This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As a result, organizations are investing in DevOps automation to meet the need for faster, more reliable innovation. Automation is a crucial aspect of achieving DevOps excellence. But according to the 2023 DevOps Automation Pulse , only 56% of end-to-end DevOps processes are automated.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. Instead, they can ensure that services comport with the pre-established benchmarks. SLOs enable DevOps teams to predict problems before they occur and especially before they affect customer experience.
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
With the increasing adoption of agile software development, DevOps , progressive continuous delivery, and Site Reliability Engineering (SRE) practices, many companies are aiming to deliver better software faster and more safely while keeping up with customer demands. Accelerate DevOps and Scale SRE with Service Level Objectives (SLOs).
Document and benchmark existing applications, processes, and services. Similarly, you may need to further develop DevOps and DevSecOps practices to ensure the healthy and proper lifecycles of an application modernization strategy. It’s important to create a baseline of metrics in an application modernization strategy.
In a recent webinar , Saif Gunja – director of DevOps product marketing at Dynatrace – sat down with three SRE panelists to discuss the standout findings and where they see the future of SRE. More than half (54%) of respondents reported that too many metrics made finding the relevant ones difficult.
Many good security tools provide that function, and benchmarks from the Center for Internet Security (CIS) are clear and prescriptive. Some SCA and SAST vendors have automated their products to align with the fast pace of modern DevOps teams, but many are still slow and cumbersome. Why is container security tricky? Remove privileges.
65% of businesses report that 40% of their customers now engage with them through mobile devices , and 70% of digital businesses will require IT and Ops to report digital metrics by 2025. First, the company uses synthetic monitoring to develop user experience benchmarks and determine if applications are performing within expected thresholds.
This public cloud management discipline provides IT, DevOps , CloudOps, finance, and business teams with continuous cost optimization tools and accurate accounting of cloud resources. Additionally, include benchmarks for stakeholders and best practices that support the anticipated growth of the organization as a whole.
APM solutions track key software application performance metrics using monitoring software and telemetry data. These solutions provide performance metrics for applications, with specific insights into the statistics, such as the number of transactions processed by the application or the response time to process such transactions.
Quality gates are benchmarks in the software delivery lifecycle that define specific, measurable, and achievable success criteria a service must meet before moving to the next phase of the software delivery pipeline. Enforcing benchmarks in real time. What are quality gates?
The framework does an excellent job at providing a freely available knowledge base that serves as a one-stop shop for modern lean-agile practices and DevOps. That’s why I’m so excited to see Flow Metrics added to the latest SAFe iteration. His Flow Framework® provides five metrics that can be used to measure different aspects of flow.
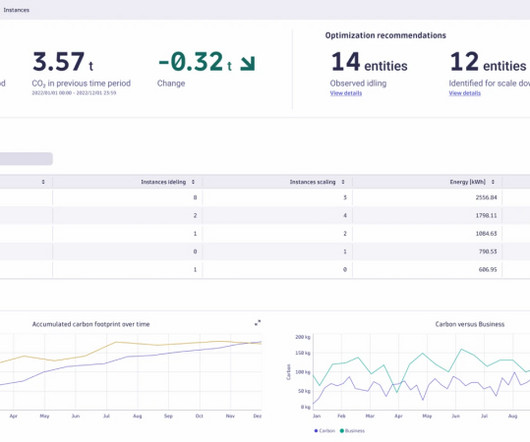
The app’s advanced algorithms and real-time data analytics translate utilization metrics into their CO2 equivalent (CO2e). These metrics include CPU, memory, disk, and network I/O. Using Carbon Impact, we can now implement efficiency measures driven by the app’s benchmarks and recommendations.
Five-nines availability: The ultimate benchmark of system availability. Include metrics, event logs, distributed traces, metadata, user experience data, and telemetry data from open source technologies and cloud platforms. But is five nines availability attainable? Each decimal point closer to 100 equals higher uptime.
Building on the gains of Agile and DevOps, VSM takes a systematic approach to the flow of business value across the complex software delivery process from customer request to delivery and back through the all-important feedback loop for continuous improvement. And is it actually improving how we operate and innovate?
Teams I've consulted are too often wrenched between celebration over "the big rewrite" launch and the morning-after realisation that the new stack is tanking business metrics. Competent managers will begin to look for more general "industry standard" baseline metrics to report against their data. Photo by Jay Heike.
” Here are additional metrics used to determine the reliability of a database, make adjustments that minimize downtime, and set benchmarks for meeting business continuity requirements. Unlike targeted testing of traditional DevOps procedures, chaos engineering is widespread throughout the entire system.
There are 200 Engineers(DevOps/OPS/QA/Developers/…), the rest are sales, marketing, support, product management, HR, etc. It's a big team, we have Product managers, UX team, DevOps, scrum teams, architects, engineers performing various roles. Convert heavily used flows from strongly consistent to eventually consistent.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content