This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In some cases, you will lack benchmarking capabilities. For example, real-user monitoring metrics might reveal a user performance issue that you can then apply to synthetic testing to replicate the issue by exercising the same transaction across several different variables. RUM generates a lot of data. The bottom line?
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
A micro-benchmark suite, LEBench was then built around tee system calls responsible for most of the time spent in the kernel. On the exact same hardware, the benchmark suite is then used to test 36 Linux release versions from 3.0 It adds overhead to tests that exercise the kernel memory controller, even when cgroups aren’t being used.
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
Some opinions claim that “Benchmarks are meaningless”, “benchmarks are irrelevant” or “benchmarks are nothing like your real applications” However for others “Benchmarks matter,” as they “account for the processing architecture and speed, memory, storage subsystems and the database engine.”
Create a baseline to measure against Repeat this exercise periodically – perhaps monthly, or semi-annually, or after a deploy where you've made a number of performance improvements – and compare the correlation charts over time.
We track LEGO.com, along with a handful of other leading ecommerce sites, in our public-facing Retail Benchmarks dashboard , which I encourage you to check out. A couple of things worth noting: All of the sites in the leaderboard sites are pretty speedy, so this is NOT a name-and-shame exercise. Those are already big wins.
Instead, focus on understanding what the workloads exercise to help us determine how to best use them to aid our performance assessment. Benchmarking the target Two of the more popular database benchmarks for MySQL are HammerDB and sysbench. We will not concern ourselves with the raw throughput of workload. 4.22 %usr 38.40
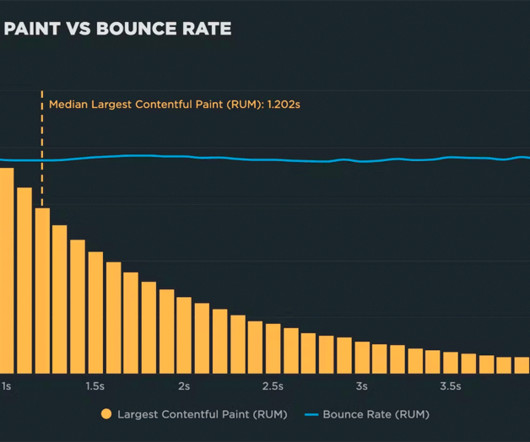
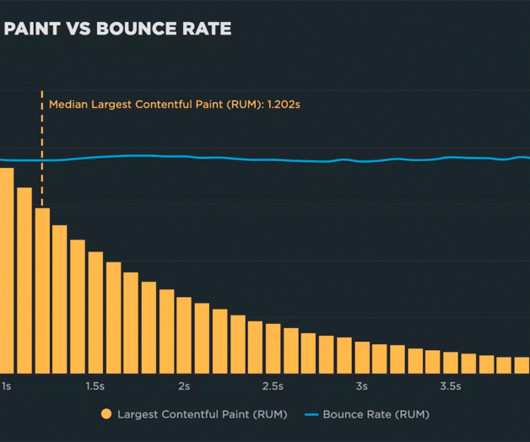
Google’s industry benchmarks from 2018 also provide a striking breakdown of how each second of loading affects bounce rates. With all of this in mind, I thought improving the speed of my own version of a slow site would be a fun exercise. billion if the site slowed down by just one second. Source: Google /SOASTA Research, 2018.
Create a baseline to measure against Repeat this exercise periodically – perhaps monthly, or semi-annually, or after a deploy where you've made a number of performance improvements – and compare the correlation charts over time.
In some sense it's a confidence-management exercise. Distinguishing Traits # Shipped to many OSes Tiny platform teams (<20 people or <10% of the total team) Little benchmark interest or focus No platform feature leadership No standards footprint Platform feature availability lags the underlying engine (e.g.,
The exercise seemed simple enough — just fix one item in the Colfax code and we should be finished. Published DGEMM benchmark results for the Xeon Phi 7250 processor ( [link] ) show maximum values of about 2100 GFLOPS when using all 68 cores (a very approximate estimate from a bar chart). Instead, we found puzzle after puzzle.
There was no deep goal — just a desire to see the maximum GFLOPS in action. The exercise seemed simple enough — just fix one item in the Colfax code and we should be finished. Instead, we found puzzle after puzzle.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content