This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Both serve distinct purposes, from managing message queues to ingesting large data volumes.
Five-nines availability: The ultimate benchmark of system availability. Cloud service providers, such as Amazon Web Services (AWS) , can offer infrastructure with five-nines availability by deploying in multiple availability zones and replicating data between regions. Gather observability data from all digital touchpoints.
Dynatrace OneAgent deployment and life-cycle management are already widely considered to be industry benchmarks for reliability and efficiency. We’re now allowing for even easier OneAgent rollout by freeing up the /opt mount point from any runtime data that’s produced by OneAgents. Dynatrace news.
Limits of a lift-and-shift approach A traditional lift-and-shift approach, where teams migrate a monolithic application directly onto hardware hosted in the cloud, may seem like the logical first step toward application transformation. Use SLAs, SLOs, and SLIs as performance benchmarks for newly migrated microservices.
We've always been excited about Arm so when Amazon offered us early access to their new Arm-based instances we jumped at the chance to see what they could do. We are, of course, referring to the Amazon EC2 M6g instances powered by AWS Graviton2 processors.
In this post, I show some of the reasons why that's true, using the Amazon Redshift team and the approach they have taken to improve the performance of their data warehousing service as an example. Verifying benchmark claims. This yields hundreds of millions of data samples. Verifying benchmark claims.
HammerDB doesn’t publish competitive database benchmarks, instead we always encourage people to be better informed by running their own. So over at Phoronix some database benchmarks were published showing PostgreSQL 12 Performance With AMD EPYC 7742 vs. Intel Xeon Platinum 8280 Benchmarks .
When it comes to Citus, successfully building out and scaling a PostgreSQL cluster across multiple nodes and even across data centers can feel, at times, to be an art form because there are so many ways of building it out. The following invocation generates almost 4GB of data.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. Benchmark before you decide. have been released since then with some major changes. Transparent huge pages (THP) disabled.
Google’s data center kernel is carefully performance tuned for their workloads. For the rest of us, if you really need that extra performance (maybe what you get out-of-the-box or with minimal tuning is good enough for your use case) then you can upgrade hardware and/or pay for a commercial license of a tuned distributed (RHEL).
Beyond data and model parallelism for deep neural networks Jia et al., Traditional approaches to training exploit either data parallelism (dividing up the training samples), model parallelism (dividing up the model parameters), or expert-designed hybrids for particular situations. SysML’2019. Expanding the search space.
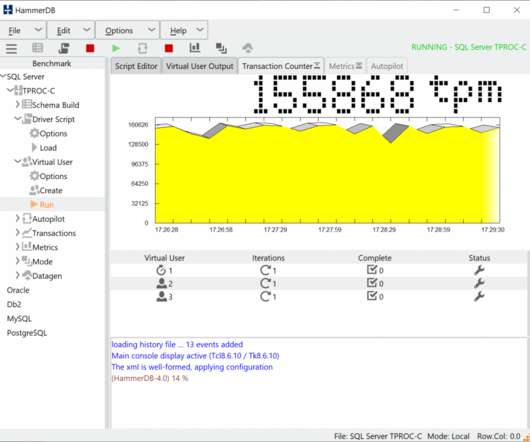
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures. On MySQL, we saw a 1.5X
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. Fault tolerance aims for zero downtime and data loss. Data replication : Data is continually copied from one database to another to ensure that the system remains operational even if one database fails.
Oracle requires more complex ongoing administration, as all database configurations must evolve in conjunction with the data schemas and custom code. Data encryption can be achieved with advanced security plugins like pgcrypto which are available for free. CitusDB – distributes data and queries horizontally across nodes.
Kubernetes has emerged as go to container orchestration platform for data engineering teams. In 2018, a widespread adaptation of Kubernetes for big data processing is anitcipated. Organisations are already using Kubernetes for a variety of workloads [1] [2] and data workloads are up next. better cluster resource utilization.
Disclaimer : This blog post is meant to show a less-known problem but is not meant to be a serious benchmark. The percentage in degradation will vary depending on many factors {hardware, workload, number of tables, configuration, etc.}. Setup The setup consists of creating 10K tables with sysbench and adding 20 FKs to 20 tables.
In the digital age, data management has transformed from locally hosted servers to cloud solutions. These databases require significant time commitment along with necessary technical skills plus hardware & software costs, all of which are without dedicated team assistance.
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval.
Size matters especially to mobile users who have limited and/or metered data. It's important to mention that there have been changes to how the Archive collects data over the years. Having said that, looking at data over the past ten years, it's safe to make the observation that pages are definitely trending bigger.
Key metrics like throughput, request latency, and memory utilization are essential for assessing Redis health, with tools like the MONITOR command and Redis-benchmark for latency and throughput analysis and MEMORY USAGE/STATS commands for evaluating memory. It depends upon your application workload and its business logic.
Database uptime and availability Monitoring database uptime and availability is crucial as it directly impacts the availability of critical data and the performance of applications or websites that rely on the MySQL database. Disk space usage Monitor the disk space usage of MySQL data files, log files, and temporary files.
With that in mind, I decided to mine some historical data (and run a few new experiments) to see how single-thread/single-core memory bandwidth has evolved over the last 10-15 years. GHz, 1530 GB/s peak BW from 6 HBM stacks), I see single-thread sustained memory bandwidth of 304 GB/s on the ReadOnly benchmark used here. Stay tuned!
This post mines publicly available data on the pace of compatibility fixes and feature additions to assess the claim. As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. Converging Views.
Some opinions claim that “Benchmarks are meaningless”, “benchmarks are irrelevant” or “benchmarks are nothing like your real applications” However for others “Benchmarks matter,” as they “account for the processing architecture and speed, memory, storage subsystems and the database engine.”
We’ll also look at the differences, as it’s important to know what architecture(s) will help you best meet your unique requirements for maximizing data assets and achieving continuous uptime. Redundancy: The system stores multiple copies of data on separate devices. there cannot be high availability.
In this light, we are always seeking to prove Volt’s value against other data platforms for supporting applications that need to be fast without compromising on things like accuracy, consistency, or resiliency. As part of our new support for ARM processors , we recently ran benchmarks on both Intel C7 and ARM c7g on AWS.
It fails because of a compiler optimization where the frame pointer register is used to store data instead of the frame pointer, but it's just a number so the profiler is unaware this happened and tries to match that address to a function symbol and fails (it is therefore an unknown symbol). You usually get an extra junk frame.
Existing cache and main memory compression techniques compress data in small fixed-size blocks, typically cache lines. Looking across a set of eight Java benchmarks, we find that only two of them are array dominated, the rest having between 40% to 75% of the heap footprint allocated to objects, the vast majority of which are small.
HammerDB is a software application for database benchmarking. It enables the user to measure database performance and make comparative judgements about database hardware and software. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking. Derived Workloads.
Because recognizing if the workload is read intensive or write intensive will impact your hardware choices, database configuration as well as what techniques you can apply for performance optimization and scalability. Let’s examine the TPC-C Benchmark from this point of view, or more specifically its implementation in Sysbench.
Last week we saw the benefits of rethinking memory and pointer models at the hardware level when it came to object storage and compression ( Zippads ). The protections are hardware implemented and cannot be forged in software. At hardware reset the boot code is granted maximally permissive architectural capabilities.
HammerDB is a load testing and benchmarking application for relational databases. This helps to minimise locking allowing multiple sessions to access the same data at the same time. However, it is crucial that the benchmarking application does not have inherent bottlenecks that artificially limits the scalability of the database.
Can machine learning-based data structures i.e. learned data structures replace traditional data structures? The initial results show that learned data structures can outperform existing data structures. This has far-reaching implications how future data systems and algorithms will be designed. p = F(Key) ?
With disks being faster nowadays and CPU and memory resources being cheaper, we could easily say MySQL can handle TBs of data with good performance. For instance, in Percona Managed Services , we have many clients with TBs worth of data that are well performant. There are many compression tools and algorithms for data out there.
Systems researchers are doing an excellent job improving the performance of 5-year old benchmarks, but gradually making it harder to explore innovative machine learning research ideas. This comes at a cost though; copying, rearranging, and materialising to memory two orders of magnitude more data than is strictly necessary.
Hardware Optimizers” want to get the maximum utilization out of hardware. These systems were designed to have a lifetime of half a decade or more, and rapidly changing hardware meant that the initial deployment had to be sized for 5-7 years out. Attendees could be broken down into several distinct groups.
Seer: leveraging big data to navigate the complexity of performance debugging in cloud microservices Gan et al., When a QoS violation is predicted to occur and a culprit microservice located, Seer uses a lower level tracing infrastructure with hardware monitoring primitives to identify the reason behind the QoS violation.
In a recent project comparing systems for MariaDB performance, a user had originally been using a tool called sysbench-tpcc to compare hardware platforms before migrating to HammerDB. This is a brief post to highlight the metrics to use to do the comparison using a separate hardware platform for illustration purposes. sum: 23997083.58
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
This rework delays launch which, in turn, delays gathering data about the viability of a PWA strategy. Budgets are scaled to a benchmark network & device. Deciding what benchmark to use for a performance budget is crucial. Given the conflicted data we see across our other systems, this seems about right as a baseline.
Key areas include: Configuration parameter tuning : This tuning involves altering variables such as memory allocation, disk I/O settings, and concurrent connections based on specific hardware and requirements. Slow queries and data retrieval can lead to frustrating delays that impact the user experience. Nobody has time for that!
This results in expedited query execution, reduced resource utilization, and more efficient exploitation of the available hardware resources. This not only enhances performance but also enables you to make more efficient use of your hardware resources, potentially resulting in cost savings on infrastructure.
When we released Always On Availability Groups in SQL Server 2012 as a new and powerful way to achieve high availability, hardware environments included NUMA machines with low-end multi-core processors and SATA and SAN drives for storage (some SSDs). As we moved towards SQL Server 2014, the pace of hardware accelerated.
Before you begin tuning your website or application, you must first figure out which metrics matter most to your users and establish some achievable benchmarks. An interruption in data flow due to limited capacity is called a bottleneck. Test and collect data: Let your testing software do all the hard work, then assess the results.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content