This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
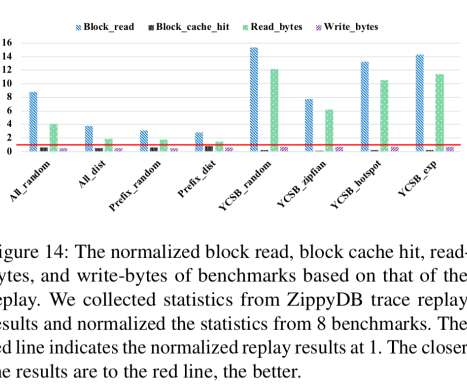
We note that for MongoDB update latency is really very low (low is better) compared to other dbs, however the read latency is on the higher side. The latency table shows that 99th percentile latency for Yugabyte is quite high compared to others (lower is better). Again Yugabyte latency is quite high. Conclusion.
Redis is a great caching solution for highly demanding applications, and there are […]. In fact, it is the number one key value store and eighth most popular database in the world. It has high throughput and runs from memory, but also has the ability to persist data on disk.
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. It can achieve impressive performance, handling up to 50 million operations per second.
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 In MySQL, considering the standard storage engine, InnoDB , the data cache is called Buffer Pool. MySQL (B) 2517529 2610323 389048 5516900 194140 11523.48
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook , Cao et al., Or in the case of key-value stores, what you benchmark. So if you want to design a system that will offer good real-world performance, it’s really useful to have benchmarks that accurately represent real-world workloads.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. query cache: Disable (query_cache_size: 0, query_cache_type:OFF) innodb_adaptive_hash_index: Check adaptive hash index usage to determine its efficiency.
When deciding what to pick, there are many things to consider, like where the proxy needs to be, if it “just” needs to redirect the connections, or if more features need to be in, like caching and filtering, or if it needs to be integrated with some MySQL embedded automation. Given that, there never was a single straight answer.
Most publications have simply reported the benchmark improvement claims, but if you stop to think about them, the numbers dont make sense based on a simplistic view of the technology changes. So first thing to understand is that the benchmark skips a generation and compares product that differs over about a two year interval.
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. Benchmark before you decide. As datasets continue to grow in size, the amount of RAM required to store and process these datasets also increases. Transparent huge pages (THP) disabled.
Looking at the industry benchmarks for US retailers , four well-known sites have backend times that are approaching – or well beyond – that threshold. Pagespeed Benchmarks - US Retail - LCP When you examine a waterfall, it's pretty obvious that TTFB is the long pole in the tent, pushing out render times for the page.
To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It Here I assumed a particular analytical function for the amount of memory traffic as a function of cache size to scale the bandwidth time.
Google’s industry benchmarks from 2018 also provide a striking breakdown of how each second of loading affects bounce rates. Redirects are often pretty light in terms of the latency that they add to a website, but they are an easy first thing to check, and they can generally be removed with little effort. Text-based assets.
use the TPC-H benchmark to assess Redshift, Redshift Spectrum, Athena, Presto, Hive, and Vertica to find out what works best and the trade-offs involved. in the TPC-H Benchmark Standard for details of the queries). Query performance is measured from both warm and cold caches. System initialisation time.
Likewise, object access paths must be heavily multi-threaded and avoid lock contention to minimize access latency and maximize throughput. During load-balancing, the client gets the following exception when accessing the cache: ErrorCode<ERRCA0017>:SubStatus<ES0006>:There is a temporary failure. Please retry later.
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. All modern browsers are fast, Chromium and Safari/WebKit included. Offscreen Canvas.
Here’s some predictions I’m making: Jack Dongarra’s efforts to highlight the low efficiency of the HPCG benchmark as an issue will influence the next generation of supercomputer architectures to optimize for sparse matrix computations. In early January a related paper was published by Satoshi Matsuoka et. petaflops, which is 0.8%
Budgets are scaled to a benchmark network & device. Deciding what benchmark to use for a performance budget is crucial. It simulates a link with a 400ms RTT and 400-600Kbps of throughput (plus latency variability and simulated packet loss). Performance budgets are set early in the life of the project. Global Ground-Truth.
To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It Here I assumed a particular analytical function for the amount of memory traffic as a function of cache size to scale the bandwidth time.
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
This post at an entry-level discusses the options you have to improve log throughput in your benchmark environment. . Additionally for the log disk component it is latency for an individual write that is crucial rather than the total I/O bandwidth. To illustrate the data reads on Oracle we can flush the buffer cache.
Creating a HCI benchmark to simulate multi-tennent workloads. In such a case we have a Bandwidth heavy workload profile (reporting) sharing with a Latency Sensitive workload (transactional). The DB Colocation test utilizes two properties of X-Ray not found in other benchmarking tools. Time based benchmark actions.
The L3 cache size is 64MB. I wrote about using CPU-Z to benchmark the Intel Xeon E5-2673 v3 processor in an Azure VM in this article. Figure 1: CPU-Z Benchmark Results for LS16v2. The L3 cache size is 64MB. They feature low latency, local NVMe storage that can directly leverage the 128 PCIe 3.0 Azure Lsv2 Details.
Last time around we looked at the DeathStarBench suite of microservices-based benchmark applications and learned that microservices systems can be especially latency sensitive, and that hotspots can propagate through a microservices architecture in interesting ways. on end-to-end latency) and less than 0.15% on throughput.
This reduction in latency ensures that applications and websites provide a more rapid and responsive user experience. Efficient memory management, including optimizing query caches and buffer pools, can help strike the right balance between memory consumption and query response times.
Synthetic monitoring actively allows users to monitor the performance of their website or application with a set of controlled variables (geography, network, device, browser, cached vs. uncached) over time. Benchmark Against Competitors.
Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. This cache is often supported by a battery-powered backup facility.
“Memory Bandwidth and System Balance in HPC Systems” If you are planning to attend the SuperComputing 2016 conference in Salt Lake City next month, be sure to reserve a spot on your calendar for my talk on Wednesday afternoon (4:15pm-5:00pm).
So, we pitted the two connection poolers head-to-head, using the standard pgbench tool, to see which one provides better transactions per second throughput through a benchmark test. All of the PostgreSQL benchmark tests were run under the following conditions: Initialized pgbench using a scale factor of 100. Throughput Benchmark.
The Xbox 360 CPU had three PowerPC cores and a 1 MB L2 cache and these features are clearly visible on the wafer. In the die picture to the right (which looks to be about 14 mm by 12 mm) you can see the regular pattern of small black rectangles in the bottom right corner – that’s the L2 cache. I wrote a lot of benchmarks.
On your first try, you can use it as a benchmark for optimizations later. Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved. Caching partially stores your data and is not used as permanent storage.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., A typical architecture diagram for one of these services looks like this: Suitably armed with a set of benchmark microservices applications, the investigation can begin! ASPLOS’19.
A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. Using a global ASP as a benchmark can further mislead thanks to the distorting effect of ultra-high-end prices rising while shipment volumes stagnate. The Moto G4 , for example.
Estimated Input Latency tells us if we are hitting that threshold, and ideally, it should be below 50ms. Designed for the modern web, it responds to actual congestion, rather than packet loss like TCP does, it is significantly faster , with higher throughput and lower latency — and the algorithm works differently.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content