This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A natural solution is to make flows configurable using configuration files, so variants can be defined without changing the code. Unlike parameters, configs can be used more widely in your flow code, particularly, they can be used in step or flow level decorators as well as to set defaults for parameters.
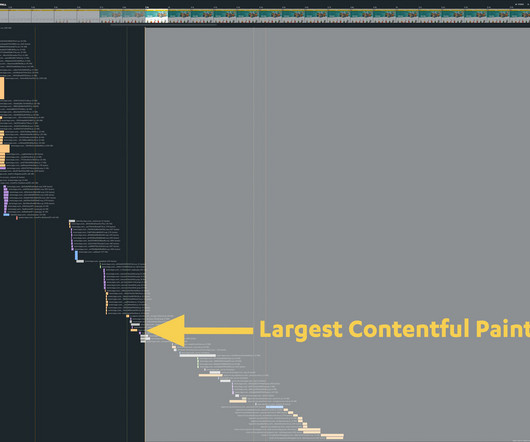
Improving each of these should hopefully chip away at the timings of more granular events that precede the LCP milestone, but whenever we’re making these kinds of indirect optimisation, we need to think much more carefully about how we measure and benchmark ourselves as we work. It’s vital to measure what you impact, not what you influence.
Python is a popular programming language, especially for beginners, and consequently we see it occurring in places where it just shouldn’t be used, such as database benchmarking. We use stored procedures because, as the introductory post shows, using single SQL statements turns our database benchmark into a network test).
Key metrics like throughput, request latency, and memory utilization are essential for assessing Redis health, with tools like the MONITOR command and Redis-benchmark for latency and throughput analysis and MEMORY USAGE/STATS commands for evaluating memory. <code> 127.0.0.1:6379> <code> 127.0.0.1:6379>
Static analysis of Java enterprise applications: frameworks and caches, the elephants in the room , Antoniadis et al., Being static , it has the advantage that analysis results can be produced solely from source code without the need to execute the program. PLDI’20. Enterprise applications have (more than?) sound-modulo-analysis.
Every unnecessary bit of JavaScript code you bundle and serve will be more code the client has to load and process. On your first try, you can use it as a benchmark for optimizations later. How will you serve blazingly fast code, then? Active Memory Caching. Using the cache as permanent storage is an anti-pattern.
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
This approach represents a source operand by specifying ‘which group’ and ‘how many writes earlier within the group’ While it slightly increases hardware complexity compared to STRAIGHT, it provides greater flexibility in machine code by efficiently handling both short-lived and long-lived values.
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Redis is better suited for complex data models, and Memcached is better suited for high-throughput, string-based caching scenarios.
Apart from library code, maybe your application doesn't have frame pointers either, in which case everything is broken. Only in extreme circumstances does the cost (in processor time and I-cache footprint) translate to a tangible benefit - circumstances which usually resort to hand-coded assembly anyway.
First, its origin was in a monoculture (the browser) wher e there was no need for compatibility with legacy code. Unfortunately, languages like Python have proven resistant to efficient implementation, partly because of their design, and partly because of limitations imposed by the need to interop with C code.
That simply includes cleaning your code and removing any unnecessary characters, like spaces, commas, or redundant code. Browser Caching: Although it may seem commonplace, caching is sometimes overlooked. Depending on how often you change content, you may want to set a long expiration time for your cache.
Google’s industry benchmarks from 2018 also provide a striking breakdown of how each second of loading affects bounce rates. The code for the site is available on GitHub for reference. I found a lot of value in the Coverage panel in DevTools because it will show just how much code is being used after everything’s downloaded.
We have spent a great deal of time at ScaleOut Software re-architecting our in-memory data grid (IMDG)’s code base to make best use of many cores and large memory. During load-balancing, the client gets the following exception when accessing the cache: ErrorCode<ERRCA0017>:SubStatus<ES0006>:There is a temporary failure.
An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems Gan et al., A typical architecture diagram for one of these services looks like this: Suitably armed with a set of benchmark microservices applications, the investigation can begin! ASPLOS’19.
HammerDB is a software application for database benchmarking. Databases are highly sophisticated software, and to design and run a fair benchmark workload is a complex undertaking. The Transaction Processing Performance Council (TPC) was founded to bring standards to database benchmarking, and the history of the TPC can be found here.
Per-Row Execution : For each affected row, the trigger’s code is executed. This code can include SQL statements, procedures, or other actions defined within the trigger. Access to OLD and NEW Values : Within the trigger code, you can access the OLD and NEW values for each column of the current row.
To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It Here I assumed a particular analytical function for the amount of memory traffic as a function of cache size to scale the bandwidth time.
As an engineer on a browser team, I'm privy to the blow-by-blow of various performance projects, benchmark fire drills, and the ways performance marketing (deeply) impacts engineering priorities. With each team, benchmarks lost are understood as bugs. All modern browsers are fast, Chromium and Safari/WebKit included. Keyboard Lock API.
This overhead can be reduced by A) pcid, fully available in Linux 4.14, and B) Huge pages. - **Cache access pattern**: the overheads are exacerbated by certain access patterns that switch from caching well to caching a little less well. This can turn a 1% overhead (syscall cycles alone) into a 7% overhead. In more detail: ## 1.
Therefore, frontend code is responsible for permission checks and privacy-preserving transformations that protect user’s data. The amount of computation required on a base update can be reduced by sharing computation and cached data between universes.
GHz 4th Generation Intel Xeon Scalable processors (code-named Sapphire Rapids) Up to 20% higher compute performance than z1d instances Up to 50 Gbps of networking speed Up to 40 Gbps of bandwidth to the Amazon Elastic Block Store (EBS) We can also verify these capabilities by running some simple benchmarks on the different subsystems.
In 2015, Google published a blog post announcing Brotli and released its source code on GitHub. The service categorized all the optimizations in three groups consisting of several “Content,” “Delivery,” and “Cache” optimizations. In my benchmarks, Brotli:11 takes several hundred milliseconds to compress a single minified jQuery file.
We track LEGO.com, along with a handful of other leading ecommerce sites, in our public-facing Retail Benchmarks dashboard , which I encourage you to check out. Are you compressing and caching the right things? Reducing the amount of code that needs to be downloaded and parsed is intended to result in faster initial rendering times.
In many cases, they can be super convenient to add or remove without having to push code changes to the site. For example, users can install browser plugins to suggest coupon codes when they are shopping, to scan web pages for malware, to play games or message friends, or do any number of other things. More after jump!
Clean coding practices. Let the web developer handle all of the necessary speed optimizations like caching and file minification while you take on the following design tips and strategies: 1. Granted, some plugins are coded to be more lightweight than others, but there will always be some sort of difference felt in your loading times.
Budgets are scaled to a benchmark network & device. For this page to be done loading it needs to be responsive to user input — the “interactive” in “Time to Interactive” Browsers process user input by generating DOM events that application code listens to. Execute the script. Global Ground-Truth.
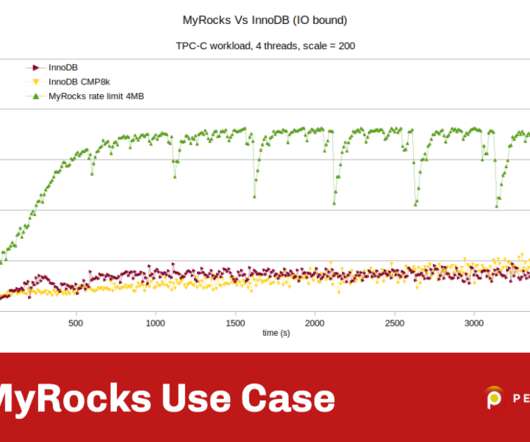
The use case is the TPC-C benchmark but executed not on a high-end server but on a lower-spec virtual machine that is I/O limited like for example, with AWS EBS volumes. If you wonder what is the difference between MyRocks and RocksDB, consider MyRocks as the piece of code, or the glue, that allows MySQL to store data in RocksDB.
For most high-end processors these values have remained in the range of 75% to 85% of the peak DRAM bandwidth of the system over the past 15-20 years — an amazing accomplishment given the increase in core count (with its associated cache coherence issues), number of DRAM channels, and ever-increasing pipelining of the DRAMs themselves.
To show that I can criticize my own work as well, here I show that sustained memory bandwidth (using an approximation to the STREAM Benchmark ) is also inadequate as a single figure of metric. (It Here I assumed a particular analytical function for the amount of memory traffic as a function of cache size to scale the bandwidth time.
” Here are additional metrics used to determine the reliability of a database, make adjustments that minimize downtime, and set benchmarks for meeting business continuity requirements. The transparency of open code enhances security as potential vulnerabilities can be identified and patched more quickly by the community.
Source: Guy Podjarny However, we do now have a full set of techniques to effectively deliver highly performative sites that not only visually scale across devices but also deliver code and assets tuned to the width of a device. All CMS's should be offering this level of image manipulation and caching. Source: SpeedCurve.
Many factors affect the speed of your WordPress website; some of them are: Your web host Server-side optimizations (PHP version, compression, caching, etc.) But before installing any plugin, you must ensure that the plugin is well-coded and properly optimized for performance. Traditionally, most WordPress hosts manage the caching.
Here’s some predictions I’m making: Jack Dongarra’s efforts to highlight the low efficiency of the HPCG benchmark as an issue will influence the next generation of supercomputer architectures to optimize for sparse matrix computations. In early January a related paper was published by Satoshi Matsuoka et. petaflops, which is 0.8%
This overhead can be reduced by A) pcid, fully available in Linux 4.14, and B) Huge pages. - **Cache access pattern**: the overheads are exacerbated by certain access patterns that switch from caching well to caching a little less well. This can turn a 1% overhead (syscall cycles alone) into a 7% overhead. In more detail: ## 1.
Synthetic monitoring actively allows users to monitor the performance of their website or application with a set of controlled variables (geography, network, device, browser, cached vs. uncached) over time. Benchmark Against Competitors.
They demonstrated that neural nets based learned index outperforms cache-optimized B-Tree index by up to 70% in speed while saving an order-of-magnitude in memory. The benchmarking was performed using 3 real-world data sets (weblogs, maps, and web-documents), and 1 synthetic dataset (lognormal).
Stable media is commonly physical disk storage, but other devices and certain caching facilities qualify as well. Many high-end disk subsystems provide high-speed cache facilities to reduce the latency of read and write operations. This cache is often supported by a battery-powered backup facility.
With many synthetic monitoring tools, you can benchmark your site against your competitors. Competitive benchmarking is a great way to see how you stack up – and how much you need to improve. Page Speed Benchmarks is an interactive set of dashboards that anyone can explore and use for their own research.
Take these statistics from Google’s industry benchmarks for mobile page speed guide: We’ve said it before but it’s worth reiterating that as web page load times increase, so does the likelihood of your visitors. Instead, we take the following code and we move it down to our footer, right before the tag. location ~*.(js|css|png|jpg|svg|jpeg|gif|ico)$
Today, the website is much faster and ranks highly in various showcases and benchmarks. And while you can usually cache the full page of an article, the same is not true of many shop pages and elements. This way, the file can be cached on the server and in the browser, and no superfluous SVGs will need to be interpreted.
PageSpeed Compare is a page speed evaluation and benchmarking tool. It also lists cached resources and identifies unused Javascript. With Treo Site Speed, you can also benchmark a website against competitors. While most of the tools covered below only rely on field metrics, others use a mix of both field and lab metrics.
Have we optimized enough with tree-shaking, scope hoisting, code-splitting, and all the fancy loading patterns with intersection observer, progressive hydration, clients hints, HTTP/3, service workers and — oh my — edge workers? It’s much easier to reach performance goals when the code base is fresh or is just being refactored.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content