This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Tons of technologies emerge daily, promising capabilities that help you surpass your performance benchmarks. Knowing how the infrastructure is set up and how clusters operate and communicate are crucial. Building performant services and systems is at the core of every business.
Further, and by chance, iOS usage is strongly correlated with regions we generally find to have better infrastructure. What we really want to do, alongside capturing good benchmark- and more permanent data with WebPageTest, is interact with and inspect a site slightly more realtime. Network Link Conditioner. somewhere sensible.
Discovery and inventory First, a KSPM platform ideally identifies all Kubernetes resources including nodes, pods, namespaces, RBAC roles, network policies and configurations. It generates reports to assess cluster compliance posture for frameworks like DORA, CIS Benchmarks, or PCI-DSS. Heres a closer look at how KSPM tools work: 1.
Now let’s look at how we designed the tracing infrastructure that powers Edgar. Reconstructing a streaming session was a tedious and time consuming process that involved tracing all interactions (requests) between the Netflix app, our Content Delivery Network (CDN), and backend microservices.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. We’ve seen the IT infrastructure landscape evolve rapidly over the past few years. What is infrastructure monitoring? . Dynatrace news.
Five-nines availability: The ultimate benchmark of system availability. For organizations running their own on-premises infrastructure, these costs can be prohibitive. Instead, to speed up response times, applications are now processing most data at the network’s perimeter, closest to the data’s origin.
A significant feature of Chronicle Queue Enterprise is support for TCP replication across multiple servers to ensure the high availability of application infrastructure. This is the first time I have benchmarked it with a realistic example. Little’s Law and Why Latency Matters.
Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations. Performance and Benchmark Comparison When comparing RabbitMQ and Kafka, performance factors such as throughput, latency, and scalability play a critical role.
To function effectively, containers need to be able to communicate with each other and with network services. If containers are run with privileged flags, or if they receive details about host processes, they can easily become points of compromise for corporate networks. Network scanners. Why is container security tricky?
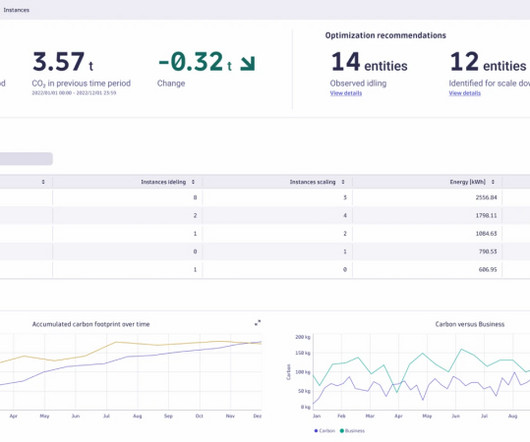
How Dynatrace tracks and mitigates its own IT carbon footprint Like many tech companies, Dynatrace is experiencing increased demand for its SaaS-based Dynatrace platform , which we host on cloud infrastructure. As we onboard more customers, the platform requires more infrastructure, leading to increased carbon emissions.
The core benefits of an AIOps-automated software analytics platform include the following: Infrastructure monitoring. Investigate network systems and application security incidents quickly for near-real-time remediation. Instantly analyze massive volumes of observability, security, and business data for precise, AI-powered insights.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking.
They collect data from multiple sources through real user monitoring , synthetic monitoring, network monitoring, and application performance monitoring systems. This includes monitoring components such as web servers, databases, application performance interfaces (APIs), content delivery networks, and third-party integrations.
DORA applies to more than 22,000 financial entities and ICT service providers operating within the EU and to the ICT infrastructure supporting them from outside the EU. Pillar 4: Managing ICT third-party risk Financial institutions rely on third-party vendors for various critical ICT services such as applications and cloud infrastructure.
The key information displayed on the standard Dynatrace Problems app and the Infrastructure and Operations App became the basis of their team’s remediation plan. Many businesses rely on third-party services, such as payment processors, content delivery networks (CDNs), and ticketing systems to get through their day-to-day operations.
Although IT teams are thorough in checking their code for any errors, an attacker can always discover a loophole to exploit and damage applications, infrastructure, and critical data. half of all corporate networks. Recently, the industry has seen an increase in attempted attacks on zero-day vulnerabilities.
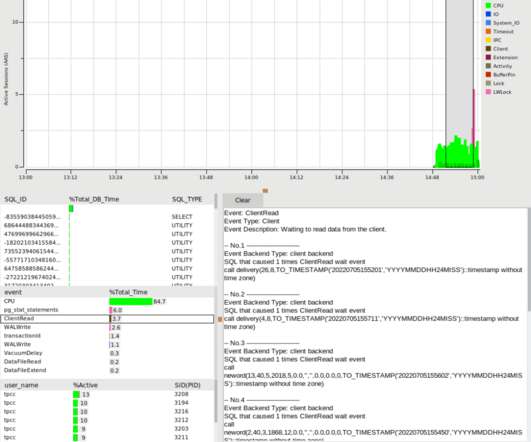
Python is a popular programming language, especially for beginners, and consequently we see it occurring in places where it just shouldn’t be used, such as database benchmarking. We use stored procedures because, as the introductory post shows, using single SQL statements turns our database benchmark into a network test).
As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure. No more network-based EBS, just blazing-fast local SSD. MySQL Performance Benchmark Configuration.
Netflix engineers run a series of tests and benchmarks to validate the device across multiple dimensions including compatibility of the device with the Netflix SDK, device performance, audio-video playback quality, license handling, encryption and security. The neural network (NN)-based agent uses a deep net with fully connected layers.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking.
Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target. In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking.
These new applications are a great way for enterprise companies to test out PostgreSQL before migrating their entire infrastructure. There is also a wide network of Oracle partners available to help you negotiate a discount , typically ranging from 15%-30%, though larger discounts of up to 40%-60% are available for larger accounts.
This article analyzes cloud workloads, delving into their forms, functions, and how they influence the cost and efficiency of your cloud infrastructure. Hybrid cloud environments that integrate on-premises infrastructure with cloud services. These include on-premises data centers which offer specific business benefits.
As such, fault tolerance is more expensive to implement because it requires dedicated infrastructure that completely mirrors the primary system. Components of high availability infrastructure Multiple copies of data Data redundancy helps prevent data loss due to hardware or software failures.
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. All modern browsers are fast, Chromium and Safari/WebKit included. position: sticky.
Setting up clear rules for managing your cloud infrastructure is key to keeping things from getting out of hand. Adopting Infrastructure as Code (IaaC) makes transitioning to a multi-cloud architecture more efficient, allowing streamlined setup processes. Scalegrid: Your Multi-Cloud Strategy Solution ScaleGrid.io
One initial, easy step to moving your SQL Server on-premises workloads to the cloud is using Azure VMs to run your SQL Server workloads in an infrastructure as a service (IaaS) scenario. You will still have to maintain your operating system, SQL Server and databases just like you would in an on-premises scenario.
In this case, we are not going to be talking about infrastructure services, such as a cloud computing platform like Microsoft Azure or a content distribution network like Akamai. And JavaScript can certainly make requests for additional network resources.
We constrain ourselves to a real-world baseline device + network configuration to measure progress. Budgets are scaled to a benchmarknetwork & device. Teams with this support are free to set performance budgets, do “bakeoffs” between competing approaches, and invest in performance infrastructure.
Though still not “profitable” by many benchmarks, it’s a lot closer to being so, perhaps in a big way.) That early decision was notable because whereas the GPL is applied if derivative work is distributed, the AGPL license applies both for distributed work and whenever end users interact with a program over a network.
It's time once again to update our priors regarding the global device and network situation. seconds on the target device and network profile, consuming 120KiB of critical path resources to become interactive, only 8KiB of which is script. What's changed since last year? and 75KiB of JavaScript. These are generous targets.
High availability architecture Two previously mentioned absolutes — no SPOF and foolproof failover — must apply across the following areas if an HA architecture is to be achieved: Infrastructure — This is the hardware that database systems rely on. there cannot be high availability.
SaaS businesses are built upon the simplicity of computing, storage, and networking they provide to their users. Once SLAs are established, you need to consistently monitor your SaaS business infrastructure along with web and mobile applications to make sure they meet the defined thresholds. Infrastructure.
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. Prepare the testing environment: Make sure your hardware and network configurations closely reflect real world conditions. What is Performance Testing?
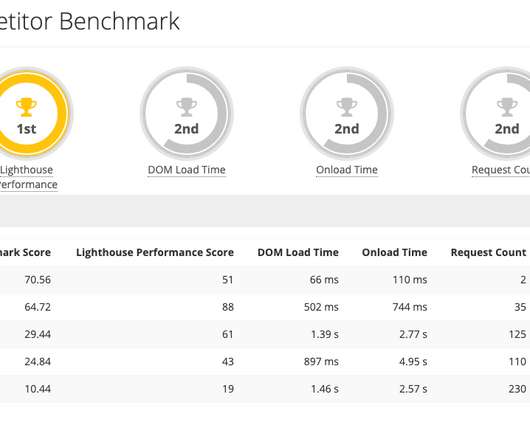
Can you test with 3G, 4G, or different networking connections? Competitive & Industry Benchmarking. With a Synthetic product, benchmarking a competitor’s site is as easy as testing your own site…you simply provide a URL. Benchmarking your performance against your competitors and industries.
an environment variable like network connectivity changed over time and is not aligned with the assumption with which test automation was built initially. Testsigma is one such test automation tool with a package of multiple useful features like cloud-based test case creation that does not require any infrastructure setup or investment.
Reduced network and device capacity correlate with other access challenges. Folks with powerful laptops, new iPhones, and low-latency networks are noticing, which is a very bad sign. Teams looking to grow past Level 1 develop (or uncover they already had) Real User Monitoring (" RUM data") infrastructure in previous cycles.
A solution should have packet capture abilities that provide low-level network scraping capability, ideally producing PCAP files for analysis. Establish performance benchmarks to help you identify when your applications perform as designed before impacting the user experience. Debugging is a must for effective application development.
Synthetic monitoring vendors provide a remote (often global) infrastructure that visits a website periodically and records the performance data for each run. Benchmark Against Competitors. Then, they can effectively benchmark their own performance against those key competitors over time. Synthetic Monitoring.
The spread of where consumers want to consume content, at home, at the office, at the gym, on a plane, at any time where there is connectivity, puts significant pressure on the network and performance monitoring teams for streaming brands. Load and stress-testing benchmark goals for the backend technological components.
Last time around we looked at the DeathStarBench suite of microservices-based benchmark applications and learned that microservices systems can be especially latency sensitive, and that hotspots can propagate through a microservices architecture in interesting ways. ASPLOS’19. Distributed tracing and instrumentation.
Also, load-balancing after membership changes must be both multi-threaded and pipelined to drive the network at maximum bandwidth. This measures how well the IMDG’s servers use multithreading to maximize network bandwidth during load-balancing, and it also evaluates failure detection and recovery algorithms. Please retry later.
Thanks to progress in networks and browsers (but not devices), a more generous global budget cap has emerged for sites constructed the "modern" way: ~100KiB of HTML/CSS/fonts and ~300-350KiB of JS (compressed) is the new rule-of-thumb limit for at least the next year or two. Modern network performance and availability.
One of the top players in web performance, Ilya is a web performance engineer at Google, co-chair of the W3C Web Performance Working Group , and author of High Performance Browser Networking. Barry is a professional software developer who has nearly two decades of industry experience developing and supporting software and infrastructure.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content