to simplify scaling and management across multiple servers.
Instead, they can ensure that services comport with the pre-established benchmarks. Using data from Dynatrace and its SLO wizard , teams can easily benchmark meaningful, user-based reliability measurements and establish error budgets to implement SLOs that meet business objectives and drive greater DevOps automation. Reliability.
A span: Represents a unit of work, such as a network call from one service to another (a client/server relationship) or a purely internal action (e.g., Telltale provides Edgar with latencybenchmarks that indicate if the individual trace’s latency is abnormal for this given service. starting and finishing a method).
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Understanding Redis Performance Indicators Redis is designed to handle high traffic and low latency with its in-memory data store and efficient data structures.
Data collected on page load events, for example, can include navigation start (when performance begins to be measured), request start (right before the user makes a request from the server), and speed index metrics (measure page load speed). In some cases, you will lack benchmarking capabilities. RUM generates a lot of data.
PostgreSQL Cluster One coordinator node citus-coord-01 Three worker nodes citus1 citus2 citus3 Hardware AWS Instance Ubuntu Server 20.04, SSD volume type 64-bit (x86) c5.xlarge And now, execute the benchmark: -- execute the following on the coordinator node pgbench -c 20 -j 3 -T 60 -P 3 pgbench The results are not pretty.
If we were to select the most important MySQL setting, if we were given a freshly installed MySQL or Percona Server for MySQL and could only tune a single MySQL variable, which one would it be? Sysbench ran on a third server, which I’ll refer to as the application server (APP).
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook , Cao et al., Or in the case of key-value stores, what you benchmark. So if you want to design a system that will offer good real-world performance, it’s really useful to have benchmarks that accurately represent real-world workloads.
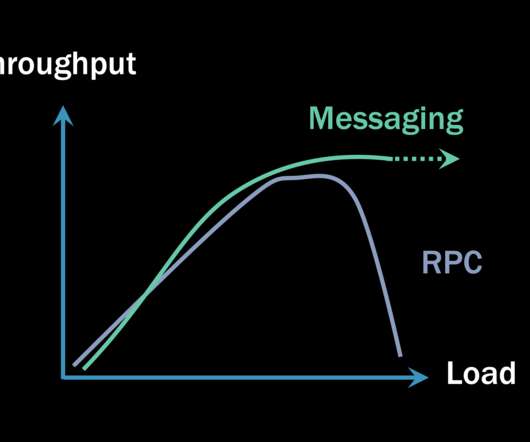
Some will claim that any type of RPC communication ends up being faster (meaning it has lower latency) than any equivalent invocation using asynchronous messaging. But to be fair, we also have to process the messages on the server before we can consider the messaging case to be complete. But the answer isn’t that simple.
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures. On MySQL, we saw a 1.5X
As a MySQL database administrator, keeping a close eye on the performance of your MySQL server is crucial to ensure optimal database operations. However, simply deploying a monitoring tool is not enough; you need to know which Key Performance Indicators (KPIs) to monitor to gain insights into your MySQL server’s health and performance.
Server-timing headers are a key tool in understanding what's happening within that black box of Time to First Byte (TTFB). Looking at the industry benchmarks for US retailers , four well-known sites have backend times that are approaching – or well beyond – that threshold.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., A typical architecture diagram for one of these services looks like this: Suitably armed with a set of benchmark microservices applications, the investigation can begin! ASPLOS’19.
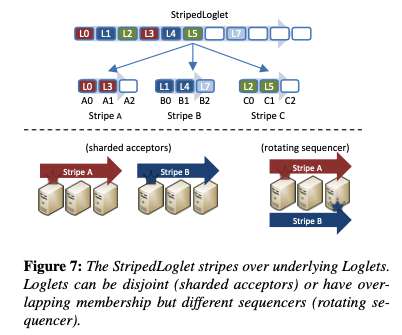
The initial version of Delos went into production after eight months using a ZooKeeper-backed Loglet implementation, and then four months later it was swapped out for a new custom-built NativeLoglet that gave a 10x improvement in end-to-end latency. In Facebook’s implementation of NativeLoglet, seal simply sets a bit on a quorum of servers.
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. Some servers may need a few GBs of RAM, while others may need hundreds of GBs or even terabytes of RAM. Benchmark before you decide. I hope this helps!
Introduction Caching serves a dual purpose in web development – speeding up client requests and reducing server load. Redis Revealed: An Overview Redis, a renowned open-source, in-memory remote dictionary server, stands out for its diverse data structures and advanced features. Data transfer technology.
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
This will be clearly visible in PostgreSQL performance benchmarks as a “ Sawtooth wave ” pattern observed by Vadim in his tests: As we can see, the throughput suddenly drops after every checkpoint due to heavy WAL writing and gradually picks up until the next checkpoint. But this comes with a considerable performance implication.
As part of our new support for ARM processors , we recently ran benchmarks on both Intel C7 and ARM c7g on AWS. The goal of these benchmarks was to both quantify performance differences between the two platforms and gain an understanding of their TCO. We used an in-house benchmark called voltdb-charglt. What is “KTPS/Pair”?
The resource loading waterfall is a cascade of files downloaded from the network server to the client to load your website from start to finish. On your first try, you can use it as a benchmark for optimizations later. Client Side Rendering, Server Side Rendering And Jamstack. On design systems, UX, web performance and CSS/JS.
Let us take a look also the latency: Here the situation starts to be a little bit more complicated. MySQL Router is the one that has the higher latency no matter what. Looking at the latency, we can see that HAProxy gradually increased as expected, while ProxySQL and MySQL Router just went up from the 256 threads on.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. This server is spending about a third of its CPU cycles just checking the time! I've shared many posts about superpower observability tools, but often humble hacking is just as effective. 30.14% in the middle of the flame graph.
These include popular technologies such as web servers and web applications, along with advanced solutions like distributed data stores and containerized microservices. It also provides high availability and super user access features while offering dedicated servers specifically designed for MongoDB cloud hosting.
Using a global ASP as a benchmark can further mislead thanks to the distorting effect of ultra-high-end prices rising while shipment volumes stagnate. Sadly, data on latency is harder to get, even from Google's perch, so progress there is somewhat more difficult to judge. Today, either method returns a similar answer.
When we released Always On Availability Groups in SQL Server 2012 as a new and powerful way to achieve high availability, hardware environments included NUMA machines with low-end multi-core processors and SATA and SAN drives for storage (some SSDs). As we moved towards SQL Server 2014, the pace of hardware accelerated.
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Consistent performance matters just as much as low average latency.
Budgets are scaled to a benchmark network & device. Late-loading JavaScript can cause “server-side rendered” pages to fail in infuriating ways. The server sends it as a stream of bytes and when the browser encounters each of the sub-resources referenced in the document, it requests them. Global Ground-Truth.
Google’s industry benchmarks from 2018 also provide a striking breakdown of how each second of loading affects bounce rates. Redirects are often pretty light in terms of the latency that they add to a website, but they are an easy first thing to check, and they can generally be removed with little effort.
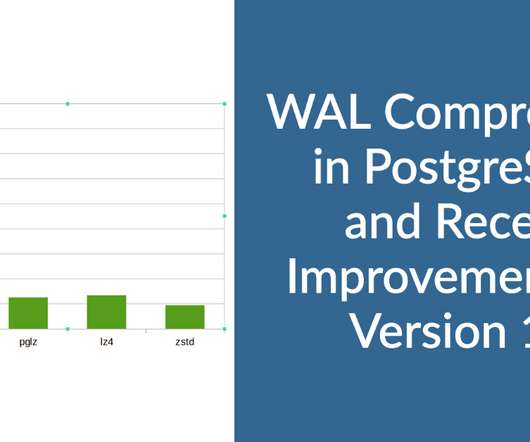
If you are new to running Oracle, SQL Server, MySQL and PostgreSQL TPC-C workloads with HammerDB and have needed to investigate I/O performance the chances are that you have experienced waits on writing to the Redo, Transaction Log or WAL depending on the database you are testing. SQL Server DELAYED_DURABILITY. Logging Waits.
There was an excellent first benchmarking report of the Cluster GPU Instances by the folks at Cycle Computing - " A Couple More Nails in the Coffin of the Private Compute Cluster " The Top500 supercomputer list. No Server Required - Jekyll & Amazon S3. Congrats to the Heroku team for officially serving 100,000 apps.
Bandwidth, latency and it's fundamental impact on the speed of the web. An overview of tools for measuring performance, uptime monitoring, real user monitoring and performance benchmarking. Competitive Benchmarking SpeedCurve. The network constraints and what makes the web slow? How to make your website faster.
These AMD EPYC processors have a number of advantages for SQL Server workloads, as I will explain in this article. This 14nm first-generation AMD EPYC 7551 processor has 32 cores and 64 threads, and it works in one or two-socket servers. This makes it a good choice for many SQL Server workloads, especially DW workloads.
Microsoft SQL Server I/O Basics Author: Bob Dorr, Microsoft SQL Server Escalation Published: December, 2004 SUMMARY: Learn the I/O requirements for Microsoft SQL Server database file operations. This will help you increase system performance and avoid I/O environment errors.
The HammerDB TPROC-C workload by design intended as CPU and memory intensive workload derived from TPC-C – so that we get to benchmark at maximum CPU performance at a much smaller database footprint. For TPC-C this meant enough available spindles to reduce I/O latency and for TPC-H enough bandwidth for data throughput.
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. Bottlenecks can occur, for example, if you have a sudden surge in traffic that your servers are not equipped to handle. What is Performance Testing?
Last time around we looked at the DeathStarBench suite of microservices-based benchmark applications and learned that microservices systems can be especially latency sensitive, and that hotspots can propagate through a microservices architecture in interesting ways. on end-to-end latency) and less than 0.15% on throughput.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. This server is spending about a third of its CPU cycles just checking the time! I've shared many posts about superpower observability tools, but often humble hacking is just as effective. 30.14% in the middle of the flame graph.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. This server is spending about a third of its CPU cycles just checking the time! I've shared many posts about superpower observability tools, but often humble hacking is just as effective. 30.14% in the middle of the flame graph.
This reduction in latency ensures that applications and websites provide a more rapid and responsive user experience. Reduced Resource Usage Optimizing resource-intensive queries and configurations can lead to a reduced burden on your server. A finely tuned database processes queries more efficiently, leading to swifter results.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content