This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ScaleGrid MySQL on Azure so you can see which provider offers the best throughput and latency performance. We measure latency in ms 95th percentile latency. During Read-Intensive Workloads, ScaleGrid manages to achieve up to 3 times higher throughput and averages 66% better latency compared to Azure Database.
Architecture Comparison RabbitMQ and Kafka have distinct architectural designs that influence their performance and suitability for different use cases. Its partitioned log architecture supports both queuing and publish-subscribe models, allowing it to handle large-scale event processing with minimal latency.
Compare Latency. On average, ScaleGrid achieves almost 30% lower latency over DigitalOcean for the same deployment configurations. MySQL DigitalOcean Performance Benchmark. In this benchmark, we compare equivalent plan sizes between ScaleGrid MySQL on DigitalOcean and DigitalOcean Managed Databases for MySQL. Throughput.
Compare Latency. lower latency compared to DigitalOcean for PostgreSQL. Now, let’s take a look at the throughput and latency performance of our comparison. Next, we are going to test and compare the latency performance between ScaleGrid and DigitalOcean for PostgreSQL. PostgreSQL DigitalOcean Latency Averages (ms).
Instead, they can ensure that services comport with the pre-established benchmarks. Using data from Dynatrace and its SLO wizard , teams can easily benchmark meaningful, user-based reliability measurements and establish error budgets to implement SLOs that meet business objectives and drive greater DevOps automation. Reliability.
We have run these benchmarks on the AWS EC2 instances and designed a custom dataset to make it as close as possible to real application use cases. We compare throughput, operations per second, and latency under different loads, namely the P90 and P99 percentiles.
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
Let us take a look also the latency: Here the situation starts to be a little bit more complicated. MySQL Router is the one that has the higher latency no matter what. Looking at the latency, we can see that HAProxy gradually increased as expected, while ProxySQL and MySQL Router just went up from the 256 threads on.
DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads. We performed a standard benchmarking test using the sysbench tool to compare the performance of a DLV instance vs a standard RDS MySQL instance, as shared in the following section.
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. There are three generations of GPUs that are relevant to this comparison. Various benchmarks show improvements of 1.4x
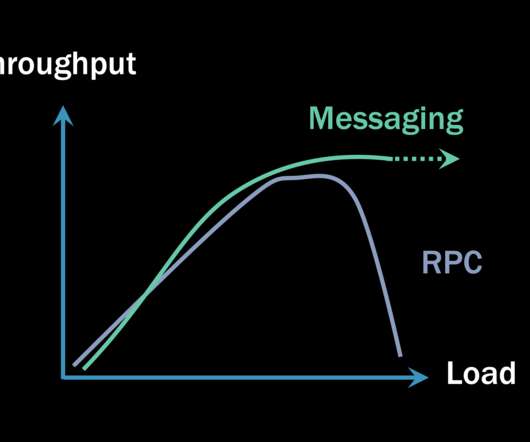
Some will claim that any type of RPC communication ends up being faster (meaning it has lower latency) than any equivalent invocation using asynchronous messaging. It’s less of an apples-to-oranges comparison and more like apples-to-orange-sherbet. There are more steps, so the increased latency is easily explained.
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Performance Comparison: Redis vs Memcached Although Redis and Memcached are high-performance in-memory data stores, their performance characteristics are distinct.
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures. On MySQL, we saw a 1.5X
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 on CentOS 7, both of them spec’d with four vCPUs but with the second one (server B) having a tad over twice as much memory than the reference one (server A).
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. As I'm interested in the relative comparison I can just compare the total runtimes (the "real" time) for the same result. I've shared many posts about superpower observability tools, but often humble hacking is just as effective.
use the TPC-H benchmark to assess Redshift, Redshift Spectrum, Athena, Presto, Hive, and Vertica to find out what works best and the trade-offs involved. The experimental results focus on six main areas of comparison: query restrictions system initialisation time query performance cost data compatibility with other systems scalability.
Here’s some predictions I’m making: Jack Dongarra’s efforts to highlight the low efficiency of the HPCG benchmark as an issue will influence the next generation of supercomputer architectures to optimize for sparse matrix computations. In comparison, for Linpack Frontier operates at 68% of peak capacity. petaflops, which is 0.8%
This is a brief post to highlight the metrics to use to do the comparison using a separate hardware platform for illustration purposes. Throughput: events/s (eps): 8162.5668 time elapsed: 300.0356s total number of events: 2449061 Latency (ms): min: 0.35 The HammerDB workload is run as shown: Copy Code Copied Use a different Browser.
This is a complex topic, but to borrow from a recent post , web performance expands access to information and services by reducing latency and variance across interactions in a session, with a particular focus on the tail of the distribution (P75+). Consistent performance matters just as much as low average latency.
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. All modern browsers are fast, Chromium and Safari/WebKit included. Offscreen Canvas.
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. As I'm interested in the relative comparison I can just compare the total runtimes (the "real" time) for the same result. A quick check of basic performance statistics showed over 30% higher CPU consumption. us on Ubuntu.
Each of the two vector units can issue one FMA instruction per cycle, assuming that there are enough independent accumulators to tolerate the 6-cycle dependent-operation latency. Using the minimum number of accumulator registers needed to tolerate the pipeline latency (12), the assembly code for the inner loop is: B1.8: 8.056 0.056 75.0%
Each of the two vector units can issue one FMA instruction per cycle, assuming that there are enough independent accumulators to tolerate the 6-cycle dependent-operation latency. Using the minimum number of accumulator registers needed to tolerate the pipeline latency (12), the assembly code for the inner loop is: B1.8: 8.056 0.056 75.0%
A Cassandra database cluster had switched to Ubuntu and noticed write latency increased by over 30%. As I'm interested in the relative comparison I can just compare the total runtimes (the "real" time) for the same result. I've shared many posts about superpower observability tools, but often humble hacking is just as effective.
Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. It was tempting to write this blog post as a feature comparison between AppFabric and SOSS. Testing Scale-Up Performance. In Summary: Design for Ease of Use and High Performance.
For anyone benchmarking MySQL with HammerDB it is important to understand the differences from sysbench workloads as HammerDB is targeted at a testing a different usage model from sysbench. maximum transition latency: Cannot determine or is not supported. . HammerDB difference from Sysbench. hardware limits: 1000 MHz - 3.80
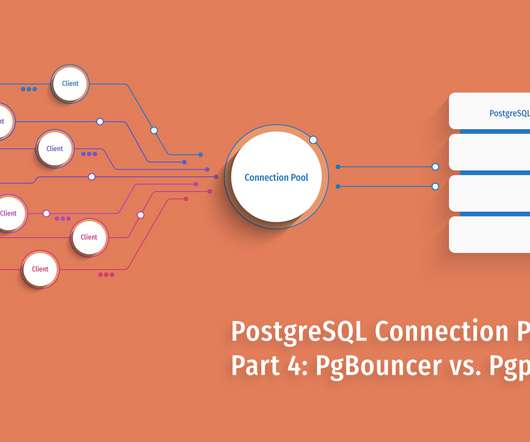
In our final post, we will put them head-to-head in a detailed feature comparison and compare the results of PgBouncer vs. Pgpool-II performance for your PostgreSQL hosting ! All of the PostgreSQL benchmark tests were run under the following conditions: Initialized pgbench using a scale factor of 100. Throughput Benchmark.
The caching of data pages and grouping of log records helps remove much, if not all, of the command latency associated with a write operation. Action Description Manual Checkpoint – Target Specified I/O latency target set to the default of 20ms.
Using this approach, we observed latencies ranging from 1 to 10 seconds, averaging 7.4 In comparison, the terminal handler used only 0.47% CPU time. The input to stdin is sent to the backend (i.e., JupyterLab) via a WebSocket, and the output to stdout is sent back from the backend and displayed on the UI. We then exported the .har
Alternatively, you can also use: Addy Osmani’s Chrome UX Report Compare Tool , Speed Scorecard (also provides a revenue impact estimator), Real User Experience Test Comparison or SiteSpeed CI (based on synthetic testing). Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms.
Alternatively, you can also use Speed Scorecard (also provides a revenue impact estimator), Real User Experience Test Comparison or SiteSpeed CI (based on synthetic testing). Paddy Ganti’s script constructs two URLs (one normal and one blocking the ads), prompts the generation of a video comparison via WebPageTest and reports a delta.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content