This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To create a CPU core that can execute a large number of instructions in parallel, it is necessary to improve both the architecturewhich includes the overall CPU design and the instruction set architecture (ISA) designand the microarchitecture, which refers to the hardware design that optimizes instruction execution.
Many good security tools provide that function, and benchmarks from the Center for Internet Security (CIS) are clear and prescriptive. These products see systems from the “outside” perspective—which is to say, the attacker’s perspective. Harden the host operatingsystem. Why is container security tricky?
This metric is interesting because we don’t always have the luxury of parallelizing every application we run, and our operatingsystems almost always process each call (e.g., GHz, 1530 GB/s peak BW from 6 HBM stacks), I see single-thread sustained memory bandwidth of 304 GB/s on the ReadOnly benchmark used here.
Key metrics like throughput, request latency, and memory utilization are essential for assessing Redis health, with tools like the MONITOR command and Redis-benchmark for latency and throughput analysis and MEMORY USAGE/STATS commands for evaluating memory. offers the Software Watchdog specifically designed for this purpose.
This creates a whole new set of challenges that traditional software development approaches simply weren’t designed to handle. When your system is both ingesting messy real-world data AND producing nondeterministic outputs, you need a different approach. Iteration : We know we need to experiment with and iterate on these system.
While many of us, designers and developers, are likely to have a relatively new mobile phone in our pockets, a vast majority of our customers isn’t quite like us. A performance benchmark Lighthouse is well-known. And to ensure the quality of a product, we always need to test — on a number of devices, and in a number of conditions.
Some opinions claim that “Benchmarks are meaningless”, “benchmarks are irrelevant” or “benchmarks are nothing like your real applications” However for others “Benchmarks matter,” as they “account for the processing architecture and speed, memory, storage subsystems and the database engine.”
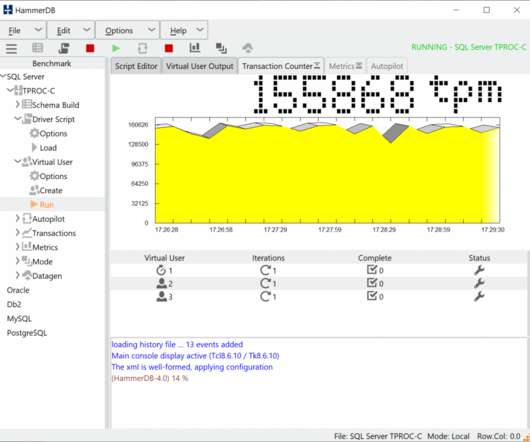
HammerDB is a load testing and benchmarking application for relational databases. On high-performance multi-core systems all the supported databases can return performance in the many millions of transactions per minute. Basic Benchmarking Concepts. To benchmark a database we introduce the concept of a Virtual User.
HammerDB is a software application for database benchmarking. HammerDB has graphical and command line interfaces for the Windows and Linux operatingsystems. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking. Why HammerDB was developed.
The PostgreSQL buffer is called shared_buffer which is the most effective tunable parameter for most operatingsystems. It’s low because certain machines and operatingsystems do not support higher values. Plus another recent post on benchmarks: Tuning PostgreSQL for sysbench-tpcc. wal_buffers. Related posts.
The presentation discusses a family of simple performance models that I developed over the last 20 years — originally in support of processor and systemdesign at SGI (1996-1999), IBM (1999-2005), and AMD (2006-2008), but more recently in support of system procurements at The Texas Advanced Computing Center (TACC) (2009-present).
High availability storage options within the context of cloud computing involve highly adaptable storage solutions specifically designed for storing vast amounts of data while providing easy access to it. Utilizing cloud platforms is especially useful in areas like machine learning and artificial intelligence research.
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
One of the important attributes of their design was easy and rapid deployment across an existing fleet. Looking across a set of eight Java benchmarks, we find that only two of them are array dominated, the rest having between 40% to 75% of the heap footprint allocated to objects, the vast majority of which are small. Evaluation.
You will still have to maintain your operatingsystem, SQL Server and databases just like you would in an on-premises scenario. Microsoft currently has eight main types of virtual machines designed for different types of workloads. Azure VM Types and Series.
The project consisted of upgrading the shop software to our own open-source system and redoing the shop’s front end from scratch. The design was made by a design and UX agency that also handled the HTML prototype (based on Bootstrap 4). Today, the website is much faster and ranks highly in various showcases and benchmarks.
This list guides you on the areas to test, the browsers, versions, operatingsystems to consider, the benchmarks to meet, as well as time and budget allocation. Perform all the design and functionality tests on Chrome first in order to have a better picture of how the application is intended to behave in front of the end-user.
This metric is interesting because we don’t always have the luxury of parallelizing every application we run, and our operatingsystems almost always process each call (e.g., GHz, 1530 GB/s peak BW from 6 HBM stacks), I see single-thread sustained memory bandwidth of 304 GB/s on the ReadOnly benchmark used here.
on Myths and Legends of High Performance Computing — it’s a somewhat light-hearted look at some of the same issues by the leader of the team that built the Fugaku system I mention below. HPCG is led by Japan’s RIKEN Fugaku system at 16 petaflops, which is 3% of it’s peak capacity. petaflops, which is 0.8% of peak capacity.
The presentation discusses a family of simple performance models that I developed over the last 20 years — originally in support of processor and systemdesign at SGI (1996-1999), IBM (1999-2005), and AMD (2006-2008), but more recently in support of system procurements at The Texas Advanced Computing Center (TACC) (2009-present).
Schema design: Evaluating the database schema design and making adjustments such as partitioning large tables, eliminating redundant data, and denormalizing tables for frequently accessed information can improve performance. It’s low because certain machines and operatingsystems do not support higher values.
We don’t even need a moment to gather which operatingsystem is the most used one. The older devices also have different screen resolutions which mean several features have to be categorically designed for them. Such information helps us design experiences for a higher retention rate. Which device brand do they use?
RPA Features to Look For While your systems utilize various operatingsystems, you probably use Windows to interface with most. Windows compatibility is the most useful requirement in RPA functionality, as that gives you access to a wide variety of other systems.
It ranks the world’s 500 most powerful supercomputers based on their performance as measured by the Linpack benchmark. This is vividly reflected in the design on the Titan supercomputer , which is still among the world’s top 10 most powerful supercomputers (as of the November 2018 Top500 list). You may have heard of the Top500 list.
This article Threads Done Right… With Tcl gives an excellent overview of these capabilities and it should be clear that to build a scalable benchmarking tool this thread performance and scalability is key. Virtual Users within HammerDB are operatingsystem threads. You can download and compile TCL/TK 8.6 Virtual Users.
Manual affinity instructs SQL Server to set the worker’s CPU affinity to only the CPU designated for the scheduler. The O perating System is instructed to only schedule the worker on the specific CPU. When manual affinity is used both online and offline schedulers are created.
With its support for MySQL and PostgreSQL, and its automated replication and backup capabilities, it’s designed to deliver high performance, scalability, and availability to meet the needs of mission-critical applications. This eliminates the need for complex or scripted backup procedures and designated backup windows.
Well, performance comparisons aren’t so easy since the AppFabric license agreement states: “You may not disclose the results of any benchmark tests of the software to any third party without Microsoft’s prior written approval.” A Few Words on Design Philosophy: Keep It Simple. In Summary: Design for Ease of Use and High Performance.
SQL Server always checks I/O completion status for any operatingsystem error conditions and proper data transfer size and then handles errors appropriately. Torn pages generally arise after system outages where the subsystem does not complete the entire 8-KB I/O request. This utility is located on the Microsoft Web site.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., A typical architecture diagram for one of these services looks like this: Suitably armed with a set of benchmark microservices applications, the investigation can begin! ASPLOS’19.
Another big jump, but now it was my job to run benchmarks in the lab, and write white papers that explained the new products to the world, as they were launched. I was mostly coding in C, tuning FORTRAN, and when I needed to do a lot of data analysis of benchmark results used the S-PLUS statistics language, that is the predecessor to R.
With new innovations come new terms, designs, and algorithms. This is different from the reference count design that was used in SQL Server 7.0 and 2000.
To help our customers manage ongoing data explosion, we have designed many of the core components over the last few years. I mean that as your scale grows then design patterns and strategies that used to work 2 years ago and allowed you to go from defensive to offensive positioning may buckle under pressure or becomes cost-prohibitive.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content