This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
I have generally held the view that replicating data to a secondary system is faster than sync-ing to disk, assuming the round trip network delay wasn’t high due to quality networks and co-located redundant servers. This is the first time I have benchmarked it with a realistic example. Little’s Law and Why Latency Matters.
This is guest post by Sachin Sinha who is passionate about data, analytics and machine learning at scale. Load stage is to load the data and then run stage we run the test. Load is consistent for all dbs for all tests as expected as this phase is to load the data. Again Yugabyte latency is quite high.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Both serve distinct purposes, from managing message queues to ingesting large data volumes.
The jobs executing such workloads are usually required to operate indefinitely on unbounded streams of continuous data and exhibit heterogeneous modes of failure as they run over long periods. ShuffleBench i s a benchmarking tool for evaluating the performance of modern stream processing frameworks.
Instead, they can ensure that services comport with the pre-established benchmarks. SLOs can be a great way for DevOps and infrastructure teams to use data and performance expectations to make decisions, such as whether to release and where engineers should focus their time. SLOs improve software quality. SLOs aid decision making.
Among the critical enablers for fast data access implementation within in-memory data stores are the game changers in recent times, which are technologies like Redis and Memcached. We have run these benchmarks on the AWS EC2 instances and designed a custom dataset to make it as close as possible to real application use cases.
Compare Latency. lower latency compared to DigitalOcean for PostgreSQL. Now, let’s take a look at the throughput and latency performance of our comparison. Next, we are going to test and compare the latency performance between ScaleGrid and DigitalOcean for PostgreSQL. PostgreSQL DigitalOcean Latency Averages (ms).
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
Quality gates are benchmarks in the software delivery lifecycle that define specific, measurable, and achievable success criteria a service must meet before moving to the next phase of the software delivery pipeline. For example, improving latency by as little as 0.1 latency is the number one reason consumers abandon mobile sites.
As organizations continue to migrate to the cloud, it’s important to get in front of performance issues, such as high latency, low throughput, and replication lag with higher distances between your users and cloud infrastructure. Slave-2 uses an EBS data disk, and you can configure the amount of IOPS required for your cluster.
Technology advancements in content creation and consumption have also increased its data footprint. To sustain this data growth at Netflix, it has deployed open-source software Ceph using AWS services to achieve the required SLOs of some of the post-production workflows.
Real user monitoring (RUM) is a performance monitoring process that collects detailed data about users’ interactions with an application. RUM collects data on each user action within a session, including the time required to complete the action, so IT pros can identify patterns and where to make improvements in experience.
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. Traces collected from various microservices are ingested in a stream processing manner into the data store.
When it comes to Citus, successfully building out and scaling a PostgreSQL cluster across multiple nodes and even across data centers can feel, at times, to be an art form because there are so many ways of building it out. The following invocation generates almost 4GB of data.
Configuring Grafana For our purposes, the Grafana datasource used in this PoC is also the Postgres data cluster that is generating the data to be monitored. It collects various statistics data such as query statistics, query plan, SQL comments, and other performance insights. And yes, it even works in PostgreSQL.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. These essential data points heavily influence both stability and efficiency within the system.
It has high throughput and runs from memory, but also has the ability to persist data on disk. In fact, it is the number one key value store and eighth most popular database in the world. Redis is a great caching solution for highly demanding applications, and there are […].
DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads. It becomes more manageable and efficient by isolating logs and data to a dedicated mount. Who can benefit from DLV? Are DLVs effective for your RDS instance?
HammerDB doesn’t publish competitive database benchmarks, instead we always encourage people to be better informed by running their own. So over at Phoronix some database benchmarks were published showing PostgreSQL 12 Performance With AMD EPYC 7742 vs. Intel Xeon Platinum 8280 Benchmarks .
With that in mind, I decided to mine some historical data (and run a few new experiments) to see how single-thread/single-core memory bandwidth has evolved over the last 10-15 years. GHz, 1530 GB/s peak BW from 6 HBM stacks), I see single-thread sustained memory bandwidth of 304 GB/s on the ReadOnly benchmark used here. Stay tuned!
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook , Cao et al., Or in the case of key-value stores, what you benchmark. So if you want to design a system that will offer good real-world performance, it’s really useful to have benchmarks that accurately represent real-world workloads.
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures. On MySQL, we saw a 1.5X
Technology advancements in content creation and consumption have also increased its data footprint. To sustain this data growth at Netflix, it has deployed open-source software Ceph using AWS services to achieve the required SLOs of some of the post-production workflows.
Technology advancements in content creation and consumption have also increased its data footprint. To sustain this data growth at Netflix, it has deployed open-source software Ceph using AWS services to achieve the required SLOs of some of the post-production workflows.
Two big things: They bring the messiness of the real world into your system through unstructured data. When your system is both ingesting messy real-world data AND producing nondeterministic outputs, you need a different approach. People have been building data products and machine learning products for the past couple of decades.
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval.
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 In MySQL, considering the standard storage engine, InnoDB , the data cache is called Buffer Pool. MySQL (B) 2517529 2610323 389048 5516900 194140 11523.48
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
Kubernetes has emerged as go to container orchestration platform for data engineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. better cluster resource utilization.
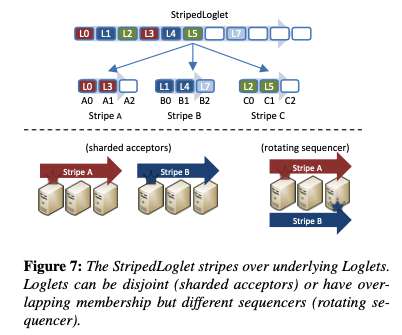
If you think of this a bit like mapping memory addresses to data in memory, then another parallel comes to mind: the virtual address space. This separation of concerns moves reconfiguration into the VirtualLog control plane, leaving Loglets responsible for the data plane. Delos in production. Limitations and future work.
Database uptime and availability Monitoring database uptime and availability is crucial as it directly impacts the availability of critical data and the performance of applications or websites that rely on the MySQL database. Disk space usage Monitor the disk space usage of MySQL data files, log files, and temporary files.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
In this case, we have a quite well-defined scenario that can resemble the image below: In this scenario, the proxies must sit inside Pods, balancing the incoming traffic from the Service LoadBalancer connecting with the active data nodes. Let us take a look also the latency: Here the situation starts to be a little bit more complicated.
This data is from the 2007 presentation. To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It
Nowadays, solid-state drives (SSDs) or non-volatile memory express (NVMe) drives are preferred over traditional hard disk drives (HDDs) for database servers due to their faster read and write speeds, lower latency, and improved reliability. Benchmark before you decide. Transparent huge pages (THP) disabled.
In this light, we are always seeking to prove Volt’s value against other data platforms for supporting applications that need to be fast without compromising on things like accuracy, consistency, or resiliency. As part of our new support for ARM processors , we recently ran benchmarks on both Intel C7 and ARM c7g on AWS.
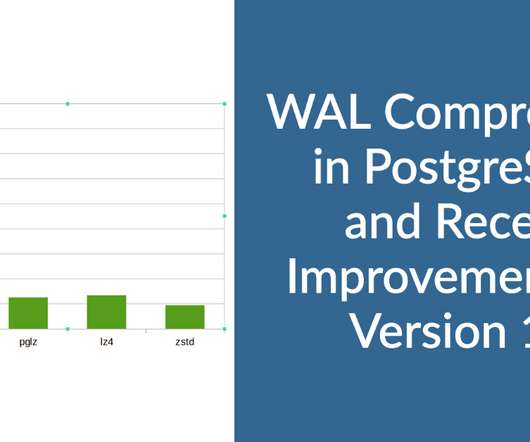
Reduced WAL segment size has further gains in replication and backup because less data need to be transmitted. Individual processes generate WAL records, and latency is very crucial for transactions. What is Full Page Writes? getconf PAGESIZE 4096 PostgreSQL deals with 8k pages as the “atomic unit” for reading and writing.
Looking at the industry benchmarks for US retailers , four well-known sites have backend times that are approaching – or well beyond – that threshold. Pagespeed Benchmarks - US Retail - LCP When you examine a waterfall, it's pretty obvious that TTFB is the long pole in the tent, pushing out render times for the page.
There’s a broad set of choices including where you store the data, whether you run your own DBMS nodes or use a service, the kinds of instance types to go for if you do run your own, and so forth. We focused on OLAP-oriented parallel data warehouse products available for AWS and restricted our attention to commercially available systems.
They can also bolster uptime and limit latency issues or potential downtimes. This covers everything from tech specs and what you expect from the service to security, how you’ll handle data, and how services will be managed. Each private cloud setup has perks and benefits, especially for handling specific tasks.
This post mines publicly available data on the pace of compatibility fixes and feature additions to assess the claim. As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. Converging Views.
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Consistent performance matters just as much as low average latency. Photo by von Vix.
Key Takeaways A cloud workload encompasses any application or service running on a cloud infrastructure, facilitating tasks ranging from basic functions to advanced data analysis with the help of resources like databases, collaboration tools, and disaster recovery systems. This applies to both virtual machines and container-based deployments.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content