This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here’s how these capabilities come together in Dynatrace platform to transform Kubernetes security and compliance: Automated security assessments Security best practices and benchmarks can be automatically assessed, providing valuable insights into the overall configuration security.
We look at the two databases in terms of benchmark performance and user experience. Time-series data has gained popularity in recent years. It is used in a wide variety of industries and use cases (if you are new to this space, read our article 'What is Time-Series Data' ).
CSA Star 2 strengthens Dynatrace cloud security posture CSA Star 2 certification provides a trusted benchmark for cloud security and thus strengthens the overall Dynatrace security posture. Achieving CSA Star 2 certification is not just a badge of honor for Dynatrace; it’s a testament to our dedication to safeguarding your data.
This is guest post by Sachin Sinha who is passionate about data, analytics and machine learning at scale. Load stage is to load the data and then run stage we run the test. Load is consistent for all dbs for all tests as expected as this phase is to load the data. Author & founder of BangDB. Conclusion.
Efficient data processing is crucial for businesses and organizations that rely on big data analytics to make informed decisions. One key factor that significantly affects the performance of data processing is the storage format of the data.
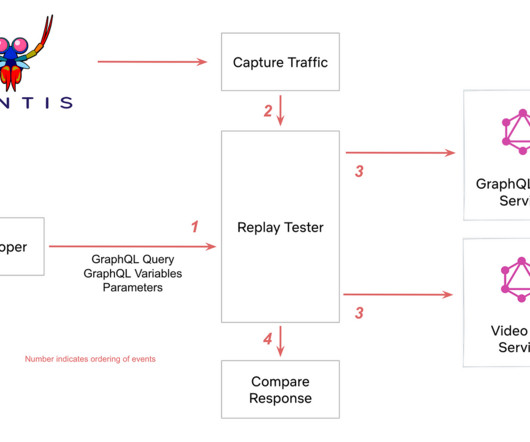
In his first talk, The Service Mesh Wars: A New Hope for Kubernetes , Henrik compares and benchmarks five service mesh technologies (Istio, Linkerd, Cillium eBPF, Kuma, and Ambassador Edge) across multiple dimensions to demonstrate when and how to use them. I used Dynatrace dashboards , powered by DQL , to help me analyze the data.
Neglected misconfigurations (such as mismanaged permissions or unsecured API access) can expose sensitive data and invite malicious activity. It evaluates these resources against known best practices (for example: not running containers as root; using namespaces effectively) and compliance standards (such as CIS Benchmarks).
The jobs executing such workloads are usually required to operate indefinitely on unbounded streams of continuous data and exhibit heterogeneous modes of failure as they run over long periods. ShuffleBench i s a benchmarking tool for evaluating the performance of modern stream processing frameworks. Recovery time of the latency p90.
While this approach can be effective if the model is trained with a large amount of data, even in the best-case scenarios, it amounts to an informed guess, rather than a certainty. But to be successful, data quality is critical. Teams need to ensure the data is accurate and correctly represents real-world scenarios. Consistency.
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
This article presents the most recent Memphis.dev Cloud, multi-region benchmark tests conducted in December 2023, explores how to carry out performance testing, detailing hands-on methods you can apply yourself, and provides recent benchmarkdata for your reference. The benchmark tool we used can be found here.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. Both serve distinct purposes, from managing message queues to ingesting large data volumes.
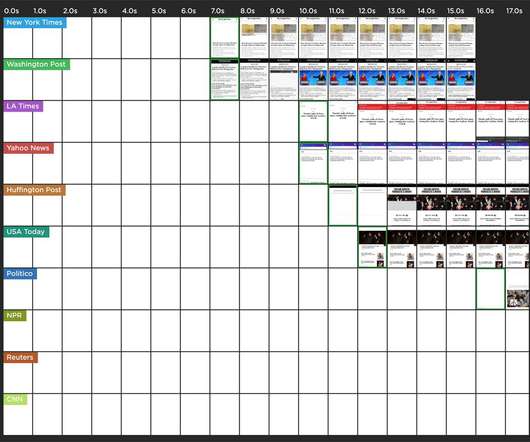
What are some good sites I can use for benchmarking? Page Speed Benchmarks is an interactive dashboard that lets you explore and compare web performance data for leading websites across several industries – from retail to media. Identify sites you can use for your own competitive benchmarking. How fast should I be?
Instead, they can ensure that services comport with the pre-established benchmarks. SLOs can be a great way for DevOps and infrastructure teams to use data and performance expectations to make decisions, such as whether to release and where engineers should focus their time. SLOs improve software quality. SLOs aid decision making.
Among the critical enablers for fast data access implementation within in-memory data stores are the game changers in recent times, which are technologies like Redis and Memcached. We have run these benchmarks on the AWS EC2 instances and designed a custom dataset to make it as close as possible to real application use cases.
Frequently, practitioners want to experiment with variants of these flows, testing new data, new parameterizations, or new algorithms, while keeping the overall structure of the flow or flowsintact. This has been a guiding design principle with Metaflow since its inception.
I have generally held the view that replicating data to a secondary system is faster than sync-ing to disk, assuming the round trip network delay wasn’t high due to quality networks and co-located redundant servers. This is the first time I have benchmarked it with a realistic example. Little’s Law and Why Latency Matters.
In a previous article , we explained how we built benchmarks to keep track of those three metrics: precision, recall, and the most important here, speed. These benchmarks taught us a lot about the true internals of our engine at runtime and led to our first improvements.
Latency is the average transaction execution time of your PostgreSQL data. PostgreSQL Benchmark Setup. Here is the configuration we used for the ScaleGrid and DigitalOcean benchmark performance tests highlighted above: Configuration. Benchmark Tool. PostgreSQL Version. Scaling Factor. Query Mode. Number of Clients.
For stateful workloads like PostgreSQL, storage must offer high availability and safeguard data integrity, even under intense, high-volume conditions. Picking the right option is critical, directly impacting performance, reliability, and scalability. To address these concerns, […]
Quality gates are benchmarks in the software delivery lifecycle that define specific, measurable, and achievable success criteria a service must meet before moving to the next phase of the software delivery pipeline. Enforcing benchmarks in real time. What are quality gates? Using quality gates for measurable impacts.
The first method, which can be seen as a form of weak supervision , leverages auxiliary data in the form of a screenplay by aligning screenplay text with timed text (closed captions, audio descriptions) and assigning timestamps to the screenplay’s scene headers (a.k.a. sluglines). Figure 1: a scene consists of a sequence of shots.
Improving each of these should hopefully chip away at the timings of more granular events that precede the LCP milestone, but whenever we’re making these kinds of indirect optimisation, we need to think much more carefully about how we measure and benchmark ourselves as we work. It’s vital to measure what you impact, not what you influence.
We've always been excited about Arm so when Amazon offered us early access to their new Arm-based instances we jumped at the chance to see what they could do. We are, of course, referring to the Amazon EC2 M6g instances powered by AWS Graviton2 processors.
Service-level objectives (SLOs) are key to the SRE role; they are agreed-upon performance benchmarks that represent the health of an application or service. SREs need SLOs to measure and monitor performance, but many organizations lack the automation and intelligence to streamline data.
In today’s complex, data-driven world, many security vulnerabilities and attacks can jeopardize an organization’s data. To ensure the safety of their customers, employees, and business data, organizations must have a strategy to protect against zero-day vulnerabilities. Application logs are a good data source for this method.
Software analytics offers the ability to gain and share insights from data emitted by software systems and related operational processes to develop higher-quality software faster while operating it efficiently and securely. This involves big data analytics and applying advanced AI and machine learning techniques, such as causal AI.
Retail is one of the most important business domains for data science and data mining applications because of its prolific data and numerous optimization problems such as optimal prices, discounts, recommendations, and stock levels that can be solved using data analysis methods.
Developers use release validation as an internal consistency mechanism to validate individual releases before collecting data for the next release. It is also a vital data collection mechanism for regression testing against subsequent releases. Look for automation tools to help with release validation data and reports.
Social media was relatively quiet, and as always, the Dynatrace Insights team was benchmarking key retailer home pages from mobile and desktop perspectives. There is a wealth of data tied up in logs that can be used by retailers. This year we saw few, if any, major issues with online retailers.
Technology advancements in content creation and consumption have also increased its data footprint. To sustain this data growth at Netflix, it has deployed open-source software Ceph using AWS services to achieve the required SLOs of some of the post-production workflows.
They collect data from multiple sources through real user monitoring , synthetic monitoring, network monitoring, and application performance monitoring systems. This data provides organizations with end-to-end visibility of the entire user journey across the tech stack.
This paper deals with definitions and understanding of structured data vs unstructured data, how various storage segments react to block size changes, and differences between I/O-driven and throughput-driven workloads. It also highlights the calculation of throughput and the choice of storage product based on workload type.
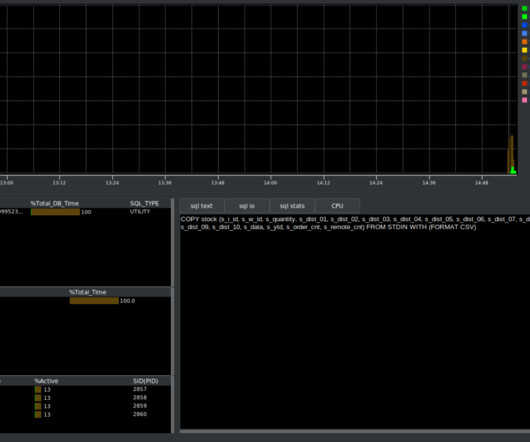
The key findings of the article were as follows: This server had a HammerDB benchmark running against it. During a copy operation, the data is transferred from the client’s file system to the Aurora PostgreSQL DB cluster. But why are we running a COPY operation during a benchmark anyway?
With the increasing frequency of cyberattacks, it is imperative to institute a set of cybersecurity best practices that safeguard your organization’s data and privacy. This process can involve analyzing logs and other data to determine if the event represents a security threat.
It has high throughput and runs from memory, but also has the ability to persist data on disk. In fact, it is the number one key value store and eighth most popular database in the world. Redis is a great caching solution for highly demanding applications, and there are […].
This, of course, is exacerbated by the new Vitals announcement, whereby data from the Chrome User eXperience Report will be used to aid and influence rankings. The data is static which isn’t necessarily a drawback until it is—DevTools allows us to work far more quickly and interactively, responding to changes and tweaks as we make them.
Today’s IT infrastructures combine on-premise data centers, servers, and mainframes with highly dynamic multi-cloud environments, with microservices running in containers, spanning multiple clouds and hybrid infrastructure. AI-assistance: Use AI to detect anomalies and benchmark your system. What is infrastructure monitoring? .
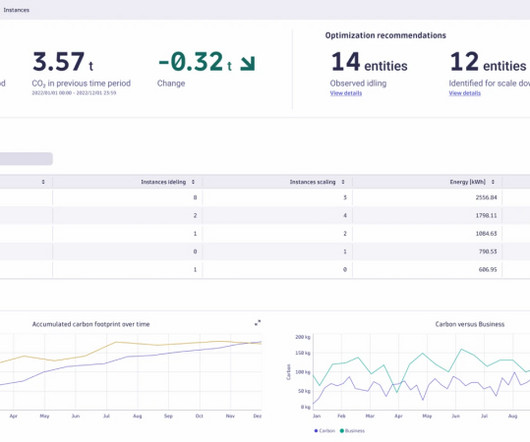
A single data center can consume the equivalent electricity of 50,000 homes.” The app’s advanced algorithms and real-time data analytics translate utilization metrics into their CO2 equivalent (CO2e). Using Carbon Impact, we can now implement efficiency measures driven by the app’s benchmarks and recommendations.
With Dynatrace, you can also validate your findings against Real User Monitoring data or even drill down to the code level to pinpoint the root cause of a change in performance. This is definitely a great starting benchmark against which to optimize your application. Validate synthetic results with real user data.
However, as an internal benchmark, there are compelling reasons why some of you may actually want to keep tracking these ‘outdated’ metrics… Measure the User Experience The problem with using diagnostic metrics like Load or DOMContentLoaded to measure site-speed is that it has no bearing on how a user might actually experience your site.
When it comes to Dynatrace DEM, Vinh puts it simply: “We focus on providing answers instead of just more data.” “Our team helps customers get the most out of DEM through configuration, data expertise, and analysis,” says Voorhies. AIOps leverages user experience data to inform DevOps.
Real user monitoring (RUM) is a performance monitoring process that collects detailed data about users’ interactions with an application. RUM collects data on each user action within a session, including the time required to complete the action, so IT pros can identify patterns and where to make improvements in experience.
Five-nines availability: The ultimate benchmark of system availability. Cloud service providers, such as Amazon Web Services (AWS) , can offer infrastructure with five-nines availability by deploying in multiple availability zones and replicating data between regions. Gather observability data from all digital touchpoints.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content