This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
RabbitMQ can be deployed in distributed environments and includes monitoring tools through a built-in dashboard and CLI. Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency.
As businesses compete for customer loyalty, it’s critical to understand the difference between real-user monitoring and synthetic user monitoring. However, not all user monitoring systems are created equal. What is real user monitoring? Real-time monitoring of user application and service interactions.
Instead, they can ensure that services comport with the pre-established benchmarks. In what follows, we explore some of these best practices and guidance for implementing service-level objectives in your monitored environment. Latency is the time that it takes a request to be served. SLOs improve software quality. Reliability.
Quality gates are benchmarks in the software delivery lifecycle that define specific, measurable, and achievable success criteria a service must meet before moving to the next phase of the software delivery pipeline. For example, improving latency by as little as 0.1 latency is the number one reason consumers abandon mobile sites.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. This blog post lists the important database metrics to monitor. Effective monitoring of key performance indicators plays a crucial role in maintaining this optimal speed of operation.
In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking. Netflix runs dozens of stateful services on AWS under strict sub-millisecond tail-latency requirements, which brings unique challenges. Thursday?—?December
Configuring Grafana For our purposes, the Grafana datasource used in this PoC is also the Postgres data cluster that is generating the data to be monitored. pg_stat_monitor About pg_stat_monitor is a Query Performance Monitoring tool for PostgreSQL. A script executing a benchmarking run: #!/bin/bash
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. Additionally, it became easy to provide deep links to different monitoring and deployment systems in Edgar due to consistent tagging.
Testing and Validation Post-upgrade, its vital to conduct performance benchmarking to confirm that the new setup operates within acceptable parameters. Conducting load tests on the new MongoDB setup can help verify that it meets expected performance benchmarks. Improved Performance MongoDB 7.0 Upgrading to MongoDB 7.0 </p>
A monitoring tool like Percona Monitoring and Management (PMM) is a popular choice among open source options for effectively monitoring MySQL performance. In this blog, we will explore various MySQL KPIs that are basic and essential to track using monitoring tools like PMM.
Weve seen this across dozens of companies, and the teams that break out of this trap all adopt some version of Evaluation-Driven Development (EDD), where testing, monitoring, and evaluation drive every decision from the start. Why early observability (logging and monitoring) is crucial for diagnosing issues. How do we do so?
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31
In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking. Netflix runs dozens of stateful services on AWS under strict sub-millisecond tail-latency requirements, which brings unique challenges. Thursday?—?December
In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking. Netflix runs dozens of stateful services on AWS under strict sub-millisecond tail-latency requirements, which brings unique challenges. Thursday?—?December
Reading time 4 min It’s important for both technical and business teams to understand the different web performance monitoring options that are available as well as their various use cases and the benefits of each. Understanding Web Performance Monitoring Methodologies. Synthetic Monitoring. Real User Monitoring (RUM).
They can also bolster uptime and limit latency issues or potential downtimes. They’re your roadmap to linking cloud moves with real business outcomes, helping you monitor progress. You manage cost optimization in a multi-cloud world by monitoring costs, using the right tools, and constantly adjusting.
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Consistent performance matters just as much as low average latency.
You can then configure your monitoring tools to send you alerts – or even break the build, if you're testing in your staging environment – when your budgets are violated. INP logs the latency of all interactions throughout the entire page lifecycle. This is where real user monitoring (RUM) really shines.
To this vital function is workload automation which optimizes scheduling, execution, and monitoring processes for each individual task or process within cloud-based workflows. Additionally, the platform continuously monitors data through benchmarking functionalities providing valuable insights through its data analytics tools.
It's an overview of why front-end performance matter, how to monitor it and the challenges faced when building for an increasingly mobile world. Bandwidth, latency and it's fundamental impact on the speed of the web. Bandwidth, latency and it's fundamental impact on the speed of the web. Uptime Monitoring Pingdom.
Budgets are scaled to a benchmark network & device. Tools and CI systems help them monitor progress & prevent regressions. Deciding what benchmark to use for a performance budget is crucial. It simulates a link with a 400ms RTT and 400-600Kbps of throughput (plus latency variability and simulated packet loss).
scripts/tcl/maria/tprocc/maria_tprocc_run.tcl Comparing the results When running the 80 thread sysbench-tpcc workload, monitoring with HammerDB we can see the following output. Throughput: events/s (eps): 8162.5668 time elapsed: 300.0356s total number of events: 2449061 Latency (ms): min: 0.35 idle%-99.97 hammerdbcli auto./scripts/tcl/maria/tprocc/maria_tprocc_run.tcl
support for logging, monitoring, and observability. A recent performance benchmark completed by Intel and BlueData using the BigBench benchmarking kit has shown that the performance ratios for container-based Hadoop workloads on BlueData EPIC are equal to and in some cases, better than bare-metal Hadoop [7]. Performance.
The HammerDB TPROC-C workload by design intended as CPU and memory intensive workload derived from TPC-C – so that we get to benchmark at maximum CPU performance at a much smaller database footprint. For TPC-C this meant enough available spindles to reduce I/O latency and for TPC-H enough bandwidth for data throughput.
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. Unlike spike tests, scalability tests involve gradually increasing workload while monitoring the effects on performance. What is Performance Testing?
Last time around we looked at the DeathStarBench suite of microservices-based benchmark applications and learned that microservices systems can be especially latency sensitive, and that hotspots can propagate through a microservices architecture in interesting ways. on end-to-end latency) and less than 0.15% on throughput.
This reduction in latency ensures that applications and websites provide a more rapid and responsive user experience. Monitor Resource Utilization Monitoring and analyzing resource utilization in your MySQL database is crucial for maintaining optimal performance and preventing potential bottlenecks.
Our customers who deployed Availability Groups were now using servers for primary and secondary replicas with 12+ core sockets and flash storage SSD arrays providing microsecond to low millisecond latencies. This chart shows our scaled results using a OLTP workload derived from TPC benchmarks. The results we achieved were remarkable.
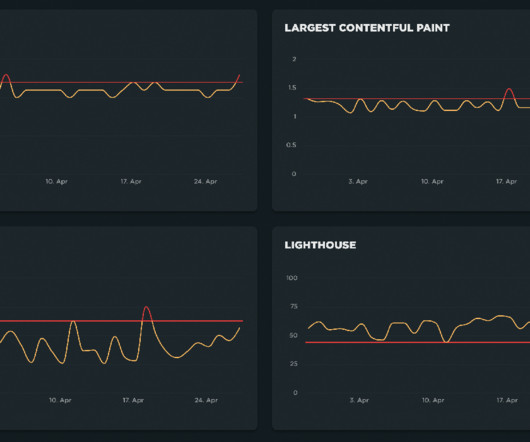
One free tool has become prominent in the space – Google Lighthouse – and one question often bubbles up: “I use Google Lighthouse for one-off snapshots of my site’s performance, so why do I need a performance monitoring solution?” But that’s exactly it – it’s a place to start.
These may be performance, high availability, operational cost, management, capacity planning, scalability, security, monitoring, etc. It efficiently manages read and write operations, optimizes data access, and minimizes contention, resulting in high throughput and low latency to ensure that applications perform at their best.
For anyone benchmarking MySQL with HammerDB it is important to understand the differences from sysbench workloads as HammerDB is targeted at a testing a different usage model from sysbench. maximum transition latency: Cannot determine or is not supported. . monitoring. HammerDB difference from Sysbench. perf special.
In an earlier blog post, we discussed Telltale , our health monitoring system. Telltale provides Edgar with latencybenchmarks that indicate if the individual trace’s latency is abnormal for this given service. At Netflix, we’ve answered that question with a suite of observability tools.
ScyllaDB offers significantly lower latency which allows you to process a high volume of data with minimal delay. In fact, according to ScyllaDB’s performance benchmark report, their 99.9 percentile latency is up to 11X better than Cassandra on AWS EC2 bare metal. So this type of performance has to come at a cost, right?
Each of the two vector units can issue one FMA instruction per cycle, assuming that there are enough independent accumulators to tolerate the 6-cycle dependent-operation latency. Using the minimum number of accumulator registers needed to tolerate the pipeline latency (12), the assembly code for the inner loop is: B1.8:
Each of the two vector units can issue one FMA instruction per cycle, assuming that there are enough independent accumulators to tolerate the 6-cycle dependent-operation latency. Using the minimum number of accumulator registers needed to tolerate the pipeline latency (12), the assembly code for the inner loop is: B1.8:
Moreover, each Edge WAF operates in isolation, unable to monitor traffic flowing through other CDNs. Benchmarks should be established to measure the latency introduced by the WAF, ensuring it stays within acceptable limits.â€Conclusionâ€In One solution is to employ a third-party WAF that operates independently of the CDNs.
The caching of data pages and grouping of log records helps remove much, if not all, of the command latency associated with a write operation. SQL Server 2005 contains the stalled I/O monitoring and detection.
It's like trying to sing in harmony when everyone is reading from a different hymn sheet.Moreover, each Edge WAF operates in isolation, unable to monitor traffic flowing through other CDNs. Each CDN has its own interpretation of WAF rules, which can lead to inconsistencies in security measures across the board.
Using this approach, we observed latencies ranging from 1 to 10 seconds, averaging 7.4 Overall, we hope you enjoyed the irony of: The extension used to monitor CPU usage causing CPU contention. The input to stdin is sent to the backend (i.e., We then exported the .har Explore the impact you can make with us!
This guide has been kindly supported by our friends at LogRocket , a service that combines frontend performance monitoring , session replay, and product analytics to help you build better customer experiences. Good for raising alarms and monitoring changes over time, not so good for understanding user experience. Vitaly Friedman.
Testing And Monitoring. To get a good first impression of how your competitors perform, you can use Chrome UX Report ( CrUX , a ready-made RUM data set, video introduction by Ilya Grigorik and detailed guide by Rick Viscomi) or Treo Sites , a RUM monitoring tool that is powered by Chrome UX Report. Getting Ready: Planning And Metrics.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content