This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Our STRAIGHT compiler, built on LLVM, has reached a level where it can compile and correctly execute all benchmarks from SPEC CPU2017, a widely used standard for evaluating CPU performance. The era of processors adopting distance-based instruction sets might be closer than you think.
Key metrics like throughput, request latency, and memory utilization are essential for assessing Redis health, with tools like the MONITOR command and Redis-benchmark for latency and throughput analysis and MEMORY USAGE/STATS commands for evaluating memory. Cache Hit Ratio The cache hit ratio represents the efficiency of cache usage.
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
Compress objects, not cache lines: an object-based compressed memory hierarchy Tsai & Sanchez, ASPLOS’19. Existing cache and main memory compression techniques compress data in small fixed-size blocks, typically cache lines. ” The big idea.
By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. Operatingsystem Linux is the most common operatingsystem for high-performance MySQL servers. Benchmark before you decide. Transparent huge pages (THP) disabled.
The PostgreSQL buffer is called shared_buffer which is the most effective tunable parameter for most operatingsystems. This parameter sets how much dedicated memory will be used by PostgreSQL for cache. It’s low because certain machines and operatingsystems do not support higher values. wal_buffers.
It is typically reduced via server-side optimizations, such as enabling caching and database indexes. However, we really want to strive to be under the benchmarks that Google sets as a best practice. Even better if you’re under Google’s best practice benchmark. seconds on desktop and 2.59 seconds on mobile.
HammerDB is a software application for database benchmarking. HammerDB has graphical and command line interfaces for the Windows and Linux operatingsystems. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking. Cached vs Scaled Workloads.
Given all this, we thought it would be a good opportunity to see how we are doing relative to the competition, and in particular, relative to Microsoft’s AppFabric caching for Windows on-premise servers. One or more specified cache servers are unavailable, which could be caused by busy network or servers. …). Please retry later.
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
Today, the website is much faster and ranks highly in various showcases and benchmarks. And while you can usually cache the full page of an article, the same is not true of many shop pages and elements. This way, the file can be cached on the server and in the browser, and no superfluous SVGs will need to be interpreted.
All of the SPECfp_rate2000 results were downloaded from www.spec.org, the results were sorted by processor type, and “peak floating-point operations per cycle” was manually added for each processor type. This includes all architectures, all compilers, all operatingsystems, and all system configurations.
You will still have to maintain your operatingsystem, SQL Server and databases just like you would in an on-premises scenario. Microsoft's Mine Tokus has a good article where she ran a series of scaled down TPC-E benchmarks against an E64s_v3 VM that was using the older Broadwell processor. GHz, 128MB of L3 cache, 128 PCIe 4.0
Connection pooling: Minimizing connection overhead and improving response times for frequently accessed data by implementing mechanisms for connection pooling and caching strategies. PostgreSQL performance optimization is an ongoing process involving monitoring, benchmarking, and adjustments to maintain high-performing PostgreSQL databases.
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
All of the SPECfp_rate2000 results were downloaded from www.spec.org, the results were sorted by processor type, and “peak floating-point operations per cycle” was manually added for each processor type. This includes all architectures, all compilers, all operatingsystems, and all system configurations.
on Myths and Legends of High Performance Computing — it’s a somewhat light-hearted look at some of the same issues by the leader of the team that built the Fugaku system I mention below. HPCG is led by Japan’s RIKEN Fugaku system at 16 petaflops, which is 3% of it’s peak capacity. petaflops, which is 0.8% of peak capacity.
Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. This cache is often supported by a battery-powered backup facility.
MANUAL affinity provides the best, top end performance (for benchmarks by utilizing L1 caches) but is susceptible to noisy, CPU neighbors. Allowing the OperatingSystem to schedule the worker on alternate CPUs can eliminate the impact of a noisy neighbor.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., A typical architecture diagram for one of these services looks like this: Suitably armed with a set of benchmark microservices applications, the investigation can begin! ASPLOS’19.
Edge caching. In general, Egnyte connect architecture shards and caches data at different levels based on: Amount of data. Nginx for disk based caching. We employ large scale data filtering algorithms to let large clusters of clients synchronize with Cloud File System. Disk based caching. Hybrid Sync.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







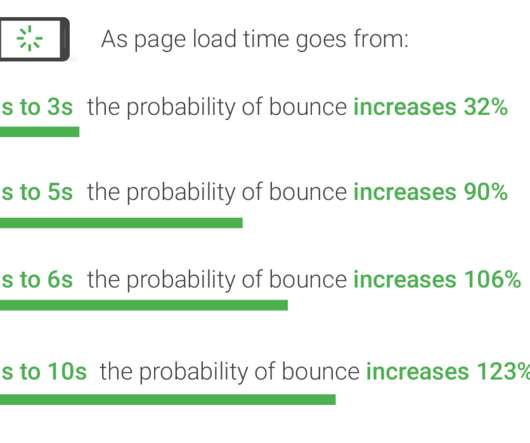



















Let's personalize your content