This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ScaleGrid MySQL on Azure so you can see which provider offers the best throughput and latency performance. We measure latency in ms 95th percentile latency. During Read-Intensive Workloads, ScaleGrid manages to achieve up to 3 times higher throughput and averages 66% better latency compared to Azure Database.
This is the first time I have benchmarked it with a realistic example. Little’s Law and Why Latency Matters. In many cases, the assumption is that as long as throughput is high enough, the latency won’t be a problem. However, latency is often a key factor in why the throughput isn’t high enough.
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency. Apache Kafka uses a custom TCP/IP protocol for high throughput and low latency. Apache Kafka, designed for distributed event streaming, maintains low latency at scale.
Almost every time I present RSocket to an audience, there will be someone asking the question: "How does RSocket compare to gRPC?" " Today we are going to find out.
Compare Latency. On average, ScaleGrid achieves almost 30% lower latency over DigitalOcean for the same deployment configurations. MySQL DigitalOcean Performance Benchmark. In this benchmark, we compare equivalent plan sizes between ScaleGrid MySQL on DigitalOcean and DigitalOcean Managed Databases for MySQL. Throughput.
Instead, they can ensure that services comport with the pre-established benchmarks. Using data from Dynatrace and its SLO wizard , teams can easily benchmark meaningful, user-based reliability measurements and establish error budgets to implement SLOs that meet business objectives and drive greater DevOps automation. Reliability.
Compare Latency. lower latency compared to DigitalOcean for PostgreSQL. Now, let’s take a look at the throughput and latency performance of our comparison. Next, we are going to test and compare the latency performance between ScaleGrid and DigitalOcean for PostgreSQL. PostgreSQL DigitalOcean Latency Averages (ms).
We have run these benchmarks on the AWS EC2 instances and designed a custom dataset to make it as close as possible to real application use cases. We compare throughput, operations per second, and latency under different loads, namely the P90 and P99 percentiles.
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
ShuffleBench i s a benchmarking tool for evaluating the performance of modern stream processing frameworks. Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively. This significantly increases event latency.
In this blog post, we compare Azure Database for MySQL vs. ScaleGrid MySQL on Azure so you can see which provider offers the best throughput and latency performance. We measure latency in ms 95th percentile latency.
Quality gates are benchmarks in the software delivery lifecycle that define specific, measurable, and achievable success criteria a service must meet before moving to the next phase of the software delivery pipeline. For example, improving latency by as little as 0.1 latency is the number one reason consumers abandon mobile sites.
As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure. MySQL Performance Benchmark Configuration. MySQL on AWS Performance Test. Amazon RDS. Instance Type.
In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking. Netflix runs dozens of stateful services on AWS under strict sub-millisecond tail-latency requirements, which brings unique challenges.
Leveraging pgbench , which is a benchmarking utility that comes bundled with PostgreSQL, I will put the cluster through its paces by executing a series of DML operations. And now, execute the benchmark: -- execute the following on the coordinator node pgbench -c 20 -j 3 -T 60 -P 3 pgbench The results are not pretty.
In some cases, you will lack benchmarking capabilities. connectivity, access, user count, latency) of geographic regions. Because pre-production environments are used for testing before an application is released to end users, teams have no access to real-user data. RUM generates a lot of data. Synthetic monitoring drawbacks.
Querying the data While it is reasonable to create panels showing real-time load in order to explore better the types of queries that can be run against pg_stat_monitor, it is more practical to copy and query the data into tables after the benchmarking has completed its run. A script executing a benchmarking run: #!/bin/bash
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
Redis is an advanced key-value store. In fact, it is the number one key value store and eighth most popular database in the world. It has high throughput and runs from memory, but also has the ability to persist data on disk. Redis is a great caching solution for highly demanding applications, and there are […].
HammerDB doesn’t publish competitive database benchmarks, instead we always encourage people to be better informed by running their own. So over at Phoronix some database benchmarks were published showing PostgreSQL 12 Performance With AMD EPYC 7742 vs. Intel Xeon Platinum 8280 Benchmarks .
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. Using simple lookup indices in Cassandra gives us the ability to maintain acceptable read latencies while doing heavy writes.
DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads. We performed a standard benchmarking test using the sysbench tool to compare the performance of a DLV instance vs a standard RDS MySQL instance, as shared in the following section.
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
I have a lot of historical data using my ReadOnly benchmark (as described in some of the earliest entries in this blog [link] A read-only access pattern removes the need to understand and explain the many complexities associated with the “streaming stores” typically used in the STREAM benchmark (e.g., Stay tuned!
Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook , Cao et al., Or in the case of key-value stores, what you benchmark. So if you want to design a system that will offer good real-world performance, it’s really useful to have benchmarks that accurately represent real-world workloads.
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval.
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures. On MySQL, we saw a 1.5X
Testing and Validation Post-upgrade, its vital to conduct performance benchmarking to confirm that the new setup operates within acceptable parameters. Conducting load tests on the new MongoDB setup can help verify that it meets expected performance benchmarks. This helps prevent any disruptions or functionality issues post-upgrade.
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking. Netflix runs dozens of stateful services on AWS under strict sub-millisecond tail-latency requirements, which brings unique challenges.
In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking. Netflix runs dozens of stateful services on AWS under strict sub-millisecond tail-latency requirements, which brings unique challenges.
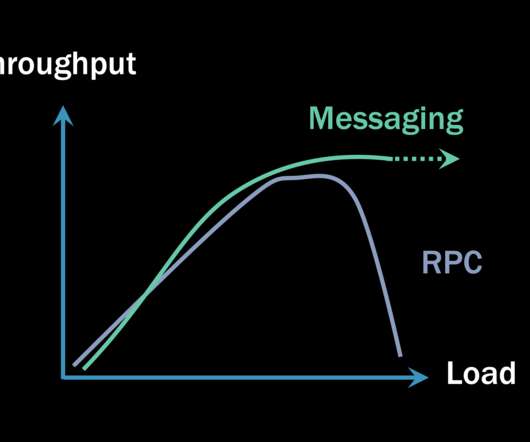
Some will claim that any type of RPC communication ends up being faster (meaning it has lower latency) than any equivalent invocation using asynchronous messaging. If you did such a benchmark, here’s an incomplete picture you might end up with: Graph of microbenchmark showing RPC is faster than messaging. Messaging doesn’t do that.
As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure. AWS is the #1 cloud provider for open-source database hosting, and the go-to cloud for MySQL deployments.
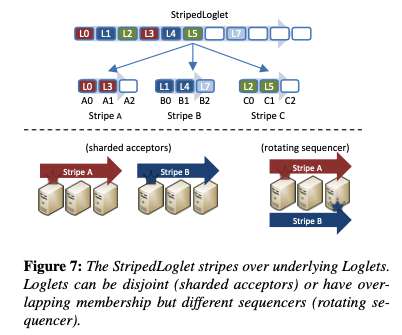
The initial version of Delos went into production after eight months using a ZooKeeper-backed Loglet implementation, and then four months later it was swapped out for a new custom-built NativeLoglet that gave a 10x improvement in end-to-end latency. For Facebook’s Delos, reconfiguration latencies of 10s of ms are ok.
To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It Building separate models for each of the benchmarks was required to get the correct asymptotic properties.
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 on CentOS 7, both of them spec’d with four vCPUs but with the second one (server B) having a tad over twice as much memory than the reference one (server A).
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. I love short benchmarks like this as I can disassemble the resulting binary and ensure that the compiled instructions match my expectations, and the compiler hasen't messed with it. ## 6. include <sys/time.h>
Indexing efficiency Monitoring indexing efficiency in MySQL involves analyzing query performance, using EXPLAIN statements, utilizing performance monitoring tools, reviewing error logs, performing regular index maintenance, and benchmarking/testing. This KPI is also directly related to Query Performance and helps improve it.
As part of our new support for ARM processors , we recently ran benchmarks on both Intel C7 and ARM c7g on AWS. The goal of these benchmarks was to both quantify performance differences between the two platforms and gain an understanding of their TCO. We used an in-house benchmark called voltdb-charglt.
The post Cross rack network latency in AWS appeared first on n0derunner. The bandwidth is 25GbE however, the response time between the hosts is so high that I need multiple streams to consume that bandwidth. Compared to my local on-prem lab I need many more streams to.
Let us take a look also the latency: Here the situation starts to be a little bit more complicated. MySQL Router is the one that has the higher latency no matter what. Looking at the latency, we can see that HAProxy gradually increased as expected, while ProxySQL and MySQL Router just went up from the 256 threads on.
This will be clearly visible in PostgreSQL performance benchmarks as a “ Sawtooth wave ” pattern observed by Vadim in his tests: As we can see, the throughput suddenly drops after every checkpoint due to heavy WAL writing and gradually picks up until the next checkpoint. But this comes with a considerable performance implication.
Benchmarking Cache Speed Memcached is optimized for high read and write loads, making it highly efficient for rapid data access in a basic key-value store. Redis’s support for pipelining in a Redis server can significantly reduce network latency by batching command executions, making it beneficial for write-heavy applications.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content