This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Subsequent versions of the model will result from experimenting with hyper parameters, tweaking feature engineering, or conducting feature diets. training Below is a simple Metaflow pipeline that fetches data, executes feature engineering, and trains a LinearRegression model. All environments already cached in s3.
Python is a popular programming language, especially for beginners, and consequently we see it occurring in places where it just shouldn’t be used, such as database benchmarking. We use stored procedures because, as the introductory post shows, using single SQL statements turns our database benchmark into a network test).
Our STRAIGHT compiler, built on LLVM, has reached a level where it can compile and correctly execute all benchmarks from SPEC CPU2017, a widely used standard for evaluating CPU performance. He is a Fellow of the Institute of Electronics, Information and Communication Engineers.
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 In MySQL, considering the standard storage engine, InnoDB , the data cache is called Buffer Pool. In PostgreSQL, it is called shared buffers.
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook , Cao et al., Or in the case of key-value stores, what you benchmark. So if you want to design a system that will offer good real-world performance, it’s really useful to have benchmarks that accurately represent real-world workloads.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
Static analysis of Java enterprise applications: frameworks and caches, the elephants in the room , Antoniadis et al., However, collecting a set of sizable, realistic benchmarks, showing that their analysis is feasible, and making progress in its precision are good ways to ensure further research in this high-value area.
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
After the “data dictionary” (DD) engine and DD cache are initialized on a server, the Storage Engines can ask for a table definition. Initializing a DD engine and the cache adds complexity and other server dependencies. Essentially LRU cache is disabled by loading the tables as non-evictable.
Apple forces developers of competing browsers to use their engine for all browsers on iOS , restricting their ability to deliver a better version of the web platform. They are, pound for pound, some of the best engine developers globally and genuinely want good things for the web. With each team, benchmarks lost are understood as bugs.
This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index. query cache: Disable (query_cache_size: 0, query_cache_type:OFF) innodb_adaptive_hash_index: Check adaptive hash index usage to determine its efficiency.
PMM2 uses VictoriaMetrics (VM) as its metrics storage engine. Please note that the focus of these tests was around standard metrics gathering and display, we’ll use a future blog post to benchmark some of the more intensive query analytics (QAN) performance numbers. Virtual Memory utilization was averaging 48 GB of RAM.
Only in extreme circumstances does the cost (in processor time and I-cache footprint) translate to a tangible benefit - circumstances which usually resort to hand-coded assembly anyway. It shouldn't be 10%, unless it's cache effects. And for leaf routines (which never establish a frame), this is a non-issue.
Also, we find a difference in execution on InnoDB and MyISAM engines. NOTE : All tests were applied for MySQL version 8.0.30, and in the background, I ran every query three to five times to make sure that all of them were fully cached in the buffer pool (for InnoDB) or by the filesystem (for MyISAM).
These have inspired me to summarize another performance activity: evaluating benchmark accuracy. Accurate benchmarking rewards engineering investment that actually improves performance, but, unfortunately, inaccurate benchmarking is more common. If the benchmark reported 20k ops/sec, you should ask: why not 40k ops/sec?
By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way. Benchmark before you decide. As datasets continue to grow in size, the amount of RAM required to store and process these datasets also increases. Transparent huge pages (THP) disabled.
HammerDB is a software application for database benchmarking. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking. The Transaction Processing Performance Council (TPC) was founded to bring standards to database benchmarking, and the history of the TPC can be found here.
Many thanks to the engineers working hard to develop workarounds to these processor bugs. This overhead can be reduced by A) pcid, fully available in Linux 4.14, and B) Huge pages. - **Cache access pattern**: the overheads are exacerbated by certain access patterns that switch from caching well to caching a little less well.
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
The amount of computation required on a base update can be reduced by sharing computation and cached data between universes. The authors have built a prototype implementation of these ideas based on the Noria dataflow engine. Implementing this as a joint partially-stateful dataflow is the key to doing this safely.
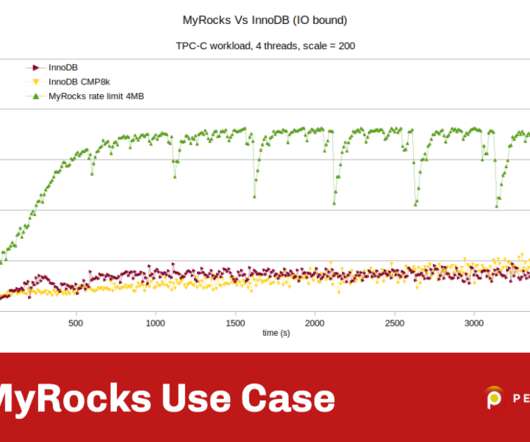
I wrote this post on MyRocks because I believe it is the most interesting new MySQL storage engine to have appeared over the last few years. I wanted most of the memory to be available for the file cache, where the compressed SST files will be cached. I hope this post has raised your interest in the MyRocks storage engine.
The funny thing is that, while being far from a startup, Google does indeed have a powerful compression engine in real life called Brotli. The service categorized all the optimizations in three groups consisting of several “Content,” “Delivery,” and “Cache” optimizations. We only cache hot files in memory at edge servers.
” Here are additional metrics used to determine the reliability of a database, make adjustments that minimize downtime, and set benchmarks for meeting business continuity requirements. Each node has its own cache buffer.) Chaos engineering is designed to uncover unexpected, even shocking, surprises.
This post at an entry-level discusses the options you have to improve log throughput in your benchmark environment. . To illustrate the data reads on Oracle we can flush the buffer cache. Consequently we now need to increase the buffer cache in size if we are to see more CPU activity. so what are your options? PostgreSQL.
Budgets are scaled to a benchmark network & device. We get a strong sense for how bad site performance is going to be based on the percentage of engineering leads, PMs, and decision makers carrying high-end phones which they primarily use in urban areas. Deciding what benchmark to use for a performance budget is crucial.
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
Let the web developer handle all of the necessary speed optimizations like caching and file minification while you take on the following design tips and strategies: 1. As Adam Heitzman said in an article for Search Engine Journal : “Single page sites typically convert much easier to mobile and users find them simple to navigate.”.
Here’s some predictions I’m making: Jack Dongarra’s efforts to highlight the low efficiency of the HPCG benchmark as an issue will influence the next generation of supercomputer architectures to optimize for sparse matrix computations. In early January a related paper was published by Satoshi Matsuoka et. petaflops, which is 0.8%
Efficient memory management, including optimizing query caches and buffer pools, can help strike the right balance between memory consumption and query response times. Key parameters like the buffer pool size significantly impact efficiency by determining how much data MySQL can cache in memory for rapid access.
For example, in a case study published by Gilt Groupe , Eric Shepherd, who was formerly Gilt’s principal front end engineer, noted that: Both RUM and synthetic monitoring give different views of our performance, and are useful for different things. Benchmark Against Competitors. About Rigor.
Many thanks to the engineers working hard to develop workarounds to these processor bugs. This overhead can be reduced by A) pcid, fully available in Linux 4.14, and B) Huge pages. - **Cache access pattern**: the overheads are exacerbated by certain access patterns that switch from caching well to caching a little less well.
Their result is particularly promising for specialized index structures termed as learned indexes which has potential to replace B-Trees without major re-engineering. They demonstrated that neural nets based learned index outperforms cache-optimized B-Tree index by up to 70% in speed while saving an order-of-magnitude in memory.
On your first try, you can use it as a benchmark for optimizations later. An SSR application will generally have templating engines that inject the variables into an HTML when given to the client. Active Memory Caching. Caching partially stores your data and is not used as permanent storage. Caching Schemes.
That meant I started having regular meetings with the hardware engineers who were working with IBM on the CPU which gave me even more expertise on this CPU, which was critical in helping me discover a design flaw in one of its instructions , and in helping game developers master this finicky beast. register files? arithmetic units?)
A then-representative $200USD device had 4-8 slow (in-order, low-cache) cores, ~2GiB of RAM, and relatively slow MLC NAND flash storage. 3] As we'll see below, CPUs are not improving fast enough to cope with frontend engineers' rosy resource assumptions. The Moto G4 , for example. Today, either method returns a similar answer.
Performance isn’t just a technical concern: it affects everything from accessibility to usability to search engine optimization, and when baking it into the workflow, design decisions have to be informed by their performance implications. Geekbench CPU performance benchmarks for the highest selling smartphones globally in 2019.
Performance isn’t just a technical concern: it affects everything from accessibility to usability to search engine optimization, and when baking it into the workflow, design decisions have to be informed by their performance implications. Geekbench CPU performance benchmarks for the highest selling smartphones globally in 2019.
This is a guest post by Kalpesh Patel , an Engineer, who for Egnyte from home. Edge caching. In general, Egnyte connect architecture shards and caches data at different levels based on: Amount of data. Nginx for disk based caching. We use different types of caching techniques depending on the problem statements.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content