This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Since the DB is small (50% the size of the Linux RAM) – the database is mostly cached on the read side – so we only see writes going to the DB files. The post View from Nutanix storage during Postgres DB benchmark appeared first on n0derunner. The other is doing reads and writes from the main datafiles.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 In MySQL, considering the standard storage engine, InnoDB , the data cache is called Buffer Pool. In PostgreSQL, it is called shared buffers.
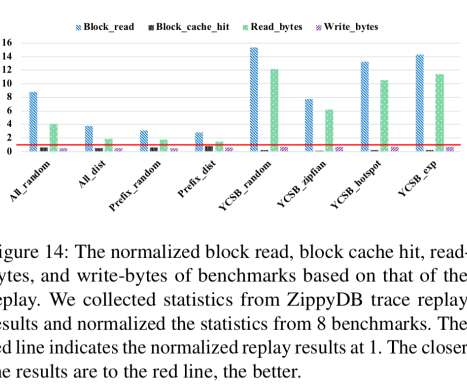
Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook , Cao et al., Or in the case of key-value stores, what you benchmark. So if you want to design a system that will offer good real-world performance, it’s really useful to have benchmarks that accurately represent real-world workloads.
Key metrics like throughput, request latency, and memory utilization are essential for assessing Redis health, with tools like the MONITOR command and Redis-benchmark for latency and throughput analysis and MEMORY USAGE/STATS commands for evaluating memory. Cache Hit Ratio The cache hit ratio represents the efficiency of cache usage.
By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. Storage The type of storage and disk used for database servers can have a significant impact on performance and reliability. Benchmark before you decide. and MariaDB 10.5.4
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. query cache: Disable (query_cache_size: 0, query_cache_type:OFF) innodb_adaptive_hash_index: Check adaptive hash index usage to determine its efficiency.
In this video I migrate a Postgres DB running PGbench benchmark. As the DB continues to run on the new host – the Nutanix storage detects the access patterns and “localizes” the data that the DB is accessing. Many different queries are executing in parallel, some hitting RAM cache, some hitting storage.
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
PMM2 uses VictoriaMetrics (VM) as its metrics storage engine. Please note that the focus of these tests was around standard metrics gathering and display, we’ll use a future blog post to benchmark some of the more intensive query analytics (QAN) performance numbers. Virtual Memory utilization was averaging 48 GB of RAM.
IT professionals are familiar with scoping the size of VMs with regards to vCPU, memory, and storage capacity. Memory optimized – High memory-to-CPU ratio, relational database servers, medium to large caches, and in-memory analytics. Storage optimized – High disk throughput and IO. Premium storage support. Generation.
use the TPC-H benchmark to assess Redshift, Redshift Spectrum, Athena, Presto, Hive, and Vertica to find out what works best and the trade-offs involved. For cost calculations, the costs are a combination of compute costs, storage costs, data scan costs, and software license costs. Key findings. System initialisation time.
After the “data dictionary” (DD) engine and DD cache are initialized on a server, the Storage Engines can ask for a table definition. Initializing a DD engine and the cache adds complexity and other server dependencies. Essentially LRU cache is disabled by loading the tables as non-evictable. ibd > t1.sdi
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
For example, the IMDG must be able to efficiently create millions of objects in each server to make use of its huge storage capacity. Given all this, we thought it would be a good opportunity to see how we are doing relative to the competition, and in particular, relative to Microsoft’s AppFabric caching for Windows on-premise servers.
HammerDB is a software application for database benchmarking. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking. The Transaction Processing Performance Council (TPC) was founded to bring standards to database benchmarking, and the history of the TPC can be found here.
As database performance is heavily influenced by the performance of storage, network, memory, and processors, we must understand the upper limit of these key components. For storage, FIO is generally used. Benchmarking the target Two of the more popular database benchmarks for MySQL are HammerDB and sysbench. 0.42 %sys 9.52
NOTE : All tests were applied for MySQL version 8.0.30, and in the background, I ran every query three to five times to make sure that all of them were fully cached in the buffer pool (for InnoDB) or by the filesystem (for MyISAM). But why we can’t just cache the actual number of the rows?
This removes the burden of purchasing and maintaining your hardware, storage and networking infrastructure, while still giving you a very familiar experience with Windows and SQL Server itself. There are also large differences in storage capacity and throughput between these extremes. GHz, 128MB of L3 cache, 128 PCIe 4.0
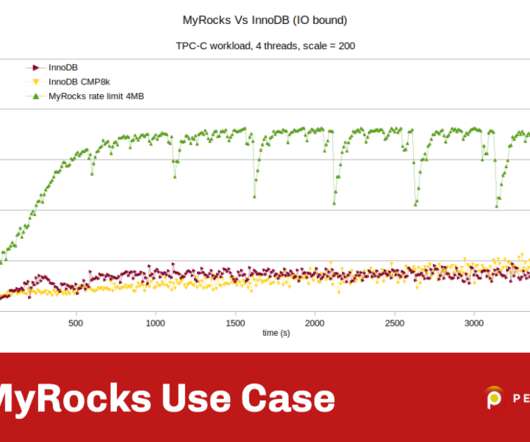
I wrote this post on MyRocks because I believe it is the most interesting new MySQL storage engine to have appeared over the last few years. The use case is the TPC-C benchmark but executed not on a high-end server but on a lower-spec virtual machine that is I/O limited like for example, with AWS EBS volumes. Conclusion.
If we do that naively though, we’re going to end up with a lot of universes to store and maintain and the storage requirements alone will be prohibitive. The amount of computation required on a base update can be reduced by sharing computation and cached data between universes.
A 2007 paper, that still has lots to say on the subject of benchmarkingstorage and filesystems. Primarily aimed at researchers and developers, but is relevant to anyone about to embark on a benchmarking effort. A Nine year study of filesystem and storagebenchmarking Download. The post New (Old) Paper.
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. Chrome has missed several APIs for 3+ years: Storage Access API.
The HBO sitcom Silicon Valley hilariously followed Pied Piper, a team of developers with startup dreams to create a compression algorithm so powerful that high-quality streaming and file storage concerns would become a thing of the past. In my benchmarks, Brotli:11 takes several hundred milliseconds to compress a single minified jQuery file.
This post at an entry-level discusses the options you have to improve log throughput in your benchmark environment. . To illustrate the data reads on Oracle we can flush the buffer cache. Consequently we now need to increase the buffer cache in size if we are to see more CPU activity. so what are your options? PostgreSQL.
Creating a HCI benchmark to simulate multi-tennent workloads. As with traditional storage, applications are writing to a shared storage environment which is necessary to support VM movement. As with traditional storage, applications are writing to a shared storage environment which is necessary to support VM movement.
Back on December 5, 2017, Microsoft announced that they were using AMD EPYC 7551 processors in their storage-optimized Lv2-Series virtual machines. The L3 cache size is 64MB. I wrote about using CPU-Z to benchmark the Intel Xeon E5-2673 v3 processor in an Azure VM in this article. Figure 1: CPU-Z Benchmark Results for LS16v2.
” Here are additional metrics used to determine the reliability of a database, make adjustments that minimize downtime, and set benchmarks for meeting business continuity requirements. Depending on your setup, costs can include: Hardware devices (servers, storage devices, network switches, etc.)
Hardware optimization : You need to ensure that the CPU, memory, and storage components meet the performance requirements of the database workload. Connection pooling: Minimizing connection overhead and improving response times for frequently accessed data by implementing mechanisms for connection pooling and caching strategies.
Budgets are scaled to a benchmark network & device. Deciding what benchmark to use for a performance budget is crucial. Simulated packet loss and variable latency, however, can make benchmarking extremely difficult and slow. Time required to read bytes from disk (it’s not zero, even on flash-based storage!).
Inadequate CPU, memory, or storage can lead to bottlenecks and performance degradation, so remedying these issues involves upgrading hardware or optimizing resource utilization through query and server configuration adjustments. Avoid over-indexing, which can bloat storage and slow writes.
Stable Media Stable media is often confused with physical storage. SQL Server defines stable media as storage that can survive system restart or common failure. Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well.
On your first try, you can use it as a benchmark for optimizations later. Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved. Caching partially stores your data and is not used as permanent storage.
A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. Using a global ASP as a benchmark can further mislead thanks to the distorting effect of ultra-high-end prices rising while shipment volumes stagnate. The Moto G4 , for example.
Geekbench CPU performance benchmarks for the highest selling smartphones globally in 2019. The idea is quite straightforward: Push the minimal code needed to get interactive for the initial route to render quickly, then use service worker for caching and pre-caching resources and then lazy-load routes that you need, asynchronously.
It is limited by the disk space; it can’t expand storage elastically; it chokes if you run few I/O intensive processes or try collaborating with 100 other users. Over time, costs for S3 and GCS became reasonable and with Egnyte’s storage plugin architecture, our customers can now bring in any storage backend of their choice.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content