This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
RabbitMQ can be deployed in distributed environments and includes monitoring tools through a built-in dashboard and CLI. Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations. RabbitMQ ensures fast message delivery when queues are not overloaded.
Five-nines availability: The ultimate benchmark of system availability. Traditionally, teams achieve this high level of uptime using a combination of high-capacity hardware, system redundancy, and failover models. Integrate infrastructure monitoring on a single AIOps platform. But is five nines availability attainable?
Limits of a lift-and-shift approach A traditional lift-and-shift approach, where teams migrate a monolithic application directly onto hardware hosted in the cloud, may seem like the logical first step toward application transformation. Use SLAs, SLOs, and SLIs as performance benchmarks for newly migrated microservices.
Dynatrace OneAgent deployment and life-cycle management are already widely considered to be industry benchmarks for reliability and efficiency. Deployment performs the whole rollout, instrumentation, configuration, connection, and automatic detection of monitored entities in your environment.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. This blog post lists the important database metrics to monitor. Effective monitoring of key performance indicators plays a crucial role in maintaining this optimal speed of operation.
Verifying benchmark claims. I picked these examples because they aren't operations that show up in standard data warehousing benchmarks, yet are meaningful parts of customer workloads. Verifying benchmark claims. I've noticed a troubling trend in vendor benchmarking claims over the past year.
A monitoring tool like Percona Monitoring and Management (PMM) is a popular choice among open source options for effectively monitoring MySQL performance. In this blog, we will explore various MySQL KPIs that are basic and essential to track using monitoring tools like PMM.
Furthermore, as hardware and compiler optimisations rapidly evolve, it is challenging even for a knowledgeable developer to keep up. The authors develop a tool called FPSpy which they use to monitor the floating point operations of existing scientific applications. PARSEC is a set of benchmarks for multi-threaded programs.
These numbers should not be taken as a benchmark for your own site. You can see this by looking at the synthetic test result for Sears.com (again, available via our Industry Benchmarks ). In this recent test run from our Industry Page Speed Benchmarks , you can see that the Amazon home page ranks fastest in terms of Start Render.
Disclaimer : This blog post is meant to show a less-known problem but is not meant to be a serious benchmark. The percentage in degradation will vary depending on many factors {hardware, workload, number of tables, configuration, etc.}. Setup The setup consists of creating 10K tables with sysbench and adding 20 FKs to 20 tables.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. Failure detection : Monitoring mechanisms detect failures or issues that could lead to failures.
This type of database offers scalability with no downtime along with giving businesses control over what resources they use through customization capabilities such as choosing hardware infrastructure options or building security measures around it. These advantages come at an expense.
Because recognizing if the workload is read intensive or write intensive will impact your hardware choices, database configuration as well as what techniques you can apply for performance optimization and scalability. Let’s examine the TPC-C Benchmark from this point of view, or more specifically its implementation in Sysbench.
It was also a virtual machine that lacked low-level hardware profiling capabilities, so I wasn't able to do cycle analysis to confirm that the 10% was entirely frame pointer-based. Enterprise environments are monitored, continuously profiled, and analyzed on a regular basis, so this capability will indeed be put to use.
Some of the most important elements include: No single point of failure (SPOF): You must eliminate any SPOF in the database environment, including any potential for an SPOF in physical or virtual hardware. Failure detection: Monitoring mechanisms detect failures or issues that could lead to failures. there cannot be high availability.
This enables the user to compare and contrast performance across different benchmark scenarios. By clicking on the Metrics Display option, HammerDB will connect to the target database and start monitoring the performance, note that if the pg_active_session_history table is empty the viewer will report an error and refuse to start.
In a recent project comparing systems for MariaDB performance, a user had originally been using a tool called sysbench-tpcc to compare hardware platforms before migrating to HammerDB. This is a brief post to highlight the metrics to use to do the comparison using a separate hardware platform for illustration purposes. idle%-99.97
There are a couple of blog posts from Yves that describe and benchmark MySQL compression: Compression Options in MySQL (Part 1) Compression Options in MySQL (Part 2) Archive or purge old or non-used data: Some companies have to retain data for multiple years either for compliance or for business requirements.
support for logging, monitoring, and observability. A recent performance benchmark completed by Intel and BlueData using the BigBench benchmarking kit has shown that the performance ratios for container-based Hadoop workloads on BlueData EPIC are equal to and in some cases, better than bare-metal Hadoop [7]. Performance.
This results in expedited query execution, reduced resource utilization, and more efficient exploitation of the available hardware resources. This not only enhances performance but also enables you to make more efficient use of your hardware resources, potentially resulting in cost savings on infrastructure.
Key areas include: Configuration parameter tuning : This tuning involves altering variables such as memory allocation, disk I/O settings, and concurrent connections based on specific hardware and requirements. This not only results in cost savings by minimizing hardware requirements but also has the potential to decrease cloud expenses.
Budgets are scaled to a benchmark network & device. Tools and CI systems help them monitor progress & prevent regressions. Deciding what benchmark to use for a performance budget is crucial. Simulated packet loss and variable latency, however, can make benchmarking extremely difficult and slow. 400Kbps transfer.
When we released Always On Availability Groups in SQL Server 2012 as a new and powerful way to achieve high availability, hardware environments included NUMA machines with low-end multi-core processors and SATA and SAN drives for storage (some SSDs). As we moved towards SQL Server 2014, the pace of hardware accelerated.
A full understanding of why this is important requires some knowledge of the evolution of database hardware and software. The HammerDB TPROC-C workload by design intended as CPU and memory intensive workload derived from TPC-C – so that we get to benchmark at maximum CPU performance at a much smaller database footprint.
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. Unlike spike tests, scalability tests involve gradually increasing workload while monitoring the effects on performance. What is Performance Testing?
Last time around we looked at the DeathStarBench suite of microservices-based benchmark applications and learned that microservices systems can be especially latency sensitive, and that hotspots can propagate through a microservices architecture in interesting ways. When available, it can use hardware level performance counters.
Understanding DBaaS DBaaS cloud services allow users to use databases without configuring physical hardware and infrastructure or installing software. These may be performance, high availability, operational cost, management, capacity planning, scalability, security, monitoring, etc. Learn more here!
This means that multiple partitions can be processed simultaneously, making better use of available hardware resources and further enhancing query performance. Careful planning and continuous monitoring are crucial to facing these challenges and achieving optimal performance. Common choices include time-based or range-based values.
As is also the case this limitation is at the database level (especially the storage engine) rather than the hardware level. For anyone benchmarking MySQL with HammerDB it is important to understand the differences from sysbench workloads as HammerDB is targeted at a testing a different usage model from sysbench. monitoring.
These numbers should NOT be taken as a benchmark for your own site. Make sure everyone who touches a page understands the performance impact of what they do All the fancy performance monitoring tools in the world can't help you if you don't have a strong performance culture at your organization. I'll go into this more below.
I became the Sun UK local specialist in performance and hardware, and as Sun transitioned from a desktop workstation company to sell high end multiprocessor servers I was helping customers find and fix scalability problems. We had specializations in hardware, operating systems, databases, graphics, etc. that a lot of people used.
A close monitoring of the hardware enthusiast community, including many of the most respected hardware analysts and reviewers paints an even more dire picture about Intel in the server processor space. Despite all of this, Intel is not going to lose their entire server processor business any time soon.
These numbers should not be taken as a benchmark for your own site. Those businesses perhaps have more awareness of the importance of performance optimization, along with the resources to monitor and tackle performance issues. Pages need to be monitored consistently over time. How quickly do they show up?
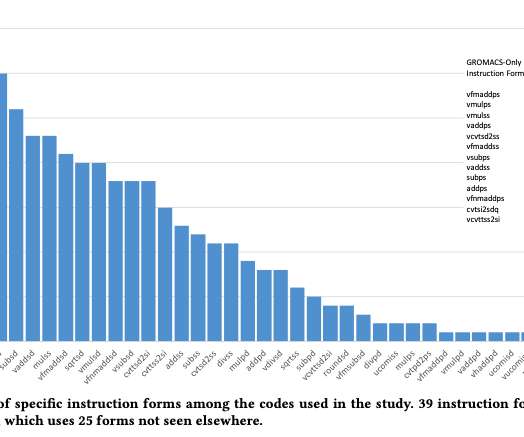
Hardware performance counter results for a simple benchmark code calling Intel’s optimized DGEMM implementation for this processor (from the Intel MKL library) show that about 20% of the dynamic instruction count consists of instructions that are not packed SIMD operations (i.e.,
Hardware performance counter results for a simple benchmark code calling Intel’s optimized DGEMM implementation for this processor (from the Intel MKL library) show that about 20% of the dynamic instruction count consists of instructions that are not packed SIMD operations (i.e., addl $1, %eax vfmadd213pd %zmm16, %zmm17, %zmm29.
ReadFile WriteFile ReadFileScatter WriteFileGather GetOverlappedResult For extended details on the 823 error, see Error message 823 may indicate hardware problems or system problems ( [link] i crosoft.com/default.aspx?scid=kb Contact your hardware manufacture for assistance.
Testing And Monitoring. To get a good first impression of how your competitors perform, you can use Chrome UX Report ( CrUX , a ready-made RUM data set, video introduction by Ilya Grigorik and detailed guide by Rick Viscomi) or Treo Sites , a RUM monitoring tool that is powered by Chrome UX Report. Getting Ready: Planning And Metrics.
This guide has been kindly supported by our friends at LogRocket , a service that combines frontend performance monitoring , session replay, and product analytics to help you build better customer experiences. Good for raising alarms and monitoring changes over time, not so good for understanding user experience. Vitaly Friedman.
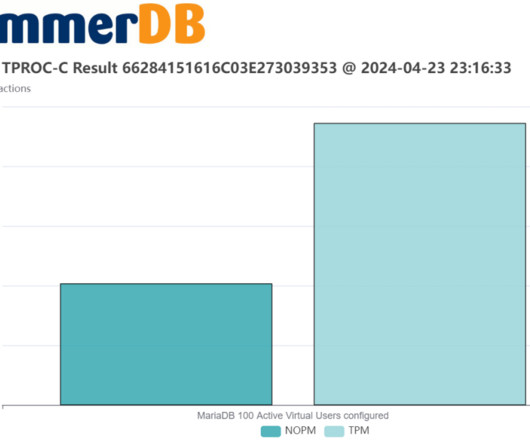
In this post, we revisit how to interpret transactional database performance metrics and give guidance on what levels of performance should be expected on up-to-date hardware and software in 2024. tpmC tpmC is the transactions per minute metric that is the measurement of the official TPC-C benchmark from the TPC-Council.
When it goes to production you would monitor it using the various internal tools like New Relic/Grafana, Kibana and if there is a regression you would fix it. We do a production deploy every Wednesday and monitor new relic, exception reports daily for any anomalies. New Relic is used to monitor the Application performance.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content