This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As software engineers, we are always striving for high performance and efficiency in our code. Whether it’s optimizing algorithms or fine-tuning data structures, every decision we make can have a significant impact on the overall performance of our applications.
They are part of continuous delivery pipelines and examine code to find vulnerabilities. There is another critical element that needs to be addressed: how do you protect applications against attacks exploiting vulnerabilities while DevSecOps teams simultaneously try to resolve those issues in the code ?
Likewise, refactoring and rewriting code takes a lot of time and effort. In fact, it can be difficult to make code changes that won’t disrupt the entire system. Monitor the application before, during, and after migration Migrating and changing code can be a tricky business. Migration is time-consuming and involved.
Dynatrace has offered a Lambda code module for Node.js In theory, an existing code module or agent can be used to monitor a Lambda function if there’s a way to load it into the running Lambda process. Dynatrace tackled these challenges by writing our Lambda code module from scratch to include the following: A small file size.
It shows which code paths are more busy on the CPU in given samples. Manual flame graphs collection Although the tool is excellent and automatically provides flame graphs, we don’t have much control over tuning the selected profiler. Flame graphs are a graphical representation of function calls.
With Dynatrace, you can also validate your findings against Real User Monitoring data or even drill down to the code level to pinpoint the root cause of a change in performance. This is definitely a great starting benchmark against which to optimize your application. Google considers an LCP of less than 2.5
Compare ease of use across compatibility, extensions, tuning, operating systems, languages and support providers. Oracle requires more complex ongoing administration, as all database configurations must evolve in conjunction with the data schemas and custom code. Compare Ease of Use.
In short, Lambda functions can take on almost all of the operational duties of running an application; all you need to do is provide the code that should be executed on a given event or trigger. These served as our benchmark when creating our Lambda monitoring extension. So, stay tuned for more blog posts and announcements.
In short, Lambda functions can take on almost all of the operational duties of running an application; all you need to do is provide the code that should be executed on a given event or trigger. These served as our benchmark when creating our Lambda monitoring extension. So, stay tuned for more blog posts and announcements.
In addition, we were able to perform a handful of A/B tests to validate or negate our hypotheses for tuning the search experience. In summary, this model was a tightly-coupled application-to-data architecture, where machine learning algos were mixed with the backend and UI/UX software code stack.
I have a lot of historical data using my ReadOnly benchmark (as described in some of the earliest entries in this blog [link] A read-only access pattern removes the need to understand and explain the many complexities associated with the “streaming stores” typically used in the STREAM benchmark (e.g., Stay tuned!
Evaluation : How do we evaluate such systems, especially when outputs are qualitative, subjective, or hard to benchmark? This is often surprising to engineers coming from traditional software or data infrastructure backgrounds who may not be used to thinking about validation plans until after the code is written. How do we do so?
Key metrics like throughput, request latency, and memory utilization are essential for assessing Redis health, with tools like the MONITOR command and Redis-benchmark for latency and throughput analysis and MEMORY USAGE/STATS commands for evaluating memory. <code> 127.0.0.1:6379> <code> 127.0.0.1:6379>
Some of these examples have been hand-tuned to make them efficient for TLC to check, no such tuning is done for APALACHE. 4 seconds on this same benchmark). We hope that with the growing number of users, specifications will get tuned to our model checker, as is now happening with TLC. But when TLC starts to struggle (e.g.,
We believe the only way to maintain and scale our standards is to focus on quality code. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Bridgecrew is the cloud security platform for developers. Get started for free!
Systems researchers are doing an excellent job improving the performance of 5-year old benchmarks, but gradually making it harder to explore innovative machine learning research ideas. Named dimensions improve readability by making it easier to determine how dimensions in the code correspond to the semantic dimensions described in,e.g.,
We believe the only way to maintain and scale our standards is to focus on quality code. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Bridgecrew is the cloud security platform for developers. Get started for free!
We believe the only way to maintain and scale our standards is to focus on quality code. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Bridgecrew is the cloud security platform for developers. Get started for free!
We believe the only way to maintain and scale our standards is to focus on quality code. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search. Bridgecrew is the cloud security platform for developers. Get started for free!
The broken Java stacks turned out to be beneficial: They helped group together the os::javaTimeMillis() calls which otherwise might have have been scattered on top of different Java code paths, appearing as thin stacks everywhere. Without NMI, some kernel code paths (interrupts disabled) can't be profiled. But I'm not completely sure.
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
In this post I'll look at the Linux kernel page table isolation (KPTI) patches that workaround Meltdown: what overheads to expect, and ways to tune them. I then analyzed performance during the benchmark ([active benchmarking]), and used other benchmarks to confirm findings. Much of my testing was on Linux 4.14.11
Co-founder Eliot Horowitz recounts ( {coding}bootcamps.io ): “MongoDB was born out of our frustration using tabular databases in large, complex production deployments. Though still not “profitable” by many benchmarks, it’s a lot closer to being so, perhaps in a big way.) looking out for MongoDB Inc.
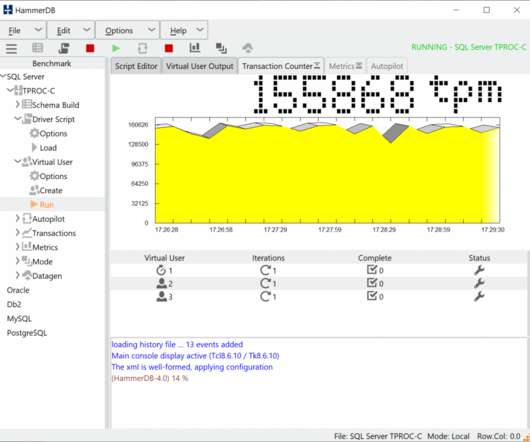
HammerDB is a load testing and benchmarking application for relational databases. However, it is crucial that the benchmarking application does not have inherent bottlenecks that artificially limits the scalability of the database. Basic Benchmarking Concepts. To benchmark a database we introduce the concept of a Virtual User.
If you’re reading this, chances are you’ve played around with using AI tools like ChatGPT or GitHub Copilot to write code for you. So far I’ve read a gazillion blog posts about people’s experiences with these AI coding assistance tools. or “ha look how incompetent it is … it couldn’t even get my simple question right!”
Adopting Infrastructure as Code (IaaC) makes transitioning to a multi-cloud architecture more efficient, allowing streamlined setup processes. Consistently evaluating and tuning resource allocations based on use patterns helps prevent overprovisioning and reduces unnecessary expenses.
The in-depth explorations are meticulously illustrated and code examples culminate as bulletproof code snippets, applicable to your work right away. In her book, Lara Hogan helps you approach projects with page speed in mind, showing you how to test and benchmark which design choices are most critical. Web Performance Tuning.
I have a lot of historical data using my ReadOnly benchmark (as described in some of the earliest entries in this blog [link] A read-only access pattern removes the need to understand and explain the many complexities associated with the “streaming stores” typically used in the STREAM benchmark (e.g., Stay tuned!
Source: Guy Podjarny However, we do now have a full set of techniques to effectively deliver highly performative sites that not only visually scale across devices but also deliver code and assets tuned to the width of a device. Go mobile first and performance first when designing and coding your next responsive website!
With entrance into the industry being so easy and lack of proper benchmarking (Note: this is somewhat contradictory to point 2, but more on that later) around what makes a good designer, software engineer, or product manager, we’re forced to face the facts that it’s a recipe for poor quality products. Stay tuned! Large preview ).
In this post I'll look at the Linux kernel page table isolation (KPTI) patches that workaround Meltdown: what overheads to expect, and ways to tune them. I then analyzed performance during the benchmark ([active benchmarking]), and used other benchmarks to confirm findings. Much of my testing was on Linux 4.14.11
The broken Java stacks turned out to be beneficial: They helped group together the os::javaTimeMillis() calls which otherwise might have have been scattered on top of different Java code paths, appearing as thin stacks everywhere. Without NMI, some kernel code paths (interrupts disabled) can't be profiled. But I'm not completely sure.
When you own all of the code then this may involve some back of the envelope estimates, competitive benchmarking, or intuition tuned by experience. VsChromium is a Visual Studio extension that keeps all of the source code in a monitored directory loaded into RAM. We know that this code is running too slow.
A peculiar throughput limitation on Intel’s Xeon Phi x200 (Knights Landing) Introduction: In December 2017, my colleague Damon McDougall (now at AMD) asked for help in porting the fused multiply-add example code from a Colfax report ( [link] ) to the Xeon Phi x200 (Knights Landing) processors here at TACC.
Introduction: In December 2017, my colleague Damon McDougall (now at AMD) asked for help in porting the fused multiply-add example code from a Colfax report ( [link] ) to the Xeon Phi x200 (Knights Landing) processors here at TACC. of the “adjusted peak performance”, there is no longer a significant upside to performance tuning.
For anyone benchmarking MySQL with HammerDB it is important to understand the differences from sysbench workloads as HammerDB is targeted at a testing a different usage model from sysbench. As is also the case this limitation is at the database level (especially the storage engine) rather than the hardware level. Configure MySQL. monitoring.
For specific information on I/O tuning and balancing, you will find more details in the following document. The following example is a code example taken from the following Microsoft Knowledge Base article. The page number on the page read from disk is not the expected page ID.
Another big jump, but now it was my job to run benchmarks in the lab, and write white papers that explained the new products to the world, as they were launched. I was mostly coding in C, tuning FORTRAN, and when I needed to do a lot of data analysis of benchmark results used the S-PLUS statistics language, that is the predecessor to R.
She also teaches for Black Girls Code, and she founded the Dallas chapter of Girl Develop It and DFW Sass. He has a keen interest in web technologies, performance tuning, security, and the practical use of technology. He’s also the author of HTTP/2 in Action , a complete guide to HTTP/2. Doug Sillars. Doug Sillars. Estelle Weyl.
The following code example shows the setting of values in illegal array positions. 2000, and 2005 - replaced with SQLIOSim)
Java used to power core file system code. Python used to power client-side code, certain microservices, migration scripts, internal scripts. We use event-based sync in our desktop sync client code, as server events are happening they get pushed to the client from server and the client replays them locally.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content