This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article is to simply report the YCSB bench test results in detail for five NoSQL databases namely Redis, MongoDB, Couchbase, Yugabyte and BangDB and compare the result side by side. I have used latest versions for each NoSQL DB and have followed the recommendations to run all the databases in optimized conditions. Load and 2.
In fact, it is the number one key value store and eighth most popular database in the world. Redis is a great caching solution for highly demanding applications, and there are […]. Redis is an advanced key-value store. It has high throughput and runs from memory, but also has the ability to persist data on disk.
Python is a popular programming language, especially for beginners, and consequently we see it occurring in places where it just shouldn’t be used, such as databasebenchmarking. We use stored procedures because, as the introductory post shows, using single SQL statements turns our databasebenchmark into a network test).
PostgreSQL is a popular open source relational database management system many organizations use to store and manage their data. However, as the size of your database grows, it can become challenging to manage and optimize its performance. This can significantly improve query response times and reduce the load on your database servers.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. A basic high availability database system provides failover (preferably automatic) from a primary database node to redundant nodes within a cluster. HA is sometimes confused with “fault tolerance.”
To illustrate this, I ran the Sysbench-TPCC synthetic benchmark against two different GCP instances running a freshly installed Percona Server for MySQL version 8.0.31 That’s a heritage of the LAMP model when the same server would host both the database and the web server. MySQL (B) 2517529 2610323 389048 5516900 194140 11523.48
Since the DB is small (50% the size of the Linux RAM) – the database is mostly cached on the read side – so we only see writes going to the DB files. Despite the database flushes ocurring in bursts with a decent amount of concurrency the Nutanix CVM give an average of 1.5ms write response.
Towards multiverse databases Marzoev et al., The central idea behind multiverse databases is to push the data access and privacy rules into the database itself. With multiverse databases, each user sees a consistent “parallel universe” database containing only the data that user is allowed to see.
Redis® is an in-memory database that provides blazingly fast performance. This makes it a compelling alternative to disk-based databases when performance is a concern. Redis returns a big list of database metrics when you run the info command on the Redis shell. This blog post lists the important database metrics to monitor.
It has default settings for all of the database parameters. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. It is important to pay attention to performance when writing database queries. PostgreSQL’s Tuneable Parameters. shared_buffer.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
On MySQL and Percona Server for MySQL , there is a schema called information_schema (I_S) which provides information about database tables, views, indexes, and more. Disclaimer : This blog post is meant to show a less-known problem but is not meant to be a serious benchmark. Results for Percona Server for MySQL 8.0
As a MySQL database administrator, keeping a close eye on the performance of your MySQL server is crucial to ensure optimal database operations. This includes metrics such as query execution time, the number of queries executed per second, and the utilization of query cache and adaptive hash index.
These updates are designed to keep databases running at peak performance and simplify database operations. But as companies grow and see more demand for their databases, we need to ensure that PMM also remains scalable so you don’t need to worry about its performance while tending to the rest of your environment.
Characterizing, modeling, and benchmarking RocksDB key-value workloads at Facebook , Cao et al., Or in the case of key-value stores, what you benchmark. So if you want to design a system that will offer good real-world performance, it’s really useful to have benchmarks that accurately represent real-world workloads.
Hardware Memory The amount of RAM to be provisioned for database servers can vary greatly depending on the size of the database and the specific requirements of the company. By caching hot datasets, indexes, and ongoing changes, InnoDB can provide faster response times and utilize disk IO in a much more optimal way.
In this video I migrate a Postgres DB running PGbench benchmark. The variation in the transaction rate is due to the benchmark itself, the transaction rate is not expected to be uniform. Many different queries are executing in parallel, some hitting RAM cache, some hitting storage.
In this example we run pgbench with a scale factor of 1000 which equates to a database size of around 15GB. As expected the write pattern to the log disk (sda) is quite constant, while the write pattern to the database files (sdb) is bursty. pgbench with DB size 50% of Linux buffer cache.
Percona XtraBackup performs crash recovery on the files to make a consistent, usable database again. The redo apply phase wouldn’t make the database consistent with respect to a transaction. Initializing a DD engine and the cache adds complexity and other server dependencies. ibd2sdi data/test/t1.ibd ibd > t1.sdi
HammerDB is a software application for databasebenchmarking. It enables the user to measure database performance and make comparative judgements about database hardware and software. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking.
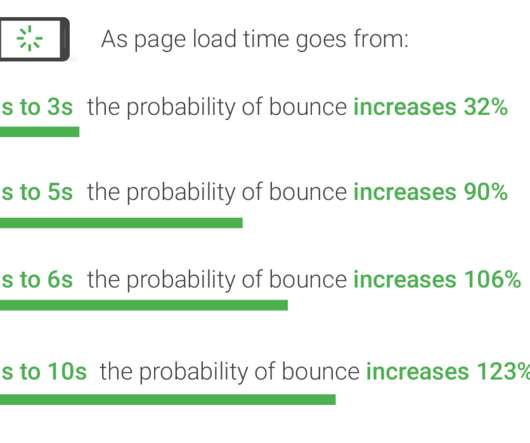
Take these statistics from Google’s industry benchmarks for mobile page speed guide: We’ve said it before but it’s worth reiterating that as web page load times increase, so does the likelihood of your visitors. Static sites don’t require a backend or database and are much more simple to manage. location ~*.(js|css|png|jpg|svg|jpeg|gif|ico)$
It has default settings for all of the database parameters. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. The performance of a PostgreSQL database has a significant impact on the overall effectiveness of an application.
MySQL triggers are a powerful tool for database administrators and developers, enabling them to automate tasks, enforce data consistency, and respond to events within the database seamlessly. A Trigger in MySQL is a database object that plays a pivotal role in database management.
The various types are: General purpose – Balanced CPU-to-memory ratio, small to medium databases. Memory optimized – High memory-to-CPU ratio, relational database servers, medium to large caches, and in-memory analytics. Benchmark Test. For a real production test, this should be large enough to help avoid hitting cache.
It is typically reduced via server-side optimizations, such as enabling caching and database indexes. However, we really want to strive to be under the benchmarks that Google sets as a best practice. Even better if you’re under Google’s best practice benchmark. seconds on desktop and 2.59 seconds on mobile.
MySQL performance tuning offers several significant advantages for effective database management and optimization. Enhanced Database Efficiency By adjusting configuration settings, you can markedly enhance the overall efficiency of your MySQL database. Experiencing database performance issues?
Among the different components of modern software solutions, the database is one of the most critical. There are many times we get asked why some cloud instance performed poorly for their database application and almost always turned out to be some configuration error. TB)) for storage of database tablespaces and logging.
Looking at the industry benchmarks for US retailers , four well-known sites have backend times that are approaching – or well beyond – that threshold. Pagespeed Benchmarks - US Retail - LCP When you examine a waterfall, it's pretty obvious that TTFB is the long pole in the tent, pushing out render times for the page.
use the TPC-H benchmark to assess Redshift, Redshift Spectrum, Athena, Presto, Hive, and Vertica to find out what works best and the trade-offs involved. in the TPC-H Benchmark Standard for details of the queries). Query performance is measured from both warm and cold caches. System initialisation time.
This overhead can be reduced by A) pcid, fully available in Linux 4.14, and B) Huge pages. - **Cache access pattern**: the overheads are exacerbated by certain access patterns that switch from caching well to caching a little less well. At 50k syscalls/sec per CPU the overhead may be 2%, and climbs as the syscall rate increases.
When deciding what to pick, there are many things to consider, like where the proxy needs to be, if it “just” needs to redirect the connections, or if more features need to be in, like caching and filtering, or if it needs to be integrated with some MySQL embedded automation. Given that, there never was a single straight answer.
You will still have to maintain your operating system, SQL Server and databases just like you would in an on-premises scenario. In exchange for this, your databases and applications will work just the same as they would in an on-premises installation, which makes this an easy way to start using Azure. Esv3-series.
If you are new to running Oracle, SQL Server, MySQL and PostgreSQL TPC-C workloads with HammerDB and have needed to investigate I/O performance the chances are that you have experienced waits on writing to the Redo, Transaction Log or WAL depending on the database you are testing. Oracle Log File Sync.
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. All modern browsers are fast, Chromium and Safari/WebKit included. Content Indexing.
Creating a HCI benchmark to simulate multi-tennent workloads. It is very common to have large resource-hungry databases separated across nodes using anti-affinity rules. The DB Colocation test utilizes two properties of X-Ray not found in other benchmarking tools. Time based benchmark actions. 4 “Data” Disks.
The L3 cache size is 64MB. Both of these Intel processors are special bespoke models that are not in the Intel ARK database. I wrote about using CPU-Z to benchmark the Intel Xeon E5-2673 v3 processor in an Azure VM in this article. Figure 1: CPU-Z Benchmark Results for LS16v2. The L3 cache size is 64MB.
This overhead can be reduced by A) pcid, fully available in Linux 4.14, and B) Huge pages. - **Cache access pattern**: the overheads are exacerbated by certain access patterns that switch from caching well to caching a little less well. At 50k syscalls/sec per CPU the overhead may be 2%, and climbs as the syscall rate increases.
Microsoft SQL Server I/O Basics Author: Bob Dorr, Microsoft SQL Server Escalation Published: December, 2004 SUMMARY: Learn the I/O requirements for Microsoft SQL Server database file operations. This cache is often supported by a battery-powered backup facility.
Last time around we looked at the DeathStarBench suite of microservices-based benchmark applications and learned that microservices systems can be especially latency sensitive, and that hotspots can propagate through a microservices architecture in interesting ways. ASPLOS’19. Distributed tracing and instrumentation.
This is a question recently asked and explored by a team of Google researchers led by Jeff Dean with a major focus on database indexes. They demonstrated that neural nets based learned index outperforms cache-optimized B-Tree index by up to 70% in speed while saving an order-of-magnitude in memory.
For example: A smaller sized, SQL Azure database , using 2 CPUs , could be assigned to CPU 2 and 3 on the host machine. MANUAL Applies To: SQL Azure Database & SQL Server Box Manual affinity is also termed hard affinity.
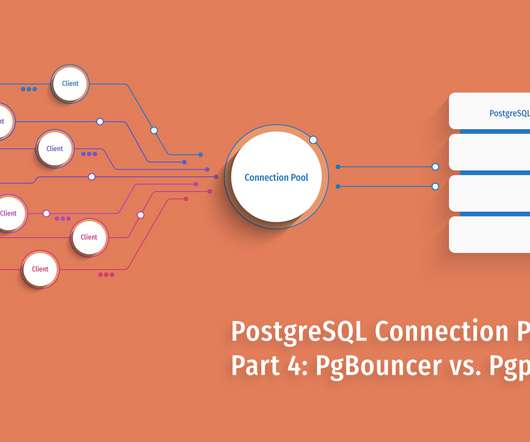
PgBouncer defines one pool per user+database combination. A client benefits from a pooled connection only if it connects to a child which has previously served a connection for this database+user combination. PgBouncer allows limiting connections per-pool, per-database, per-user or per-client. Throughput Benchmark.
On your first try, you can use it as a benchmark for optimizations later. Active Memory Caching. When you want to get data that you already had quickly, you need to do caching — caching stores data that a user recently retrieved. Caching partially stores your data and is not used as permanent storage.
KB sectors run on smaller sectors 14 System and sample databases 15 Determining the formatted sector size of database 15 What sector sizes does SQL Server support? KB boundary 12 Larger transaction logs 13 Restore and attach 14 Format for 4 ?KB
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content