This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ScaleGrid MySQL on Azure so you can see which provider offers the best throughput and latency performance. We measure latency in ms 95th percentile latency. During Read-Intensive Workloads, ScaleGrid manages to achieve up to 3 times higher throughput and averages 66% better latency compared to Azure Database.
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing.
We have run these benchmarks on the AWS EC2 instances and designed a custom dataset to make it as close as possible to real application use cases. We compare throughput, operations per second, and latency under different loads, namely the P90 and P99 percentiles.
ShuffleBench i s a benchmarking tool for evaluating the performance of modern stream processing frameworks. Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively. We designed experimental scenarios inspired by chaos engineering.
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
This entertaining romp through the tech stack serves as an introduction to how we think about and design systems, the Netflix approach to operational challenges, and how other organizations can apply our thought processes and technologies. In order to maintain performance, benchmarking is a vital part of our system’s lifecycle.
Leveraging pgbench , which is a benchmarking utility that comes bundled with PostgreSQL, I will put the cluster through its paces by executing a series of DML operations. And now, execute the benchmark: -- execute the following on the coordinator node pgbench -c 20 -j 3 -T 60 -P 3 pgbench The results are not pretty.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
Now let’s look at how we designed the tracing infrastructure that powers Edgar. If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls.
Querying the data While it is reasonable to create panels showing real-time load in order to explore better the types of queries that can be run against pg_stat_monitor, it is more practical to copy and query the data into tables after the benchmarking has completed its run. A script executing a benchmarking run: #!/bin/bash
A Dedicated Log Volume (DLV) is a specialized storage volume designed to house database transaction logs separately from the volume containing the database tables. DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads.
I have a lot of historical data using my ReadOnly benchmark (as described in some of the earliest entries in this blog [link] A read-only access pattern removes the need to understand and explain the many complexities associated with the “streaming stores” typically used in the STREAM benchmark (e.g., Stay tuned!
This entertaining romp through the tech stack serves as an introduction to how we think about and design systems, the Netflix approach to operational challenges, and how other organizations can apply our thought processes and technologies. In order to maintain performance, benchmarking is a vital part of our system’s lifecycle.
This entertaining romp through the tech stack serves as an introduction to how we think about and design systems, the Netflix approach to operational challenges, and how other organizations can apply our thought processes and technologies. In order to maintain performance, benchmarking is a vital part of our system’s lifecycle.
Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook , Cao et al., Or in the case of key-value stores, what you benchmark. So if you want to design a system that will offer good real-world performance, it’s really useful to have benchmarks that accurately represent real-world workloads.
Understanding MongoDB End of Life (EOL) Policies MongoDB End of Life (EOL) policies are designed to provide users with a clear roadmap of each MongoDB versions lifecycle. Testing and Validation Post-upgrade, its vital to conduct performance benchmarking to confirm that the new setup operates within acceptable parameters.
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures. On MySQL, we saw a 1.5X
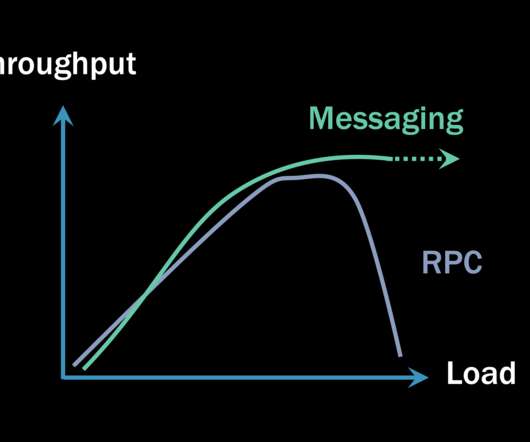
Some will claim that any type of RPC communication ends up being faster (meaning it has lower latency) than any equivalent invocation using asynchronous messaging. If you did such a benchmark, here’s an incomplete picture you might end up with: Graph of microbenchmark showing RPC is faster than messaging. Messaging doesn’t do that.
This creates a whole new set of challenges that traditional software development approaches simply weren’t designed to handle. With the advent of generative AI, therell be significant opportunities for product managers, designers, executives, and more traditional software engineers to contribute to and build AI-powered software.
When designing an architecture, many components need to be considered before deciding on the best solution. Let us take a look also the latency: Here the situation starts to be a little bit more complicated. MySQL Router is the one that has the higher latency no matter what. That allows it to go a bit further. and ProxySQL 6.6k.
Redis Data Types and Structures The design of Redis’s data structures emphasizes versatility. It is designed to cache plain text values, offering fast read and write access to frequently accessed data. Memcached’s primary strength lies in its simplicity. Global Reach and Cloud Integration ScaleGrid.io
The presentation discusses a family of simple performance models that I developed over the last 20 years — originally in support of processor and system design at SGI (1996-1999), IBM (1999-2005), and AMD (2006-2008), but more recently in support of system procurements at The Texas Advanced Computing Center (TACC) (2009-present).
This will be clearly visible in PostgreSQL performance benchmarks as a “ Sawtooth wave ” pattern observed by Vadim in his tests: As we can see, the throughput suddenly drops after every checkpoint due to heavy WAL writing and gradually picks up until the next checkpoint. But this comes with a considerable performance implication.
Each bare-metal instance is in a separate rack by design (for fault tolerance). The post Cross rack network latency in AWS appeared first on n0derunner. The bandwidth is 25GbE however, the response time between the hosts is so high that I need multiple streams to consume that bandwidth.
Here’s some predictions I’m making: Jack Dongarra’s efforts to highlight the low efficiency of the HPCG benchmark as an issue will influence the next generation of supercomputer architectures to optimize for sparse matrix computations. In early January a related paper was published by Satoshi Matsuoka et. petaflops, which is 0.8%
use the TPC-H benchmark to assess Redshift, Redshift Spectrum, Athena, Presto, Hive, and Vertica to find out what works best and the trade-offs involved. The design space. in the TPC-H Benchmark Standard for details of the queries). On Athena, Q2 timed out after an hour, and Q8, Q9 and Q21 failed after exhausting resources.
They can also bolster uptime and limit latency issues or potential downtimes. Establishing clear service-level agreements is key as they outline specific responsibilities and performance benchmarks expected from cloud service providers during disaster recovery scenarios. Scalegrid: Your Multi-Cloud Strategy Solution ScaleGrid.io
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. For example, an area where Apple is absolutely killing it is in mobile CPU design.
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Consistent performance matters just as much as low average latency.
High availability storage options within the context of cloud computing involve highly adaptable storage solutions specifically designed for storing vast amounts of data while providing easy access to it. Storage is a critical aspect to consider when working with cloud workloads.
The presentation discusses a family of simple performance models that I developed over the last 20 years — originally in support of processor and system design at SGI (1996-1999), IBM (1999-2005), and AMD (2006-2008), but more recently in support of system procurements at The Texas Advanced Computing Center (TACC) (2009-present).
There was an excellent first benchmarking report of the Cluster GPU Instances by the folks at Cycle Computing - " A Couple More Nails in the Coffin of the Private Compute Cluster " The Top500 supercomputer list. a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications. Recent Entries.
Bandwidth, latency and it's fundamental impact on the speed of the web. An overview of tools for measuring performance, uptime monitoring, real user monitoring and performance benchmarking. Competitive Benchmarking SpeedCurve. The network constraints and what makes the web slow? How to make your website faster. References.
These systems were designed to have a lifetime of half a decade or more, and rapidly changing hardware meant that the initial deployment had to be sized for 5-7 years out. Latency Optimizers” – need support for very large federated deployments. The 5G standard implies that we will go from 5-10 data centers to anything up to 1000 small.
I have a lot of historical data using my ReadOnly benchmark (as described in some of the earliest entries in this blog [link] A read-only access pattern removes the need to understand and explain the many complexities associated with the “streaming stores” typically used in the STREAM benchmark (e.g., Stay tuned!
Budgets are scaled to a benchmark network & device. Deciding what benchmark to use for a performance budget is crucial. It simulates a link with a 400ms RTT and 400-600Kbps of throughput (plus latency variability and simulated packet loss). Performance budgets are set early in the life of the project. Global Ground-Truth.
Google’s industry benchmarks from 2018 also provide a striking breakdown of how each second of loading affects bounce rates. Redirects are often pretty light in terms of the latency that they add to a website, but they are an easy first thing to check, and they can generally be removed with little effort.
I wrote about using CPU-Z to benchmark the Intel Xeon E5-2673 v3 processor in an Azure VM in this article. Figure 1: CPU-Z Benchmark Results for LS16v2. They feature low latency, local NVMe storage that can directly leverage the 128 PCIe 3.0 GHz Intel Xeon E5-2673 v4 (Broadwell) and the 2.4 Figure 2: Microsoft Project Olympus.
Last time around we looked at the DeathStarBench suite of microservices-based benchmark applications and learned that microservices systems can be especially latency sensitive, and that hotspots can propagate through a microservices architecture in interesting ways. on end-to-end latency) and less than 0.15% on throughput.
The HammerDB TPROC-C workload by design intended as CPU and memory intensive workload derived from TPC-C – so that we get to benchmark at maximum CPU performance at a much smaller database footprint. For TPC-C this meant enough available spindles to reduce I/O latency and for TPC-H enough bandwidth for data throughput.
Our customers who deployed Availability Groups were now using servers for primary and secondary replicas with 12+ core sockets and flash storage SSD arrays providing microsecond to low millisecond latencies. Our design needed to scale and be adaptable to the modern hardware on the market. one without a replica).
These systems were designed to have a lifetime of half a decade or more, and rapidly changing hardware meant that the initial deployment had to be sized for 5-7 years out. Latency Optimizers” – need support for very large federated deployments. The 5G standard implies that we will go from 5-10 data centers to anything up to 1000 small.
Engineering is the discipline of designing solutions under specific constraints. If you or your company are able to generate a credible worldwide latency estimate in the higher percentiles for next year's update, please get in touch. For topological reasons I expect next year's report to show similar progress in bandwidth but not RTTs.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content