This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
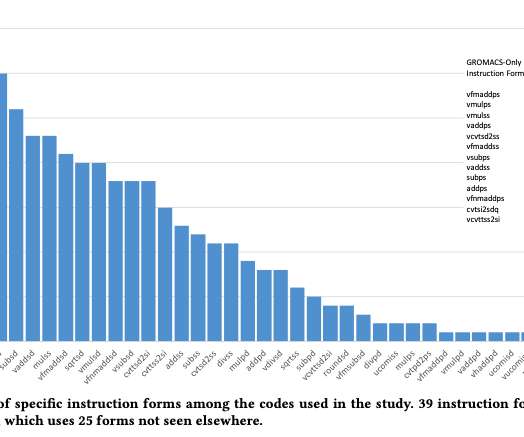
The division by a power of two ( / (2 N )) can be implemented as a right shift if we are working with unsigned integers, which compiles to single instruction: that is possible because the underlying hardware uses a base 2. We also published our benchmarks for research purposes. I make my benchmarkingcode available.
To create a CPU core that can execute a large number of instructions in parallel, it is necessary to improve both the architecturewhich includes the overall CPU design and the instruction set architecture (ISA) designand the microarchitecture, which refers to the hardware design that optimizes instruction execution.
One, by researching on the Internet; Two, by developing small programs and benchmarking. According to other comparisons [Google for 'Performance of Programming Languages'] spread over the net, they clearly outshine others in all speed benchmarks. The legacy languages — be it ASM or C still rule in terms of performance. Ahem, Slow!
Limits of a lift-and-shift approach A traditional lift-and-shift approach, where teams migrate a monolithic application directly onto hardware hosted in the cloud, may seem like the logical first step toward application transformation. Likewise, refactoring and rewriting code takes a lot of time and effort.
Dynatrace OneAgent deployment and life-cycle management are already widely considered to be industry benchmarks for reliability and efficiency. Dynatrace news. OneAgents can be deployed via a single command execution or a double-click. because the OneAgent modules injected there are effectively owned by the respective users.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., A typical architecture diagram for one of these services looks like this: Suitably armed with a set of benchmark microservices applications, the investigation can begin! Hardware implications.
First, its origin was in a monoculture (the browser) wher e there was no need for compatibility with legacy code. Unfortunately, languages like Python have proven resistant to efficient implementation, partly because of their design, and partly because of limitations imposed by the need to interop with C code. MICRO 15 , Gope et al.,
Furthermore, as hardware and compiler optimisations rapidly evolve, it is challenging even for a knowledgeable developer to keep up. The study is conducted using a suite of 7 real-world popular scientific applications, and two well-established benchmark suites: Miniaero solves the compressible Navier-Stokes equation. lines of code.
Verifying benchmark claims. I picked these examples because they aren't operations that show up in standard data warehousing benchmarks, yet are meaningful parts of customer workloads. Verifying benchmark claims. I've noticed a troubling trend in vendor benchmarking claims over the past year.
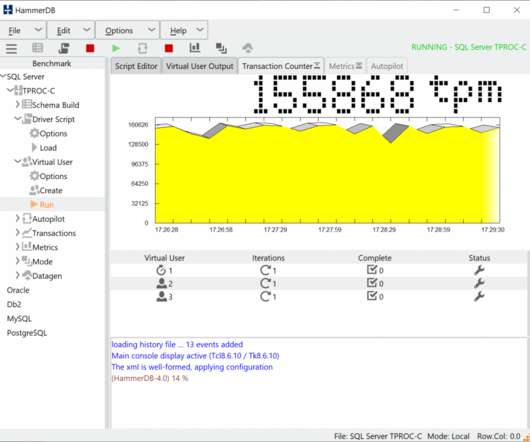
HammerDB uses stored procedures to achieve maximum throughput when benchmarking your database. HammerDB has always used stored procedures as a design decision because the original benchmark was implemented as close as possible to the example workload in the TPC-C specification that uses stored procedures.
Oracle requires more complex ongoing administration, as all database configurations must evolve in conjunction with the data schemas and custom code. Oracle support for hardware and software packages is typically available at 22% of their licensing fees. So Which Is Best?
Apart from library code, maybe your application doesn't have frame pointers either, in which case everything is broken. Only in extreme circumstances does the cost (in processor time and I-cache footprint) translate to a tangible benefit - circumstances which usually resort to hand-coded assembly anyway.
Defining high availability In general terms, high availability refers to the continuous operation of a system with little to no interruption to end users in the event of hardware or software failures, power outages, or other disruptions. If a primary server fails, a backup server can take over and continue to serve requests.
I have a lot of historical data using my ReadOnly benchmark (as described in some of the earliest entries in this blog [link] A read-only access pattern removes the need to understand and explain the many complexities associated with the “streaming stores” typically used in the STREAM benchmark (e.g., Stay tuned!
Key metrics like throughput, request latency, and memory utilization are essential for assessing Redis health, with tools like the MONITOR command and Redis-benchmark for latency and throughput analysis and MEMORY USAGE/STATS commands for evaluating memory. <code> 127.0.0.1:6379> <code> 127.0.0.1:6379>
This type of database offers scalability with no downtime along with giving businesses control over what resources they use through customization capabilities such as choosing hardware infrastructure options or building security measures around it. These advantages come at an expense.
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. is access to hardware devices. This is as it should be. Compression Streams.
Some of the most important elements include: No single point of failure (SPOF): You must eliminate any SPOF in the database environment, including any potential for an SPOF in physical or virtual hardware. Redundancy provides backups and safeguards against data loss in case of hardware failures. there cannot be high availability.
Last week we saw the benefits of rethinking memory and pointer models at the hardware level when it came to object storage and compression ( Zippads ). The protections are hardware implemented and cannot be forged in software. code is not given access to excessive capabilities. ASPLOS’19. CHERI implementation.
The broken Java stacks turned out to be beneficial: They helped group together the os::javaTimeMillis() calls which otherwise might have have been scattered on top of different Java code paths, appearing as thin stacks everywhere. Without NMI, some kernel code paths (interrupts disabled) can't be profiled. But I'm not completely sure.
Systems researchers are doing an excellent job improving the performance of 5-year old benchmarks, but gradually making it harder to explore innovative machine learning research ideas. Named dimensions improve readability by making it easier to determine how dimensions in the code correspond to the semantic dimensions described in,e.g.,
HammerDB is a software application for database benchmarking. It enables the user to measure database performance and make comparative judgements about database hardware and software. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking. Derived Workloads.
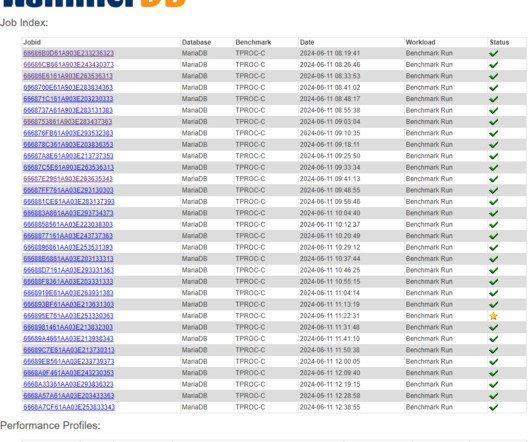
In a recent project comparing systems for MariaDB performance, a user had originally been using a tool called sysbench-tpcc to compare hardware platforms before migrating to HammerDB. This is a brief post to highlight the metrics to use to do the comparison using a separate hardware platform for illustration purposes. hammerdbcli auto./scripts/tcl/maria/tprocc/maria_tprocc_build.tcl
HammerDB is a load testing and benchmarking application for relational databases. However, it is crucial that the benchmarking application does not have inherent bottlenecks that artificially limits the scalability of the database. Basic Benchmarking Concepts. To benchmark a database we introduce the concept of a Virtual User.
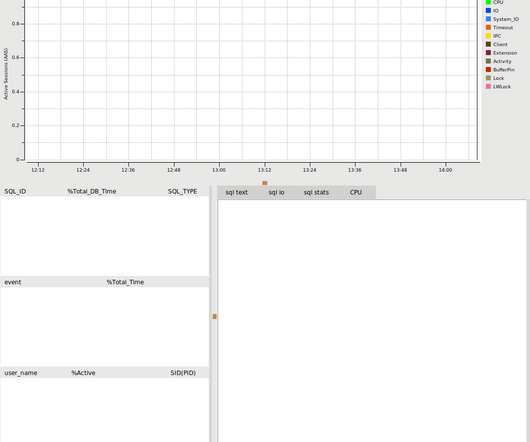
This enables the user to compare and contrast performance across different benchmark scenarios. The events are colour coded and indexed in the graph to the wait event groups. Metrics view for benchmark. PostgreSQL Graphical Metrics. Install pg_stat_statements and pg_sentinel extensions.
Budgets are scaled to a benchmark network & device. For this page to be done loading it needs to be responsive to user input — the “interactive” in “Time to Interactive” Browsers process user input by generating DOM events that application code listens to. Execute the script. Global Ground-Truth.
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
Arguably, the most common beginning errors with database benchmarking is for a user to select a single point of utilisation (usually overconfigured) and then extrapolate conclusions about system performance from this single point. Copy Code Copied Use a different Browser #!/bin/tclsh
On August 7, 2019, AMD finally unveiled their new 7nm EPYC 7002 Series of server processors, formerly code-named "Rome" at the AMD EPYC Horizon Event in San Francisco. It will also use less power than a two-socket Intel server, with a lower hardware cost, and potentially lower licensing costs (for things like VMware).
When we released Always On Availability Groups in SQL Server 2012 as a new and powerful way to achieve high availability, hardware environments included NUMA machines with low-end multi-core processors and SATA and SAN drives for storage (some SSDs). As we moved towards SQL Server 2014, the pace of hardware accelerated.
More importantly, if this works out well, this could lead to a radical improvement in performance by leveraging hardware trends such as GPUs and TPUs. The benchmarking was performed using 3 real-world data sets (weblogs, maps, and web-documents), and 1 synthetic dataset (lognormal). Learned indexes.
I have a lot of historical data using my ReadOnly benchmark (as described in some of the earliest entries in this blog [link] A read-only access pattern removes the need to understand and explain the many complexities associated with the “streaming stores” typically used in the STREAM benchmark (e.g., Stay tuned!
The broken Java stacks turned out to be beneficial: They helped group together the os::javaTimeMillis() calls which otherwise might have have been scattered on top of different Java code paths, appearing as thin stacks everywhere. Without NMI, some kernel code paths (interrupts disabled) can't be profiled.
A peculiar throughput limitation on Intel’s Xeon Phi x200 (Knights Landing) Introduction: In December 2017, my colleague Damon McDougall (now at AMD) asked for help in porting the fused multiply-add example code from a Colfax report ( [link] ) to the Xeon Phi x200 (Knights Landing) processors here at TACC.
Introduction: In December 2017, my colleague Damon McDougall (now at AMD) asked for help in porting the fused multiply-add example code from a Colfax report ( [link] ) to the Xeon Phi x200 (Knights Landing) processors here at TACC. Instead, we found puzzle after puzzle. Instead, we found puzzle after puzzle.
The broken Java stacks turned out to be beneficial: They helped group together the os::javaTimeMillis() calls which otherwise might have have been scattered on top of different Java code paths, appearing as thin stacks everywhere. Without NMI, some kernel code paths (interrupts disabled) can't be profiled. But I'm not completely sure.
As is also the case this limitation is at the database level (especially the storage engine) rather than the hardware level. For anyone benchmarking MySQL with HammerDB it is important to understand the differences from sysbench workloads as HammerDB is targeted at a testing a different usage model from sysbench. Configure MySQL.
Understanding DBaaS DBaaS cloud services allow users to use databases without configuring physical hardware and infrastructure or installing software. Doing extensive benchmarks will be the subject of a future blog post. In any case, you should benchmark both RDS MySQL and Aurora before taking the decision to migrate.
Example 1: Hardware failure (CPU board) Battery backup on the caching controller maintained the data. Important Always consult with your hardware manufacturer for proper stable media strategies. Mirroring can be implemented at a software or hardware level.
HTML, CSS, images, and fonts can all be parsed and run at near wire speeds on low-end hardware, but JavaScript is at least three times more expensive, byte-for-byte. Most sorts of sites have shallow sessions, making up-front script costs hard to justify.
I became the Sun UK local specialist in performance and hardware, and as Sun transitioned from a desktop workstation company to sell high end multiprocessor servers I was helping customers find and fix scalability problems. We had specializations in hardware, operating systems, databases, graphics, etc.
The following code example shows the setting of values in illegal array positions. scid=kb ; en-us;828339 ) on the Microsoft Web site.
Is it worth exploring tree-shaking, scope hoisting, code-splitting, and all the fancy loading patterns with intersection observer, server push, clients hints, HTTP/2, service workers and — oh my — edge workers? It’s much easier to reach performance goals when the code base is fresh or is just being refactored.
Have we optimized enough with tree-shaking, scope hoisting, code-splitting, and all the fancy loading patterns with intersection observer, progressive hydration, clients hints, HTTP/3, service workers and — oh my — edge workers? It’s much easier to reach performance goals when the code base is fresh or is just being refactored.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content