This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. How can IT teams deliver system availability under peak loads that will satisfy customers?
Introduction to Message Brokers Message brokers enable applications, services, and systems to communicate by acting as intermediaries between senders and receivers. This decoupling simplifies system architecture and supports scalability in distributed environments.
One, by researching on the Internet; Two, by developing small programs and benchmarking. They still will win for mission-critical or real-time systems, which need performance over these parameters. In Byteland they have a very strange monetary system. The legacy languages — be it ASM or C still rule in terms of performance.
To create a CPU core that can execute a large number of instructions in parallel, it is necessary to improve both the architecturewhich includes the overall CPU design and the instruction set architecture (ISA) designand the microarchitecture, which refers to the hardware design that optimizes instruction execution.
Limits of a lift-and-shift approach A traditional lift-and-shift approach, where teams migrate a monolithic application directly onto hardware hosted in the cloud, may seem like the logical first step toward application transformation. In fact, it can be difficult to make code changes that won’t disrupt the entire system.
Dynatrace OneAgent deployment and life-cycle management are already widely considered to be industry benchmarks for reliability and efficiency. The /opt directory is typically used for deployment of additional software running on the Unix system. Dynatrace news.
Oracle Database is a commercial, proprietary multi-model database management system produced by Oracle Corporation, and the largest relational database management system (RDBMS) in the world. Compare ease of use across compatibility, extensions, tuning, operating systems, languages and support providers. Compare Ease of Use.
HammerDB doesn’t publish competitive database benchmarks, instead we always encourage people to be better informed by running their own. So over at Phoronix some database benchmarks were published showing PostgreSQL 12 Performance With AMD EPYC 7742 vs. Intel Xeon Platinum 8280 Benchmarks . uname -a Linux ubuntu19 5.3.0-rc3-custom
Rather than listing the concepts, function calls, etc, available in Citus, which frankly is a bit boring, I’m going to explore scaling out a database system starting with a single host. And now, execute the benchmark: -- execute the following on the coordinator node pgbench -c 20 -j 3 -T 60 -P 3 pgbench The results are not pretty.
Verifying benchmark claims. Clearly, they're updating their systems far more frequently than they did on-premises, which changes the nature of engineering problems the team needs to prioritize. Verifying benchmark claims. I've noticed a troubling trend in vendor benchmarking claims over the past year.
For the rest of us, if you really need that extra performance (maybe what you get out-of-the-box or with minimal tuning is good enough for your use case) then you can upgrade hardware and/or pay for a commercial license of a tuned distributed (RHEL). A second takeaway is this: security has a cost! Measuring the kernel. Headline results.
Machine learning systems are stuck in a rut Barham & Isard, HotOS’19. In this paper we argue that systems for numerical computing are stuck in a local basin of performance and programmability. Take a simple example: it would be really nice if we could have named dimensions instead of always having to work with indices.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. Operating system Linux is the most common operating system for high-performance MySQL servers. Benchmark before you decide.
Furthermore, as hardware and compiler optimisations rapidly evolve, it is challenging even for a knowledgeable developer to keep up. The study is conducted using a suite of 7 real-world popular scientific applications, and two well-established benchmark suites: Miniaero solves the compressible Navier-Stokes equation. The applications.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Some disruption might occur, but it will be minimal. More in the following sub-section.)
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures. On MySQL, we saw a 1.5X
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval.
Understanding this DBaaS system might take some adjusting too similar just how traveling on cruises has its tempo which requires us to get used to optimally benefit from what it provides. The great thing about this is that it provides companies with an unprecedented level of freedom when configuring their system.
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
Indexing efficiency Monitoring indexing efficiency in MySQL involves analyzing query performance, using EXPLAIN statements, utilizing performance monitoring tools, reviewing error logs, performing regular index maintenance, and benchmarking/testing. This KPI is also directly related to Query Performance and helps improve it.
We’ll wrap it up by suggesting high availability open source solutions, and we’ll introduce you to support options for ensuring continuous high performance from your systems. A basic high availability database system provides failover (preferably automatic) from a primary database node to redundant nodes within a cluster.
Key metrics like throughput, request latency, and memory utilization are essential for assessing Redis health, with tools like the MONITOR command and Redis-benchmark for latency and throughput analysis and MEMORY USAGE/STATS commands for evaluating memory. It depends upon your application workload and its business logic.
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. All modern browsers are fast, Chromium and Safari/WebKit included. Media Session API.
Some opinions claim that “Benchmarks are meaningless”, “benchmarks are irrelevant” or “benchmarks are nothing like your real applications” However for others “Benchmarks matter,” as they “account for the processing architecture and speed, memory, storage subsystems and the database engine.”
The problem is that this system has a default libc that has been compiled without frame pointers, so any stack walking stops at the libc layer, producing a partial stack that's missing the application frames. This is pretty common and usually goes unnoticed as the flame graph looks ok at first glance. Just to name a couple of languages.
As part of our new support for ARM processors , we recently ran benchmarks on both Intel C7 and ARM c7g on AWS. The goal of these benchmarks was to both quantify performance differences between the two platforms and gain an understanding of their TCO. We used an in-house benchmark called voltdb-charglt.
Because recognizing if the workload is read intensive or write intensive will impact your hardware choices, database configuration as well as what techniques you can apply for performance optimization and scalability. Let’s examine the TPC-C Benchmark from this point of view, or more specifically its implementation in Sysbench.
Looking across a set of eight Java benchmarks, we find that only two of them are array dominated, the rest having between 40% to 75% of the heap footprint allocated to objects, the vast majority of which are small. Consider a B-Tree node from the B-tree Java benchmark: Uncompressed, it’s memory layout looks like (a) below. Evaluation.
Last week we saw the benefits of rethinking memory and pointer models at the hardware level when it came to object storage and compression ( Zippads ). The protections are hardware implemented and cannot be forged in software. And this all has to work for whole-system executions, not just the C-language portion of user processes.
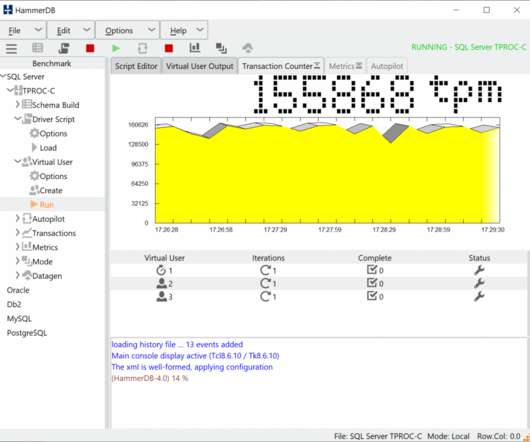
HammerDB is a software application for database benchmarking. It enables the user to measure database performance and make comparative judgements about database hardware and software. HammerDB has graphical and command line interfaces for the Windows and Linux operating systems. Why HammerDB was developed. HammerDB Licensing.
HammerDB is a load testing and benchmarking application for relational databases. On high-performance multi-core systems all the supported databases can return performance in the many millions of transactions per minute. Basic Benchmarking Concepts. To benchmark a database we introduce the concept of a Virtual User.
CLI tools The Cassandra systems were EC2 virtual machine (Xen) instances. As a Xen guest, this profile was gathered using perf(1) and the kernel's software cpu-clock soft interrupts, not the hardware NMI. Microbenchmark os::javaTimeMillis() on both systems. Running this on the two systems saw similar results.
This removes the burden of purchasing and maintaining your hardware, storage and networking infrastructure, while still giving you a very familiar experience with Windows and SQL Server itself. You will still have to maintain your operating system, SQL Server and databases just like you would in an on-premises scenario.
FlexFlow is also given a device topology graph describing all the available hardware devices and their interconnections. Hardware connections between devices are modelled as special communication devices which can execute communication tasks. FlexFlow is evaluated over six real-world DNN benchmarks on two different GPU clusters.
In a recent project comparing systems for MariaDB performance, a user had originally been using a tool called sysbench-tpcc to compare hardware platforms before migrating to HammerDB. This is a brief post to highlight the metrics to use to do the comparison using a separate hardware platform for illustration purposes.
Therefore, before we attempt to measure our database performance, we should know the system or cloud instance to be tested in detail. Benchmarking the target Two of the more popular database benchmarks for MySQL are HammerDB and sysbench. Operating System: Ubuntu 22.04 Operating System: Ubuntu 22.04
Hardware Optimizers” want to get the maximum utilization out of hardware. Telcos and Fortune 500 corporations used to spend years defining custom systems, down to the last cable. Private Clouds made of commodity hardware are perceived as the logical solution to this problem. The “Public Private Cloud” folks.
It will also use less power than a two-socket Intel server, with a lower hardware cost, and potentially lower licensing costs (for things like VMware). The initial reviews and benchmarks for these processors have been very impressive: AMD EPYC 7002 Series Rome Delivers a Knockout. TPC-H Benchmark Results with SQL Server 2017.
A recent performance benchmark completed by Intel and BlueData using the BigBench benchmarking kit has shown that the performance ratios for container-based Hadoop workloads on BlueData EPIC are equal to and in some cases, better than bare-metal Hadoop [7]. Performance.
Budgets are scaled to a benchmark network & device. Tools and CI systems help them monitor progress & prevent regressions. Deciding what benchmark to use for a performance budget is crucial. Some systems show median RTTs near ~100ms for 3G users. Performance budgets are set early in the life of the project.
Arguably, the most common beginning errors with database benchmarking is for a user to select a single point of utilisation (usually overconfigured) and then extrapolate conclusions about system performance from this single point. HammerDB v4.11 The profile ID chart will show performance for each individual profile.
It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. Hardware optimization : You need to ensure that the CPU, memory, and storage components meet the performance requirements of the database workload. What is PostgreSQL performance tuning?
This results in expedited query execution, reduced resource utilization, and more efficient exploitation of the available hardware resources. This not only enhances performance but also enables you to make more efficient use of your hardware resources, potentially resulting in cost savings on infrastructure.
Last time around we looked at the DeathStarBench suite of microservices-based benchmark applications and learned that microservices systems can be especially latency sensitive, and that hotspots can propagate through a microservices architecture in interesting ways. When available, it can use hardware level performance counters.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content