This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access. A unique encryption key is applied to each tenant’s storage and automatically rotated every 365 days.
As a strategic ISV partner, Dynatrace and Azure are continuously and collaboratively innovating, focusing on a strong build-with motion dedicated to bringing innovative solutions to market to deliver better customer value. Read on to learn more about how Dynatrace and Microsoft leverage AI to transform modern cloud strategies.
Built on Azure Blob Storage, Azure Data Lake Storage Gen2 is a suite of features for big data analytics. Azure Data Lake Storage Gen1 and Azure Blob Storage's capabilities are combined in Data Lake Storage Gen2.
Modern tech stacks such as Apache Spark, Azure Data Factory, Azure Databricks, and Azure Synapse Analytics offer powerful tools for building optimized data pipelines that can efficiently ingest and process data on the cloud.
Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization. The certification focuses on accuracy and transparency in calculating greenhouse gas (GHG) emissions for AWS, Azure, GCP, and on-premises host instances.
This is the second part of our blog series announcing the massive expansion of our Azure services support. Part 1 of this blog series looks at some of the key benefits of Azure DB for PostgreSQL, Azure SQL Managed Instance, and Azure HDInsight. Fully automated observability into your Azure multi-cloud environment.
A distributed storagesystem is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.
At first, data tiering was a tactic used by storagesystems to reduce data storage costs. This involved grouping data that was not accessed as often into more affordable, if less effective, storage array choices. Even though they are quite costly, SSDs and flash can be categorized as high-performance storage classes.
High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages. The MPP system leverages a shared-nothing architecture to handle multiple operations in parallel. Typically an MPP system has one leader node and one or many compute nodes. Polymorphic Data Storage.
Dynatrace, operated from Tokyo, addresses the data residency needs of the Japanese market Dynatrace operates its AI-powered unified platform for observability, security, and business analytics as a SaaS solution in 19 worldwide regions on three hyperscalers (AWS, Azure, and GCP). Data residency in Japan is a must.
The streaming data store makes the system extensible to support other use-cases (e.g. System Components. The system will comprise of several micro-services each performing a separate task. After that, the post gets added to the feed of all the followers in the columnar data storage. Fetching User Feed.
Therefore, they need an environment that offers scalable computing, storage, and networking. Hyperconverged infrastructure (HCI) is an IT architecture that combines servers, storage, and networking functions into a unified, software-centric platform to streamline resource management. What is hyperconverged infrastructure?
These containers are software packages that include all the relevant dependencies needed to run software on any system. Managed orchestration uses solutions such as Kubernetes or Azure Service Fabric to provide greater container control and customization. Instead, enterprises manage individual containers on virtual machines (VMs).
Cloud vendors such as Amazon Web Services (AWS), Microsoft, and Google provide a wide spectrum of serverless services for compute and event-driven workloads, databases, storage, messaging, and other purposes. In addition, Davis provides automatic alerting of service-to-service communication problems using queues and other event systems.
While to-date it’s been possible to integrate Dynatrace Managed for intelligent monitoring of services running on AWS and Azure, today we’re excited to announce the release of our Dynatrace Managed marketplace listing for the Google Cloud Platform. For more details, see Dynatrace Managed hardware and systems requirements.
There are a wealth of options on how you can approach storage configuration in Percona Operator for PostgreSQL , and in this blog post, we review various storage strategies — from basics to more sophisticated use cases. For example, you can choose the public cloud storage type – gp3, io2, etc, or set file system.
As Kubernetes adoption increases and it continues to advance technologically, Kubernetes has emerged as the “operating system” of the cloud. Kubernetes is emerging as the “operating system” of the cloud. Kubernetes is emerging as the “operating system” of the cloud. Kubernetes moved to the cloud in 2022.
To make this possible, the application code should be instrumented with telemetry data for deep insights, including: Metrics to find out how the behavior of a system has changed over time. Traces help find the flow of a request through a distributed system. Logs represent event data in plain-text, structured or binary format.
Cloud providers such as Google, Amazon Web Services, and Microsoft also followed suit with frameworks such as Google Cloud Functions , AWS Lambda , and Microsoft Azure Functions. Infrastructure as a service (IaaS) handles compute, storage, and network resources. How does function as a service work? But how does FaaS fit in?
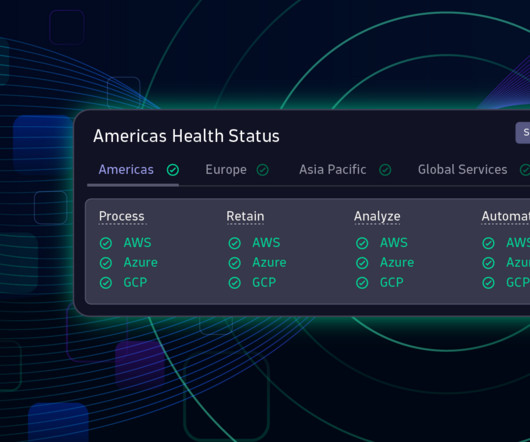
The current system status is reported on our status page in alignment with this, focusing on these four main categories: Process Combines raw data collection, processing, and initial data storage for further deep processing within the Dynatrace platform.
Driving this growth is the increasing adoption of hyperscale cloud providers (AWS, Azure, and GCP) and containerized microservices running on Kubernetes. A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device. billion in 2020 to $4.1
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. And how can you verify this performance consistently across a multicloud environment that also uses Microsoft Azure and Google Cloud Platform frameworks?
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. have altered the many assumptions that guided the design and optimization of the Snowflake system. Customer data is persisted in S3 (or the equivalent services when running on Azure or GCP), and compute is handled in EC2 instances.
When organizations focus on data privacy by design, they build security considerations into cloud systems upfront rather than as a bolt-on consideration. ” This data is excluded from storage, but teams can still gain value from data enrichment beforehand. Data is segmented and separated based on storage buckets.
Containers enable developers to package microservices or applications with the libraries, configuration files, and dependencies needed to run on any infrastructure, regardless of the target system environment. This means organizations are increasingly using Kubernetes not just for running applications, but also as an operating system.
You may be using serverless functions like AWS Lambda , Azure Functions , or Google Cloud Functions, or a container management service, such as Kubernetes. When an application runs on a single large computing element, a single operating system can monitor every aspect of the system. Dynamic applications with ephemeral services.
SQL Server has always provided the ability to capture actual queries in an easily-consumable rowset format – first with legacy SQL Server Profiler, later via Extended Events, and now with a combination of those two concepts in Azure SQL Database. Unfortunately, my excitement was short lived for a couple of reasons.
PostgreSQL is the fourth most popular database management system in the world, and heavily used in all sizes of applications from small to large. Easier access to files, features, and the operating system. In DBeaver, you can generate fake data that looks like real data allowing you to test your systems.
Buckets are similar to folders, a physical storage location. Debug-level logs, which also generate high volumes and have a shorter lifespan or value period than other logs, could similarly benefit from dedicated storage. Suppose a single Grail environment is central storage for pre-production and production systems.
According to the Kubernetes in the Wild 2023 report, “Kubernetes is emerging as the operating system of the cloud.” ” In recent years, cloud service providers such as Amazon Web Services, Microsoft Azure, IBM, and Google began offering Kubernetes as part of their managed services. Ease of use.
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storagesystems (see image below), that can lead to problems in your Kubernetes infrastructure. Configuring storage in Kubernetes is more complex than using a file system on your host. The Kubernetes experience.
In a time when modern microservices are easier to deploy, GCF, like its counterparts AWS Lambda and Microsoft Azure Functions , gives development teams an agility boost for delivering value to their customers quickly with low overhead costs. What is Google Cloud Functions? Using GCF within a video analysis workflow. Image courtesy of Google.
AzureStorage Queues is a basic yet robust queueing service available on the Azure platform. In contrast to other messaging services in Azure, it has very few features out of the box. Native publish/subscribe We have added native publish/subscribe support directly into the AzureStorage Queues transport.
One initial, easy step to moving your SQL Server on-premises workloads to the cloud is using Azure VMs to run your SQL Server workloads in an infrastructure as a service (IaaS) scenario. You will still have to maintain your operating system, SQL Server and databases just like you would in an on-premises scenario.
MySQL is a free open source relational database management system that is leveraged across a majority of WordPress sites, and allows you to query your data such as posts, pages, images, user profiles, and more. Host MySQL on AWS , or MySQL on Azure with configurable instance sizes through the top two cloud providers in the world.
As this open source database continues to pull new users from expensive commercial database management systems like Oracle, DB2 and SQL Server, organizations are adopting new approaches and evolving their own to maintain the exceptional performance of their SQL deployments. PostgreSQL popularity is skyrocketing in the enterprise space.
Azure SQL Database Managed Instance became generally available in late 2018. Organizations are taking advantage of having managed backups, lots of built-in security features, an uptime SLA of 99.99%, and an always up-to-date environment where they are no longer responsible for patching SQL Server or the operating system. GB per vCore.
Metrics to find out how the behavior of a system has changed over time . Traces help find the flow of a request through a distributed system . To provide actionable answers monitoring systems store, baseline, and analyze telemetry data. Logs represent event data in plain-text, structured or binary format .
But, as resources move off premises, IT teams can lose visibility into system performance and security issues. Additionally, organizations’ efforts to remediate a vulnerability or attack in a production environment takes a toll on security teams as they scramble to find all affected applications, systems, and data.
If you're using AzureStorage Persistence and haven't upgraded to NServiceBus 6 yet, get ready for a tremendous performance boost for your application when you do especially if you make use of sagas. Azure Table Storage, where saga data is stored, is limited to indexing on two columns: the Partition Key and the Row Key.
The Microsoft Azure IoT ecosystem offers a rich set of capabilities for processing IoT telemetry, from its arrival in the cloud through its storage in databases and data lakes. Acting as a switchboard for incoming and outgoing messages, Azure IoT Hub forms the core of these capabilities.
PostgreSQL & Elastic for data storage. Robert’s AWS & EKS admin team are monitoring most services with that capability but found it beneficial for them to have Dynatrace monitor Elastic File Storage (EFS). Dynatrace’s Response Time Hotspot Analysis automates the hotspot detection in highly distributed systems.
Thus, whenever a master MySQL goes down (whether due to a MySQL crash, OS crash, system reboot, etc.), This ensures that the system continues to be available to the applications. At ScaleGrid, we offer highly available hosting for MySQL on AWS and MySQL on Azure that is implemented based on the concepts explained in this blog series.
Back on December 5, 2017, Microsoft announced that they were using AMD EPYC 7551 processors in their storage-optimized Lv2-Series virtual machines. These VMs are not available in all regions, so you will want to check the availability in the Azure region that you are interested in using. Azure Lsv2 Details. Memory (GiB).
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content