This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access. A unique encryption key is applied to each tenant’s storage and automatically rotated every 365 days.
As a strategic ISV partner, Dynatrace and Azure are continuously and collaboratively innovating, focusing on a strong build-with motion dedicated to bringing innovative solutions to market to deliver better customer value. Read on to learn more about how Dynatrace and Microsoft leverage AI to transform modern cloud strategies.
Built on Azure Blob Storage, Azure Data Lake Storage Gen2 is a suite of features for big data analytics. Azure Data Lake Storage Gen1 and Azure Blob Storage's capabilities are combined in Data Lake Storage Gen2.
Introduction With big data streaming platform and event ingestion service Azure Event Hubs , millions of events can be received and processed in a single second. Any real-time analytics provider or batching/storage adaptor can transform and store data supplied to an event hub.
In this article, we are going to compare three of the most popular cloud providers, AWS vs. Azure vs. DigitalOcean for their database hosting costs for MongoDB® database to help you decide which cloud is best for your business. We compare AWS vs. Azure vs. DigitalOcean using the below instance types: AWS. EC2 instances. VM instances.
In September, we announced the availability of the Dynatrace Software Intelligence Platform on Microsoft Azure as a SaaS solution and natively in the Azure portal. Today, we are excited to provide an update that Dynatrace SaaS on Azure is now generally available (GA) to the public through Dynatrace sales channels.
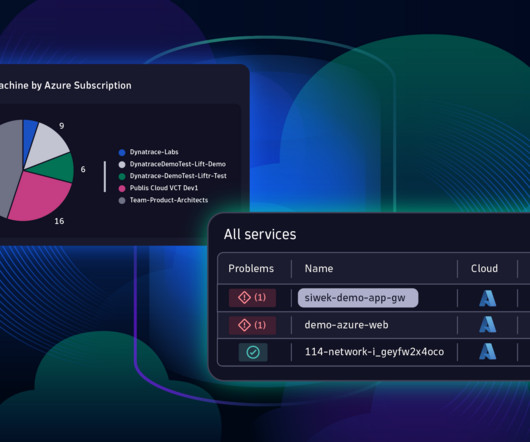
Azure Native Dynatrace Service allows easy access to new Dynatrace platform innovations Dynatrace has long offered deep integration into Azure and Azure Marketplace with its Azure Native Dynatrace Service, developed in collaboration with Microsoft. The following figure shows the benefits of Azure Native Dynatrace Service.
Cloud platforms (AWS, Azure, GCP, etc.) Integrations: Can work across multi-cloud and hybrid-cloud environments, such as AWS, Azure, and Google Cloud Platform, and provide unified visibility and management. If you’re using native Kubernetes, or K8s in AWS EKS, Azure AKS, Google GKE, or on-prem (e.g.
So many default to Amazon RDS, when MySQL performs exceptionally well on Azure Cloud. While Microsoft Azure does offer a managed solution, Azure Database, the solution has some major limitations you should know about before migrating your MySQL deployments. The Best Way to Host MySQL on Azure Cloud Click To Tweet.
Modern tech stacks such as Apache Spark, Azure Data Factory, Azure Databricks, and Azure Synapse Analytics offer powerful tools for building optimized data pipelines that can efficiently ingest and process data on the cloud.
When customers utilize the services of a specific cloud provider, such as Microsoft Azure, users within the organization eventually become experts in working with, administering, and managing the cloud resources of that provider. To establish the necessary monitoring, the observability team typically must be granted new setup permissions.
This article explores the concepts of Medallion Architecture and demonstrates how to implement batch and stream processing pipelines using Azure Databricks and Delta Lake. In Azure Databricks, this architecture can be implemented using Delta Lake to provide reliable data storage and processing capabilities.
Microsoft Azure SQL is a robust, fully managed database platform designed for high-performance querying, relational data storage, and analytics. Azure SQL is a great choice to consider for storing and querying this data under certain conditions:
This is the second part of our blog series announcing the massive expansion of our Azure services support. Part 1 of this blog series looks at some of the key benefits of Azure DB for PostgreSQL, Azure SQL Managed Instance, and Azure HDInsight. Fully automated observability into your Azure multi-cloud environment.
Hopefully, this blog will explain ‘why,’ and how Microsoft’s Azure Monitor is complementary to that of Dynatrace. Do I need more than Azure Monitor? Azure Monitor features. A typical Azure Monitor deployment, and the views associated with each business goal. Available as an agent installer). How does Dynatrace fit in?
The certification focuses on accuracy and transparency in calculating greenhouse gas (GHG) emissions for AWS, Azure, GCP, and on-premises host instances. Storage calculations assume that one terabyte consumes 1.2 Cloud storage is replicated twice, which doubles the energy consumption per terabyte.
Azure Entra Id , formerly Azure Active Directory is a comprehensive Identity and Access Management offering from Microsoft. Initially, Azure resources were accessed using connecting strings--keys tied to specific resources. For instance, for a storage account named "Foo", its connection string might be "Bar".
At first, data tiering was a tactic used by storage systems to reduce data storage costs. This involved grouping data that was not accessed as often into more affordable, if less effective, storage array choices. Even though they are quite costly, SSDs and flash can be categorized as high-performance storage classes.
This video talks about an end-to-end flow, wherein an email content having a specific subject line will be read, the email body would be analyzed using Azure Cognitive Services (Sentiment analysis), analysis results would be saved in Azure Table Storage and finally, the chart would be drawn in Excel.
As adoption rates for Azure continue to skyrocket, Dynatrace is developing a deeper integration with the Azure platform to provide even more value to organizations that run their businesses on Microsoft Azure or have Microsoft as a part of their multi-cloud strategy. Capture of complementary service metrics from Azure Monitor.
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. Understanding distributed storage is imperative as data volumes and the need for robust storage solutions rise.
Cosmos DB is a multimodal database in Azure that supports schema-less storage. For key object storage, RU tends to be less, but it still depends on the payload size. Cosmos DB can be a good candidate for a key-value store. By default, Cosmos DB containers tend to index all the fields of a document uploaded.
Dynatrace, operated from Tokyo, addresses the data residency needs of the Japanese market Dynatrace operates its AI-powered unified platform for observability, security, and business analytics as a SaaS solution in 19 worldwide regions on three hyperscalers (AWS, Azure, and GCP). Data residency in Japan is a must.
There are a wealth of options on how you can approach storage configuration in Percona Operator for PostgreSQL , and in this blog post, we review various storage strategies — from basics to more sophisticated use cases. For example, you can choose the public cloud storage type – gp3, io2, etc, or set file system.
High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages. Polymorphic Data Storage. Greenplum’s polymorphic data storage allows you to control the configuration for your table and partition storage with the freedom to execute and compress files within it at any time.
Firstly, the synchronous process which is responsible for uploading image content on file storage, persisting the media metadata in graph data-storage, returning the confirmation message to the user and triggering the process to update the user activity. Fetching User Feed. Sample Queries supported by Graph Database. Optimization.
Here is the first batch of 15 public locations for HTTP monitoring: Chicago (Azure) ?, Virginia (Azure), N. California (AWS), San Jose (Azure), Texas (Azure), Ohio (AWS), Toronto (Azure) ?, London (AWS), London (Azure), Frankfurt (AWS) ?, Hong Kong (Azure), Tokyo (Azure), Sao Paulo (AWS).
While to-date it’s been possible to integrate Dynatrace Managed for intelligent monitoring of services running on AWS and Azure, today we’re excited to announce the release of our Dynatrace Managed marketplace listing for the Google Cloud Platform. Dynatrace Managed now available on the Google Cloud Platform. What’s next?
Cloud vendors such as Amazon Web Services (AWS), Microsoft, and Google provide a wide spectrum of serverless services for compute and event-driven workloads, databases, storage, messaging, and other purposes. 3 End-to-end distributed trace including Azure Functions. Dynatrace news. New to Dynatrace? Stay tuned for updates.
Therefore, they need an environment that offers scalable computing, storage, and networking. Hyperconverged infrastructure (HCI) is an IT architecture that combines servers, storage, and networking functions into a unified, software-centric platform to streamline resource management. What is hyperconverged infrastructure?
Managed orchestration uses solutions such as Kubernetes or Azure Service Fabric to provide greater container control and customization. IaaS provides direct access to compute resources such as servers, storage, and networks. In this class of CaaS, cloud providers and hyperscalers offer minimal orchestration. Managed orchestration.
Cloud providers such as Google, Amazon Web Services, and Microsoft also followed suit with frameworks such as Google Cloud Functions , AWS Lambda , and Microsoft Azure Functions. Infrastructure as a service (IaaS) handles compute, storage, and network resources. How does function as a service work? But how does FaaS fit in?
Data warehouses offer a single storage repository for structured data and provide a source of truth for organizations. Unlike data warehouses, however, data is not transformed before landing in storage. A data lakehouse provides a cost-effective storage layer for both structured and unstructured data. Data management.
With Dynatrace, there is no need to think about schema and indexes, re-hydration, or hot/cold storage concepts. This architecture also means you’re not required to determine your log data use cases beforehand or while analyzing logs within the new Logs app.
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. Snowflake is a data warehouse designed to overcome these limitations, and the fundamental mechanism by which it achieves this is the decoupling (disaggregation) of compute and storage. joins) during query processing. Disaggregation (or not).
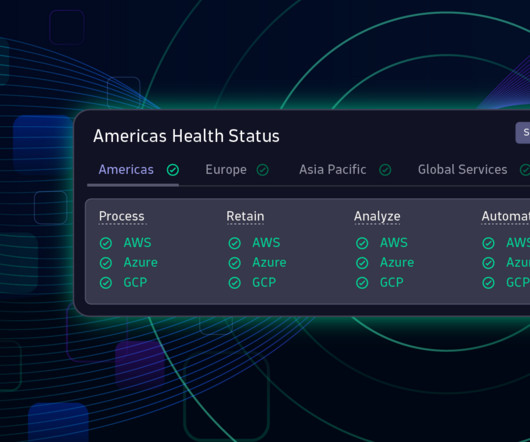
The current system status is reported on our status page in alignment with this, focusing on these four main categories: Process Combines raw data collection, processing, and initial data storage for further deep processing within the Dynatrace platform.
DigitalOcean instance costs are also over 28% less expensive than AWS, and over 26% less than Azure, providing significant savings for companies who are struggling in this global climate.
The cohesive, albeit heterogeneous on-premises IT environments of the past have given way to a disaggregated, interdependent mélange of compute, network, and storage components, both on-premises and in the private and public clouds. As a result, the number of servers and the quantity of traffic have been exploding exponentially.
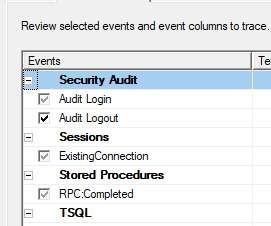
SQL Server has always provided the ability to capture actual queries in an easily-consumable rowset format – first with legacy SQL Server Profiler, later via Extended Events, and now with a combination of those two concepts in Azure SQL Database. Unfortunately, my excitement was short lived for a couple of reasons.
Configuration API for AWS and Azure supporting services. You can now get a list of all AWS and Azure supporting services on your cluster, by current version, using the AWS credentials API and Azure credentials API respectively. Improved error handling for unexpected storage issues. (APM-360014). see Settings API.
.” Once data reaches an organization’s secure tenant in the software as a service (SaaS) cluster, teams can “also can exclude certain types of data with ease of configuration and strong defaults at storage in Grail [the Dynatrace data lakehouse that houses data],” added Ferguson. Why perform exclusion at two points?
Buckets are similar to folders, a physical storage location. Debug-level logs, which also generate high volumes and have a shorter lifespan or value period than other logs, could similarly benefit from dedicated storage. Suppose a single Grail environment is central storage for pre-production and production systems.
Similarly, integrations for Azure and VMware are available to help you monitor your infrastructure both in the cloud and on-premises. Based on this information, alerting rules can be defined to notify you of any sudden increases in usage.
Microsoft has recently unveiled several new features for Azure Cosmos DB to enhance cost efficiency, boost performance, and increase elasticity. These features are burst capacity, hierarchical partition keys, serverless container storage of 1 TB, and priority-based execution. By Steef-Jan Wiggers
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content