This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
After reading a lot of blogs I came … The post Notes on tuning postgres for cpu and memory benchmarking appeared first on n0derunner. To do this I needed to drive postgres to do real transactions but have very little jitter/noise from the filesystem and storage.
ScaleGrid is a fully managed DBaaS that supports MySQL, PostgreSQL and Redis™, along with additional support for MongoDB® database and Greenplum® database. Along with many popular cloud providers, DigitalOcean also provides a Managed Databases service. So, which database service is right for your application? Single Node.
MySQL is the all-time number one open source database in the world, and a staple in RDBMS space. MySQL on DigitalOcean is a natural fit, but what’s the best way to deploy your cloud database? MySQL DigitalOcean Performance Benchmark. Read-Intensive Throughput Benchmark. Balanced Workload Throughput Benchmark.
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It has default settings for all of the database parameters. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. This is called double buffering.
Oracle Database is a commercial, proprietary multi-model database management system produced by Oracle Corporation, and the largest relational database management system (RDBMS) in the world. While Oracle remains the #1 database on the market, its popularity has steadily declined by over 18% since 2013. Not available.
Rather than listing the concepts, function calls, etc, available in Citus, which frankly is a bit boring, I’m going to explore scaling out a database system starting with a single host. And now, execute the benchmark: -- execute the following on the coordinator node pgbench -c 20 -j 3 -T 60 -P 3 pgbench The results are not pretty.
This also means we do not rely on vulnerability databases but are able to identify and block such attacks automatically even if they are exploiting unknown weaknesses. A perfect OWASP benchmark score for injection attacks – 100% accuracy and zero false positives – impressively proves the precision of our approach. How to get started.
If we were to select the most important MySQL setting, if we were given a freshly installed MySQL or Percona Server for MySQL and could only tune a single MySQL variable, which one would it be? That’s a heritage of the LAMP model when the same server would host both the database and the web server.
Sure, database migration is complex, particularly when you’re looking to migrate from a proprietary database to an open source one. Database migration is almost always time-consuming, tedious, and full of potential pitfalls. Database migration is complex Let’s start here. Have you tuned your environment?
When using Lambda, you might soon end up using more serverless offerings, like databases, which makes emulating the same environment locally even harder. These served as our benchmark when creating our Lambda monitoring extension. So, stay tuned for more blog posts and announcements. Top enterprise use-cases for AWS Lambda.
When using Lambda, you might soon end up using more serverless offerings, like databases, which makes emulating the same environment locally even harder. These served as our benchmark when creating our Lambda monitoring extension. So, stay tuned for more blog posts and announcements. Top enterprise use-cases for AWS Lambda.
AWS is the #1 cloud provider for open-source database hosting, and the go-to cloud for MySQL deployments. While many AWS users default to their managed database solution, Amazon RDS, there are alternatives available that can improve your MySQL performance on AWS through advanced customization options and unlimited EC2 instance type support.
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It has default settings for all of the database parameters. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload.
Because monolithic applications combine database, client-side interfaces, and server-side application elements in a single executable, they’re difficult to understand, even for their own administrators. Use SLAs, SLOs, and SLIs as performance benchmarks for newly migrated microservices.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. Storage The type of storage and disk used for database servers can have a significant impact on performance and reliability. Benchmark before you decide.
While there is no magic bullet for MySQL performance tuning, there are a few areas that can be focused on upfront that can dramatically improve the performance of your MySQL installation. What are the Benefits of MySQL Performance Tuning? A finely tuneddatabase processes queries more efficiently, leading to swifter results.
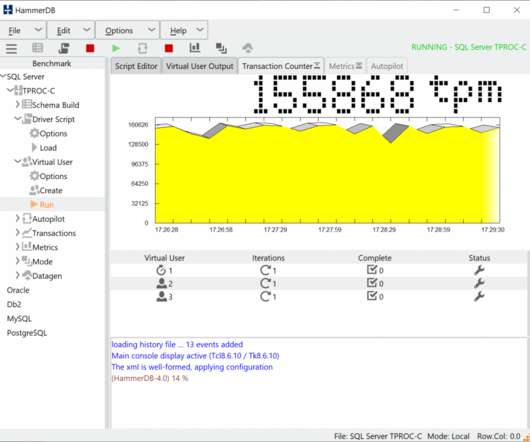
HammerDB doesn’t publish competitive databasebenchmarks, instead we always encourage people to be better informed by running their own. So now lets see what we get in performance mode, an almost 32% improvement (and 53% higher than the published benchmarks). ./bin/pgbench
Redis® is an in-memory database that provides blazingly fast performance. This makes it a compelling alternative to disk-based databases when performance is a concern. Redis returns a big list of database metrics when you run the info command on the Redis shell. This blog post lists the important database metrics to monitor.
Our engineering teams tuned their services for performance after factoring in increased resource utilization due to tracing. In 2019 our stunning colleagues in the Cloud Database Engineering (CDE) team benchmarked EBS performance for our use case and migrated existing clusters to use EBS Elastic volumes.
Some opinions claim that “Benchmarks are meaningless”, “benchmarks are irrelevant” or “benchmarks are nothing like your real applications” However for others “Benchmarks matter,” as they “account for the processing architecture and speed, memory, storage subsystems and the database engine.”
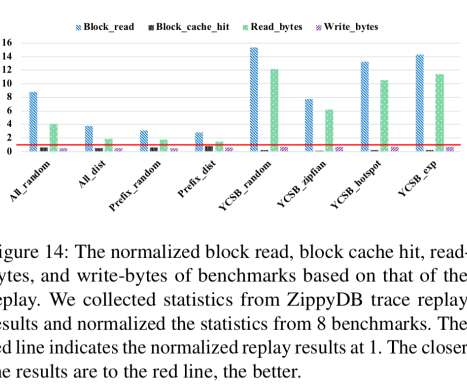
Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook , Cao et al., Or in the case of key-value stores, what you benchmark. So if you want to design a system that will offer good real-world performance, it’s really useful to have benchmarks that accurately represent real-world workloads.
In this example we run pgbench with a scale factor of 1000 which equates to a database size of around 15GB. As expected the write pattern to the log disk (sda) is quite constant, while the write pattern to the database files (sdb) is bursty. I had to tune the parameter checkpoint_completion_target from 0.5
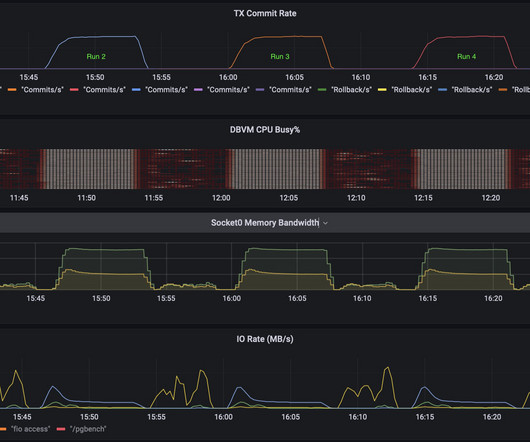
In this video I migrate a Postgres DB running PGbench benchmark. The variation in the transaction rate is due to the benchmark itself, the transaction rate is not expected to be uniform. The Postgres DB is totally un-tuned and contains purely default settings. The DB is running on a Host which is CPU constrained.
On MySQL and Percona Server for MySQL , there is a schema called information_schema (I_S) which provides information about database tables, views, indexes, and more. Disclaimer : This blog post is meant to show a less-known problem but is not meant to be a serious benchmark. Results for Percona Server for MySQL 8.0
Let’s look at some of the most popular Percona Database Performance Blog posts in 2018. With the Percona Database Performance Blog, Percona staff and leadership work hard to provide the open source community with insights, technical support, predictions and metrics around multiple open source database software technologies.
Pinecone is a fully managed vector database that makes it easy to add vector search to production applications. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. The geolocation database or API detects location, proxy and other >20 parameters.
Pinecone is a fully managed vector database that makes it easy to add vector search to production applications. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. The geolocation database or API detects location, proxy and other >20 parameters.
Pinecone is a fully managed vector database that makes it easy to add vector search to production applications. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. The geolocation database or API detects location, proxy and other >20 parameters.
Pinecone is a fully managed vector database that makes it easy to add vector search to production applications. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. The geolocation database or API detects location, proxy and other >20 parameters.
Manual flame graphs collection Although the tool is excellent and automatically provides flame graphs, we don’t have much control over tuning the selected profiler. A simple sysbench benchmark on MySQL shows an overhead between six and 10 percent on CPU-bound systems when running perf with the default sampling frequency of 4000 Hz.
An essential part of database performance testing is viewing the statistics generated by the database during the test and in 2009 HammerDB introduced automatic AWR snapshot generation for Oracle for the TPC-C test. With this feature Oracle generates a wealth of performance data that can be reviewed once the test is complete.
One of the common ways to classify database workloads is whether it is “read intensive” or “write intensive”. Because recognizing if the workload is read intensive or write intensive will impact your hardware choices, database configuration as well as what techniques you can apply for performance optimization and scalability.
Among the different components of modern software solutions, the database is one of the most critical. There are many times we get asked why some cloud instance performed poorly for their database application and almost always turned out to be some configuration error. TB)) for storage of database tablespaces and logging.
HammerDB is a load testing and benchmarking application for relational databases. All the databases that HammerDB tests implement a form of MVCC (multi-version concurrency control). On high-performance multi-core systems all the supported databases can return performance in the many millions of transactions per minute.
Ready to take your database management to the next level with ScaleGrid’s cutting-edge solutions? Register now for free and experience the seamless operation of your databases across multi-cloud and hybrid-cloud systems. Ready to take your database management to the next level with ScaleGrid’s cutting-edge solutions?
Some startups adopted MySQL in its early days such as Facebook, Uber, Pinterest, and many more, which are now big and successful companies that prove that MySQL can run on large databases and on heavily used sites. Some of them are: MySQL Cluster: MySQL NDB Cluster is an in-memory database clustering solution developed by Oracle for MySQL.
They came up with a horizontally scalable NoSQL database. Instead of relational (SQL) databases defined primarily through a hierarchy of related sets via tables and columns, their non-relational structure used a system of collections and documents. Is MongoDB an open source NoSQL database?
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. top(1) showed that only the Cassandra database was consuming CPU. I've shared many posts about superpower observability tools, but often humble hacking is just as effective. These can be invisible to top(8). include <sys/time.h>
In this post I'll look at the Linux kernel page table isolation (KPTI) patches that workaround Meltdown: what overheads to expect, and ways to tune them. I then analyzed performance during the benchmark ([active benchmarking]), and used other benchmarks to confirm findings. Much of my testing was on Linux 4.14.11
If you are new to running Oracle, SQL Server, MySQL and PostgreSQL TPC-C workloads with HammerDB and have needed to investigate I/O performance the chances are that you have experienced waits on writing to the Redo, Transaction Log or WAL depending on the database you are testing. Oracle Log File Sync.
In this post I'll look at the Linux kernel page table isolation (KPTI) patches that workaround Meltdown: what overheads to expect, and ways to tune them. I then analyzed performance during the benchmark ([active benchmarking]), and used other benchmarks to confirm findings. Much of my testing was on Linux 4.14.11
I use the “built in” benchmark pgbench to run a simple set of queries. pgbench creates a ~7.4gb database using a scale-factor of 500. For this experiment I am using Postgres v11 on Linux 3.10 The goal was to see what gains can be made from using hugepages. Experiment. shared_buffers = 16384MB. pgbench -i -s 500.
Similarly, it taught me that “Background scripts are ideal for handling long-term or ongoing tasks, managing state, maintaining databases, and communicating with remote servers. Perhaps future AI tool developers could use Swift Papers as a benchmark to assess how well their tool performs on an example real-real-world programming task.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content