This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This allows Kafka clusters to handle high-throughput workloads efficiently.
Compare Latency. On average, ScaleGrid achieves almost 30% lower latency over DigitalOcean for the same deployment configurations. MySQL DigitalOcean Performance Benchmark. In this benchmark, we compare equivalent plan sizes between ScaleGrid MySQL on DigitalOcean and DigitalOcean Managed Databases for MySQL. Throughput.
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
Such frameworks support software engineers in building highly scalable and efficient applications that process continuous data streams of massive volume. ShuffleBench i s a benchmarking tool for evaluating the performance of modern stream processing frameworks. This significantly increases event latency.
Quality gates are benchmarks in the software delivery lifecycle that define specific, measurable, and achievable success criteria a service must meet before moving to the next phase of the software delivery pipeline. For example, improving latency by as little as 0.1 latency is the number one reason consumers abandon mobile sites.
In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking. This talk explores the journey, learnings, and improvements to performance analysis, efficiency, reliability, and security. In 2019, Netflix moved thousands of container hosts to bare metal.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. These essential data points heavily influence both stability and efficiency within the system.
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. However, having a scalable stream processing platform doesn’t help much if you can’t store data in a cost efficient manner.
This separation aims to streamline transaction write logging, improving efficiency and consistency. DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads. Who can benefit from DLV? 2xlarge c5.2xlarge MySQL 8.0.31
We will also discuss related configuration variables to consider that can impact these KPIs, helping you gain a comprehensive understanding of your MySQL server’s performance and efficiency. Query performance Query performance is a key performance indicator (KPI) in MySQL, as it measures the efficiency and speed of query execution.
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval.
In this scenario, it is also crucial to be efficient in resource utilization and scaling with frugality. Let us take a look also the latency: Here the situation starts to be a little bit more complicated. MySQL Router is the one that has the higher latency no matter what. That allows it to go a bit further. and ProxySQL 6.6k.
Snapshots provide point-in-time captures of the dataset, which are efficient for recovery on startup. Memcached shines in scenarios where a simple, fast, and efficient caching solution is required without data persistence. Memory Efficiency Compared When it comes to memory efficiency, Redis and Memcached have different strengths.
In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking. Netflix runs dozens of stateful services on AWS under strict sub-millisecond tail-latency requirements, which brings unique challenges.
In this talk, we share how Netflix deploys systems to meet its demands, Ceph’s design for high availability, and results from our benchmarking. Netflix runs dozens of stateful services on AWS under strict sub-millisecond tail-latency requirements, which brings unique challenges.
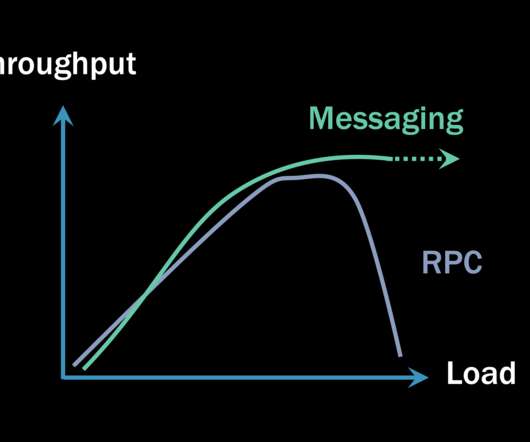
Some will claim that any type of RPC communication ends up being faster (meaning it has lower latency) than any equivalent invocation using asynchronous messaging. If you did such a benchmark, here’s an incomplete picture you might end up with: Graph of microbenchmark showing RPC is faster than messaging. Messaging doesn’t do that.
This article analyzes cloud workloads, delving into their forms, functions, and how they influence the cost and efficiency of your cloud infrastructure. The public cloud provides flexibility and cost efficiency through utilizing a provider’s resources. These include on-premises data centers which offer specific business benefits.
This will be clearly visible in PostgreSQL performance benchmarks as a “ Sawtooth wave ” pattern observed by Vadim in his tests: As we can see, the throughput suddenly drops after every checkpoint due to heavy WAL writing and gradually picks up until the next checkpoint. But this comes with a considerable performance implication.
Evaluation : How do we evaluate such systems, especially when outputs are qualitative, subjective, or hard to benchmark? Slow response/high cost : Optimize model usage or retrieval efficiency. Hallucinations and forgetting : How can we build reliable and consistent software using models that both forget and hallucinate?
They can also bolster uptime and limit latency issues or potential downtimes. Choosing the Right Cloud Services Choosing the right cloud services is crucial in developing an efficient multi cloud strategy.
Here’s some predictions I’m making: Jack Dongarra’s efforts to highlight the low efficiency of the HPCG benchmark as an issue will influence the next generation of supercomputer architectures to optimize for sparse matrix computations. In early January a related paper was published by Satoshi Matsuoka et. petaflops, which is 0.8%
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. All modern browsers are fast, Chromium and Safari/WebKit included. CSS Custom Paint.
In addition, such custom systems could only be benchmarked once they were deployed, so by the time multiple layers of management had each added a 50% safety margin to the initial SWAG , it was not unusual to see them running at 10% of capacity (but 150% of the lucky hardware salesman’s annual quota).
Budgets are scaled to a benchmark network & device. Deciding what benchmark to use for a performance budget is crucial. Contended, over-subscribed cells can make “fast” networks brutally slow, transport variance can make TCP much less efficient , and the bursty nature of web traffic works against us.
Once a new network does get rolled out, it takes years for carriers to optimize it to try and close in on the promised bandwidth and latencybenchmarks. In either case, the meaning is the same: as the efficiency of a resource increases, so does our consumption of that resource. We’re still nowhere close for 4G.
Google’s industry benchmarks from 2018 also provide a striking breakdown of how each second of loading affects bounce rates. Redirects are often pretty light in terms of the latency that they add to a website, but they are an easy first thing to check, and they can generally be removed with little effort.
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. Wait time: Sometimes called average latency, wait time refers the amount of time a request spends in a queue before it gets processed. What is Performance Testing?
In addition, such custom systems could only be benchmarked once they were deployed, so by the time multiple layers of management had each added a 50% safety margin to the initial SWAG , it was not unusual to see them running at 10% of capacity (but 150% of the lucky hardware salesman’s annual quota).
Enhanced Database Efficiency By adjusting configuration settings, you can markedly enhance the overall efficiency of your MySQL database. This results in expedited query execution, reduced resource utilization, and more efficient exploitation of the available hardware resources. Let’s explore these benefits in more detail.
Last time around we looked at the DeathStarBench suite of microservices-based benchmark applications and learned that microservices systems can be especially latency sensitive, and that hotspots can propagate through a microservices architecture in interesting ways. on end-to-end latency) and less than 0.15% on throughput.
If you or your company are able to generate a credible worldwide latency estimate in the higher percentiles for next year's update, please get in touch. But it won't be based on the sort of numbers that folks explicitly running speed tests see; those aren't real life.
It efficiently manages read and write operations, optimizes data access, and minimizes contention, resulting in high throughput and low latency to ensure that applications perform at their best. Doing extensive benchmarks will be the subject of a future blog post. Learn more here!
The Lighthouse Performance score is based on some of the most important performance metrics : First Contentful Paint, First Meaningful Paint, Speed Index, Time to Interactive, First CPU Idle, and Estimated Input Latency. Maintaining performant sites and applications requires you to efficiently gather and analyze data points over time.
For example, the IMDG must be able to efficiently create millions of objects in each server to make use of its huge storage capacity. Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. Testing Scale-Up Performance.
Edgar helps Netflix teams troubleshoot distributed systems efficiently with the help of a summarized presentation of request tracing, logs, analysis, and metadata. Telltale provides Edgar with latencybenchmarks that indicate if the individual trace’s latency is abnormal for this given service. What is Edgar?
Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. Lazy write (LRU and memory-pressure based) Checkpoint (recovery-interval based) Eager write (nonlogged I/O based) To efficiently flush writes to disk, WriteFileGather is used.
On your first try, you can use it as a benchmark for optimizations later. Server caches help lower the latency between a Frontend and Backend; since key-value databases are faster than traditional relational SQL databases, it will significantly increase an API’s response time. No one likes a white blank screen, especially your users.
Each of the two vector units can issue one FMA instruction per cycle, assuming that there are enough independent accumulators to tolerate the 6-cycle dependent-operation latency. Using the minimum number of accumulator registers needed to tolerate the pipeline latency (12), the assembly code for the inner loop is: B1.8:
Each of the two vector units can issue one FMA instruction per cycle, assuming that there are enough independent accumulators to tolerate the 6-cycle dependent-operation latency. Using the minimum number of accumulator registers needed to tolerate the pipeline latency (12), the assembly code for the inner loop is: B1.8:
KB boundaries efficiently. Although SQL Server tries to use the log space as efficiently as possible, certain application patterns cause the log-block fill percentages to remain small. This creates 8?KB
Using this approach, we observed latencies ranging from 1 to 10 seconds, averaging 7.4 To efficiently utilize our compute resources, Titus employs a CPU oversubscription feature , meaning the combined virtual CPUs allocated to containers exceed the number of available physical CPUs on a Titus agent. We then exported the .har
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Designed for the modern web, it responds to actual congestion, rather than packet loss like TCP does, it is significantly faster , with higher throughput and lower latency — and the algorithm works differently.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Designed for the modern web, it responds to actual congestion, rather than packet loss like TCP does, it is significantly faster , with higher throughput and lower latency — and the algorithm works differently.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content