This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Kafka scales efficiently for large data workloads, while RabbitMQ provides strong message durability and precise control over message delivery. Message brokers handle validation, routing, storage, and delivery, ensuring efficient and reliable communication. This allows Kafka clusters to handle high-throughput workloads efficiently.
Performance Benchmarking of PostgreSQL on ScaleGrid vs. AWS RDS Using Sysbench This article evaluates PostgreSQL’s performance on ScaleGrid and AWS RDS, focusing on versions 13, 14, and 15. This study benchmarks PostgreSQL performance across two leading managed database platforms—ScaleGrid and AWS RDS—using versions 13, 14, and 15.
MySQL DigitalOcean Performance Benchmark. In this benchmark, we compare equivalent plan sizes between ScaleGrid MySQL on DigitalOcean and DigitalOcean Managed Databases for MySQL. We are going to use a common, popular plan size using the below configurations for this performance benchmark: Comparison Overview. Throughput.
This begins not only in designing the algorithm or coming out with efficient and robust architecture but right onto the choice of programming language. One, by researching on the Internet; Two, by developing small programs and benchmarking. Most of us, as we spend years in our jobs — tend to be proficient in at least one of these.
In some instances, libdivide can even be more efficient than compilers because it uses an approach introduced by Robison (2005) where we not only use multiplications and shifts, but also an addition to avoid arithmetic overflows. We also published our benchmarks for research purposes. I make my benchmarking code available.
In this scenario, it is also crucial to be efficient in resource utilization and scaling with frugality. This is due to the multiplexing and the very efficient way ProxySQL uses to deal with high load. HAProxy always stays below 50% CPU, no matter the increasing number of threads/connections, scaling the load very efficiently.
This separation aims to streamline transaction write logging, improving efficiency and consistency. It becomes more manageable and efficient by isolating logs and data to a dedicated mount. Benchmarking AWS RDS DLV setup Setup 2 RDS Single DB instances 1 EC2 Instance Regular DLV Enabled Sysbench db.m6i.2xlarge
Once inside the function, there's nothing wrong with multi-threading to do the work as efficiently as possible. Matthew Dillon : This is *very* impressive efficiency. This is *very* impressive efficiency. @sapessi : Lambda simplifies concurrency at the frontend, enforcing one event per function at a time.
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. There are three generations of GPUs that are relevant to this comparison. Various benchmarks show improvements of 1.4x
In this comparison of Redis vs Memcached, we strip away the complexity, focusing on each in-memory data store’s performance, scalability, and unique features. Snapshots provide point-in-time captures of the dataset, which are efficient for recovery on startup.
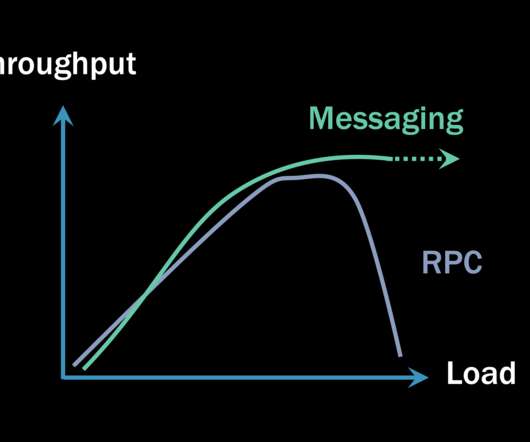
It’s less of an apples-to-oranges comparison and more like apples-to-orange-sherbet. Why RPC is “faster” It’s tempting to simply write a micro-benchmark test where we issue 1000 requests to a server over HTTP and then repeat the same test with asynchronous messages. But the answer isn’t that simple. Messaging doesn’t do that.
The challenging thing of course, is efficiently maintaining all of these parallel universes. A space- and compute-efficient multiverse database clearly cannot materialize all user universes in their entirety, and must support high-performance incremental updates to the user universes. Expressing privacy policies.
HammerDB is a software application for database benchmarking. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking. The Transaction Processing Performance Council (TPC) was founded to bring standards to database benchmarking, and the history of the TPC can be found here.
In this blog post, we will review key topics to consider for managing large datasets more efficiently in MySQL. Redundant indexes: It is known that accessing rows by fetching an index is more efficient than through a table scan in most cases. It can help us to save costs on storage and backup times.
we also: Launched a series of new and improved dashboards to help you identify and fix your performance issues more quickly and efficiently (More on those below.). Your current competitive benchmarks status. With your RUM Compare dashboard , you can easily generate side-by-side comparisons for any two cohorts of real user data.
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. All modern browsers are fast, Chromium and Safari/WebKit included. CSS Custom Paint.
Both these techniques use vector data rather than pixels so they are small in file size and scale efficiently across all sizes including high resolution retina screens. Comparison of page size and assets types across different responsive widths. Alternatively use SVG images for logos and other simple graphics. Source: SpeedCurve.
Here’s some predictions I’m making: Jack Dongarra’s efforts to highlight the low efficiency of the HPCG benchmark as an issue will influence the next generation of supercomputer architectures to optimize for sparse matrix computations. In comparison, for Linpack Frontier operates at 68% of peak capacity. of peak capacity.
For example, the IMDG must be able to efficiently create millions of objects in each server to make use of its huge storage capacity. It was tempting to write this blog post as a feature comparison between AppFabric and SOSS. Testing Scale-Up Performance. In Summary: Design for Ease of Use and High Performance.
Pointer arithmetic, loop index increments, loop trip count comparisons, and conditional branches are all essentially “free” on mainstream Xeon processors, but have to be considered very carefully on the Xeon Phi x200. 8.056 0.056 75.0% 74.48% 0.70% 2 24 3 27 13.5 7.086 0.086 85.71% 84.67% 1.22% 4 48 3 51 12.75 FMAs/cycle.
Pointer arithmetic, loop index increments, loop trip count comparisons, and conditional branches are all essentially “free” on mainstream Xeon processors, but have to be considered very carefully on the Xeon Phi x200. A “best case” scenario: DGEMM. 1 12 3 15 15 15.0156 8.0 8.056 0.056 75.0% 74.48% 0.70%. 2 24 3 27 13.5
KB boundaries efficiently. Although SQL Server tries to use the log space as efficiently as possible, certain application patterns cause the log-block fill percentages to remain small. This creates 8?KB
Alternatively, you can also use: Addy Osmani’s Chrome UX Report Compare Tool , Speed Scorecard (also provides a revenue impact estimator), Real User Experience Test Comparison or SiteSpeed CI (based on synthetic testing). Geekbench CPU performance benchmarks for the highest selling smartphones globally in 2019. compared to early 2015.
Alternatively, you can also use Speed Scorecard (also provides a revenue impact estimator), Real User Experience Test Comparison or SiteSpeed CI (based on synthetic testing). Paddy Ganti’s script constructs two URLs (one normal and one blocking the ads), prompts the generation of a video comparison via WebPageTest and reports a delta.
To efficiently utilize our compute resources, Titus employs a CPU oversubscription feature , meaning the combined virtual CPUs allocated to containers exceed the number of available physical CPUs on a Titus agent. In comparison, the terminal handler used only 0.47% CPU time. is spent on a function called __parse_smaps_rollup.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content