This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Several factors impact RabbitMQs responsiveness, including hardware specifications, network speed, available memory, and queue configurations. Performance and Benchmark Comparison When comparing RabbitMQ and Kafka, performance factors such as throughput, latency, and scalability play a critical role.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
This is a potential cause for concern for anyone who cares about metrics like Largest Contentful Paint, which measures the largest visual element on a page – including videos. Given that Google continues to dominate search usage, you should care about Vitals alongside the other metrics you should be tracking. More on that below.)
Limits of a lift-and-shift approach A traditional lift-and-shift approach, where teams migrate a monolithic application directly onto hardware hosted in the cloud, may seem like the logical first step toward application transformation. Use SLAs, SLOs, and SLIs as performance benchmarks for newly migrated microservices.
Five-nines availability: The ultimate benchmark of system availability. Traditionally, teams achieve this high level of uptime using a combination of high-capacity hardware, system redundancy, and failover models. But is five nines availability attainable? Each decimal point closer to 100 equals higher uptime.
One, by researching on the Internet; Two, by developing small programs and benchmarking. According to other comparisons [Google for 'Performance of Programming Languages'] spread over the net, they clearly outshine others in all speed benchmarks. The legacy languages — be it ASM or C still rule in terms of performance.
PostgreSQL Cluster One coordinator node citus-coord-01 Three worker nodes citus1 citus2 citus3 Hardware AWS Instance Ubuntu Server 20.04, SSD volume type 64-bit (x86) c5.xlarge And now, execute the benchmark: -- execute the following on the coordinator node pgbench -c 20 -j 3 -T 60 -P 3 pgbench The results are not pretty.
HammerDB doesn’t publish competitive database benchmarks, instead we always encourage people to be better informed by running their own. So over at Phoronix some database benchmarks were published showing PostgreSQL 12 Performance With AMD EPYC 7742 vs. Intel Xeon Platinum 8280 Benchmarks .
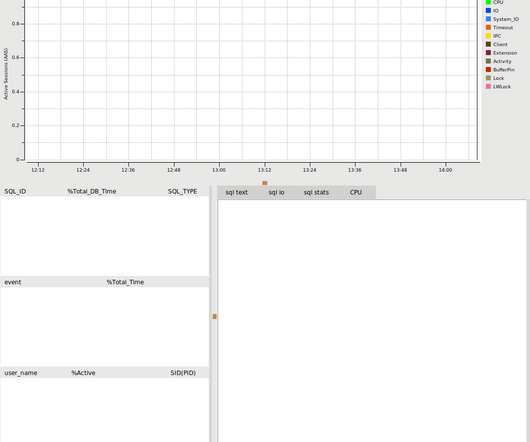
Introducing the PostgreSQL performance metrics viewer. HammerDB included a graphical performance metrics view for the Oracle database only. HammerDB includes the same functionality for PostgreSQL enabling the user to drill down on database metrics in real time. PostgreSQL Graphical Metrics. PostgreSQL Metrics treeview.
How does page bloat affect other metrics, such as Google's Core Web Vitals? These numbers should not be taken as a benchmark for your own site. Google's Core Web Vitals are a set of metrics that are intended to focus on measuring performance from a user-experience perspective. How does page bloat hurt your business?
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. Monitoring these metrics helps ensure data protection, minimize downtime, and ensure business continuity. This KPI is also directly related to Query Performance and helps improve it.
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures. port 5001 [ 4] local 127.0.0.1
The primary metric for memory bandwidth in multicore processors is that maximum sustained performance when using many cores. This metric is interesting because we don’t always have the luxury of parallelizing every application we run, and our operating systems almost always process each call (e.g., Details in the next blog entry.)
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval.
The scale of the effect can be deeply situational or hard to suss out without solid metrics. Since then, the metrics conversation has moved forward significantly, culminating in Core Web Vitals , reported via the Chrome User Experience Report to reflect the real-world experiences of users. Hardware Past As Performance Prologue.
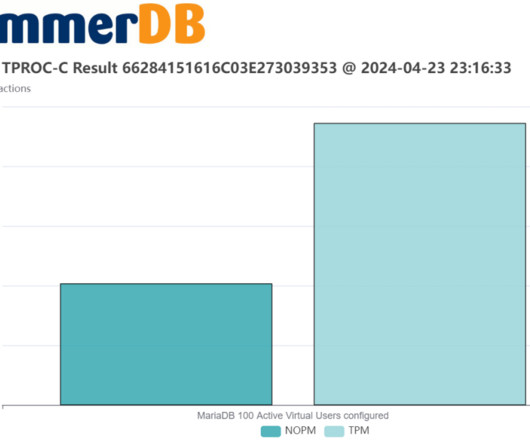
HammerDB is a software application for database benchmarking. It enables the user to measure database performance and make comparative judgements about database hardware and software. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking. The NOPM Metric.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. If a primary server fails, a backup server can take over and continue to serve requests.
Some opinions claim that “Benchmarks are meaningless”, “benchmarks are irrelevant” or “benchmarks are nothing like your real applications” However for others “Benchmarks matter,” as they “account for the processing architecture and speed, memory, storage subsystems and the database engine.”
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. Another window into this question is provided by the Web Confluence Metrics project.
In a recent project comparing systems for MariaDB performance, a user had originally been using a tool called sysbench-tpcc to compare hardware platforms before migrating to HammerDB. This is a brief post to highlight the metrics to use to do the comparison using a separate hardware platform for illustration purposes.
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
Budgets are scaled to a benchmark network & device. This helps support executive sponsors who then have meaningful metrics to point to in justifying the investments being made. Very rarely have we seen a team succeed that doesn’t set budgets, gather RUM metrics, and carry representative customer devices.
While throughput performance is important, especially in data-centers, single threaded performance remains a pivotal metric for a large swath of application domains (HPC, Finance etc.). She is currently a Principal Hardware Engineer at Microsoft in the Quantum Architecture Group.
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. Quantitative performance testing looks at metrics like response time while qualitative testing is concerned with scalability, stability, and interoperability.
This results in expedited query execution, reduced resource utilization, and more efficient exploitation of the available hardware resources. This not only enhances performance but also enables you to make more efficient use of your hardware resources, potentially resulting in cost savings on infrastructure.
For example HammerDB has not used tpmC terminology to report TPC-C based metrics instead using TPM and NOPM nomenclature. A full understanding of why this is important requires some knowledge of the evolution of database hardware and software. This was both expensive and time consuming to configure. I.e. if system A generated 1.5X
That's because video seems to have had a surge in growth, which should be a cause of concern for anyone who cares about metrics like Largest Contentful Paint, which measures the largest visual element on a page – including videos. These numbers should not be taken as a benchmark for your own site. More on that below.)
Understanding DBaaS DBaaS cloud services allow users to use databases without configuring physical hardware and infrastructure or installing software. Doing extensive benchmarks will be the subject of a future blog post. Percona Monitoring and Management (PMM) can also be used to gather metrics. Learn more here!
Example 1: Hardware failure (CPU board) Battery backup on the caching controller maintained the data. Important Always consult with your hardware manufacturer for proper stable media strategies. Mirroring can be implemented at a software or hardware level.
Getting Ready: Planning And Metrics. Getting Ready: Planning And Metrics. You need a business stakeholder buy-in, and to get it, you need to establish a case study, or a proof of concept using the Performance API on how speed benefits metrics and Key Performance Indicators ( KPIs ) they care about. Table Of Contents. Quick Wins.
In this post, we revisit how to interpret transactional database performance metrics and give guidance on what levels of performance should be expected on up-to-date hardware and software in 2024. tpmC tpmC is the transactions per minute metric that is the measurement of the official TPC-C benchmark from the TPC-Council.
An often overlooked aspect of database benchmarking is that it should be used to stress test databases on all new hardware environments before they enter production. Copy Code Copied Use a different Browser A corrected hardware error has occurred. Copy Code Copied Use a different Browser Faulting application name: wish90.exe,
We also generate quite a bit of internal application metrics using a home grown framework. The dedicated Security team runs automated security benchmark tests before every release. How are software and hardware upgrades rolled out? More details on this are in this blog post Debugging Performance Issues in Distributed Systems.
LogRocket tracks key metrics, incl. Getting Ready: Planning And Metrics Performance culture, Core Web Vitals, performance profiles, CrUX, Lighthouse, FID, TTI, CLS, devices. Getting Ready: Planning And Metrics. DOM complete, time to first byte, first input delay, client CPU and memory usage. Get a free trial of LogRocket today.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content