

Implementing service-level objectives to improve software quality
Dynatrace
DECEMBER 27, 2022
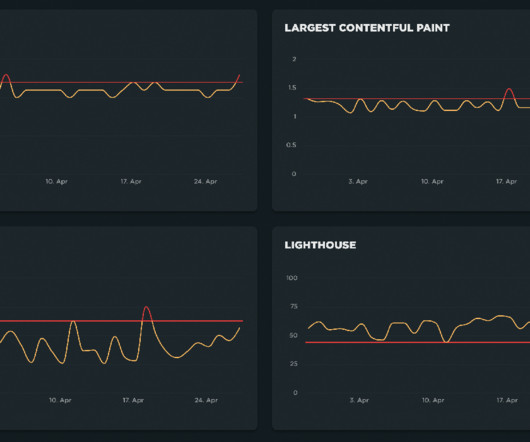
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. Instead, they can ensure that services comport with the pre-established benchmarks. This process includes benchmarking realistic SLO targets based on statistical and probabilistic analysis from Dynatrace.











































Let's personalize your content