This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction With big data streaming platform and event ingestion service AzureEvent Hubs , millions of events can be received and processed in a single second. Any real-time analytics provider or batching/storage adaptor can transform and store data supplied to an event hub.
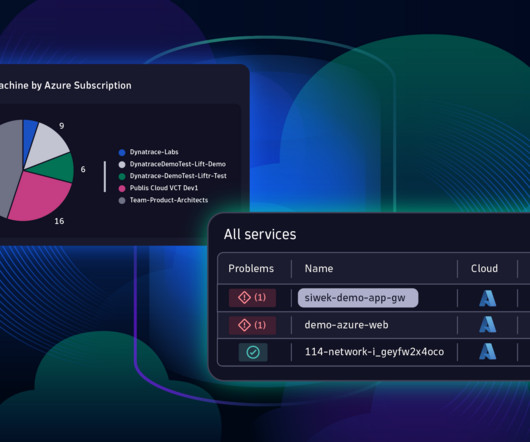
Azure Native Dynatrace Service allows easy access to new Dynatrace platform innovations Dynatrace has long offered deep integration into Azure and Azure Marketplace with its Azure Native Dynatrace Service, developed in collaboration with Microsoft. The following figure shows the benefits of Azure Native Dynatrace Service.
This is the second part of our blog series announcing the massive expansion of our Azure services support. Part 1 of this blog series looks at some of the key benefits of Azure DB for PostgreSQL, Azure SQL Managed Instance, and Azure HDInsight. Fully automated observability into your Azure multi-cloud environment.
So many default to Amazon RDS, when MySQL performs exceptionally well on Azure Cloud. While Microsoft Azure does offer a managed solution, Azure Database, the solution has some major limitations you should know about before migrating your MySQL deployments. The Best Way to Host MySQL on Azure Cloud Click To Tweet.
Cloud vendors such as Amazon Web Services (AWS), Microsoft, and Google provide a wide spectrum of serverless services for compute and event-driven workloads, databases, storage, messaging, and other purposes. 3 End-to-end distributed trace including Azure Functions. Dynatrace news. New to Dynatrace? Stay tuned for updates.
Firstly, the synchronous process which is responsible for uploading image content on file storage, persisting the media metadata in graph data-storage, returning the confirmation message to the user and triggering the process to update the user activity. Fetching User Feed. Sample Queries supported by Graph Database. Optimization.
High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages. Polymorphic Data Storage. Greenplum’s polymorphic data storage allows you to control the configuration for your table and partition storage with the freedom to execute and compress files within it at any time.
While to-date it’s been possible to integrate Dynatrace Managed for intelligent monitoring of services running on AWS and Azure, today we’re excited to announce the release of our Dynatrace Managed marketplace listing for the Google Cloud Platform. Dynatrace Managed now available on the Google Cloud Platform. What’s next?
Cloud providers such as Google, Amazon Web Services, and Microsoft also followed suit with frameworks such as Google Cloud Functions , AWS Lambda , and Microsoft Azure Functions. This code is then executed on remote servers in response to an event, such as users interacting with functional web elements. But how does FaaS fit in?
Buckets are similar to folders, a physical storage location. Debug-level logs, which also generate high volumes and have a shorter lifespan or value period than other logs, could similarly benefit from dedicated storage. Suppose a single Grail environment is central storage for pre-production and production systems.
Here is the first batch of 15 public locations for HTTP monitoring: Chicago (Azure) ?, Virginia (Azure), N. California (AWS), San Jose (Azure), Texas (Azure), Ohio (AWS), Toronto (Azure) ?, London (AWS), London (Azure), Frankfurt (AWS) ?, Hong Kong (Azure), Tokyo (Azure), Sao Paulo (AWS).
Proper linking of pod events to the pod (previously, short-lived pods would sometimes not be recognized, so the Kubernetes event would be linked to the related namespace entity instead). Configuration API for AWS and Azure supporting services. Improved error handling for unexpected storage issues. (APM-360014).
With siloed data sources, heterogeneous data types—including metrics, traces, logs, user behavior, business events, vulnerabilities, threats, lifecycle events, and more—and increasing tool sprawl, it’s next to impossible to offer users real-time access to data in a unified, contextualized view. Understanding the context.
Logs represent event data in plain-text, structured or binary format. Similarly, integrations for Azure and VMware are available to help you monitor your infrastructure both in the cloud and on-premises. Traces help find the flow of a request through a distributed system. Dynatrace Kubernetes documentation . Kubernetes integration.
Whether it’s cloud applications, infrastructure, or even security events, this capability accelerates time to value by surfacing logs that provide the crucial context of what occurred just before an error line was logged. With Dynatrace, there is no need to think about schema and indexes, re-hydration, or hot/cold storage concepts.
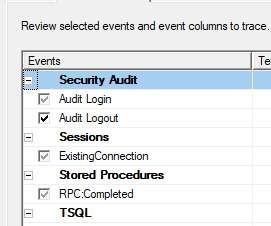
SQL Server has always provided the ability to capture actual queries in an easily-consumable rowset format – first with legacy SQL Server Profiler, later via Extended Events, and now with a combination of those two concepts in Azure SQL Database. Legacy Profiler "Standard" trace events.
Driving this growth is the increasing adoption of hyperscale cloud providers (AWS, Azure, and GCP) and containerized microservices running on Kubernetes. A log is a detailed, timestamped record of an event generated by an operating system, computing environment, application, server, or network device. billion in 2020 to $4.1
And how can you verify this performance consistently across a multicloud environment that also uses Microsoft Azure and Google Cloud Platform frameworks? Storing frequently accessed data in faster storage, usually in-memory caching, improves data retrieval speed and overall system performance. Beyond
DevOps teams operating, maintaining, and troubleshooting Azure, AWS, GCP, or other cloud environments are provided with an app focused on their daily routines and tasks. There is no need to think about schema and indexes, re-hydration, or hot/cold storage.
In a time when modern microservices are easier to deploy, GCF, like its counterparts AWS Lambda and Microsoft Azure Functions , gives development teams an agility boost for delivering value to their customers quickly with low overhead costs. What is Google Cloud Functions? Using GCF within a video analysis workflow. Image courtesy of Google.
Most Kubernetes clusters in the cloud (73%) are built on top of managed distributions from the hyperscalers like AWS Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS), or Google Kubernetes Engine (GKE). Messaging : RabbitMQ and Kafka are the two main messaging and event streaming systems used.
While you may assume a great majority of the cloud database deployments are run on AWS, Azure, or Google Cloud Platform, small to medium-sized businesses in particular are gravitating towards the developer-friendly cloud provider, DigitalOcean , for their hosting for MongoDB® needs. DigitalOcean Advantages for MongoDB. DigitalOcean Droplets.
You may be using serverless functions like AWS Lambda , Azure Functions , or Google Cloud Functions, or a container management service, such as Kubernetes. As the entire application shares the same computing environment, it collects all logs in the same location, and developers can gain insight from a single storage area.
Problems include provisioning and deployment; load balancing; securing interactions between containers; configuration and allocation of resources such as networking and storage; and deprovisioning containers that are no longer needed. How does container orchestration work?
Nevertheless, there are related components and processes, for example, virtualization infrastructure and storage systems (see image below), that can lead to problems in your Kubernetes infrastructure. Configuring storage in Kubernetes is more complex than using a file system on your host. Logs can also be used to represent event data.
AzureStorage Queues is a basic yet robust queueing service available on the Azure platform. In contrast to other messaging services in Azure, it has very few features out of the box. Native publish/subscribe We have added native publish/subscribe support directly into the AzureStorage Queues transport.
Host MySQL on AWS , or MySQL on Azure with configurable instance sizes through the top two cloud providers in the world. Backups are copies of your data that are archived so you can access and restore them in case of a data loss event. We support two different MySQL DBaaS plans on both AWS and Azure. Automated Backups.
Causal AI is an artificial intelligence technique used to determine the precise underlying causes and effects of events. Using Implementing AWS well-architected pillars with automated workflows – blog Ensure the performance of AWS well-architected pillars, and similar frameworks from Azure and GCP, with Dynatrace Site Reliability Guardian.
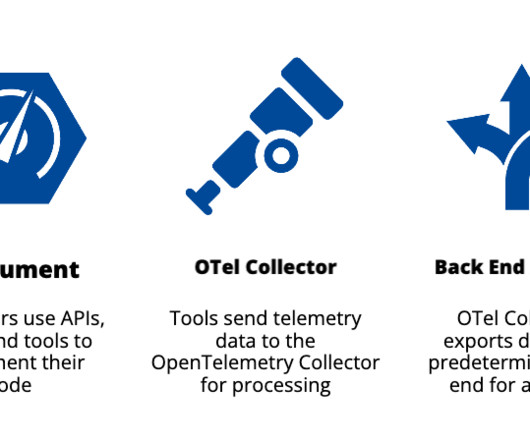
Different monitoring point solutions, such as Jaeger, Zipkin, Logstash, Fluentd, and StatsD, each have their own way of observing and recording such an event. Challenges of adopting OpenTelemetry The first challenge is that OpenTelemetry only gathers and processes data—it has no back end, no storage, and no analytics.
Logs represent event data in plain-text, structured or binary format . Similar ly, integrations for Azure and VMware are available to help you monitor your infrastructure both in the cloud and on-premises. . Metrics to find out how the behavior of a system has changed over time . Dynatrace Kubernetes documentation .
The Microsoft Azure IoT ecosystem offers a rich set of capabilities for processing IoT telemetry, from its arrival in the cloud through its storage in databases and data lakes. Acting as a switchboard for incoming and outgoing messages, Azure IoT Hub forms the core of these capabilities.
PostgreSQL & Elastic for data storage. In the event that there’s a problem, Dynatrace will automatically highlight the hotspot and root cause in the different Dynatrace views. Their technology stack looks like this: Spring Boot-based Microservices. NGINX as an API Gateway. REDIS for caching. AWS EKS for Integration and Production.
using them to respond to storageevents on s3 or database events or auth events is super easy and powerful. Eitally : there are a few critical differences between GCP and AWS or Azure. Xtracerx : for me the biggest value to serverless functions is how nicely they tie in to the ecosystem of a cloud provider.
Thus, we see that the MySQL HA framework handles split-brain scenarios effectively, ensuring both data consistency and availability in the event the network connectivity breaks between master and slave nodes.
AWS is far and away the cloud leader, followed by Azure (at more than half of share) and Google Cloud. But most Azure and GCP users also use AWS; the reverse isn’t necessarily true. However, close to half (~48%) use Microsoft Azure, and close to one-third (~32%) use Google Cloud Platform (GCP). Conclusion.
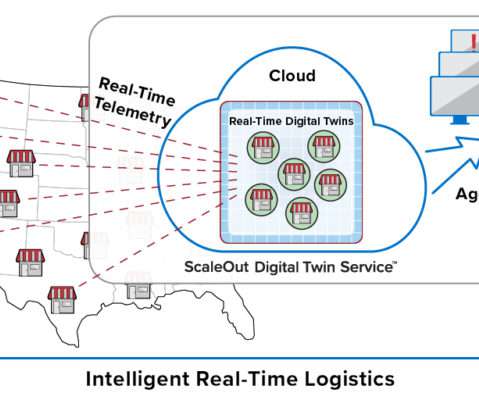
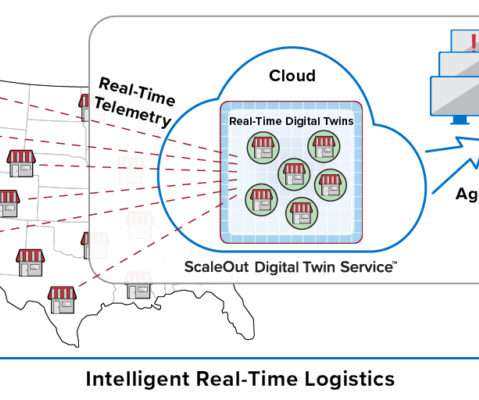
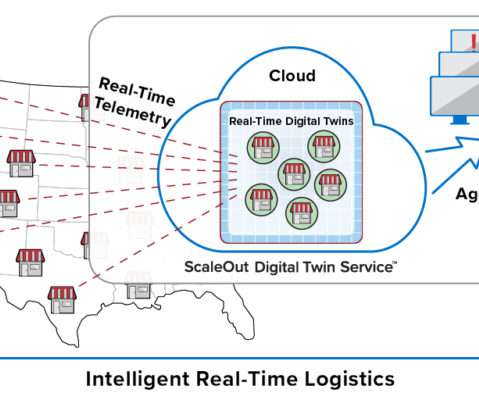
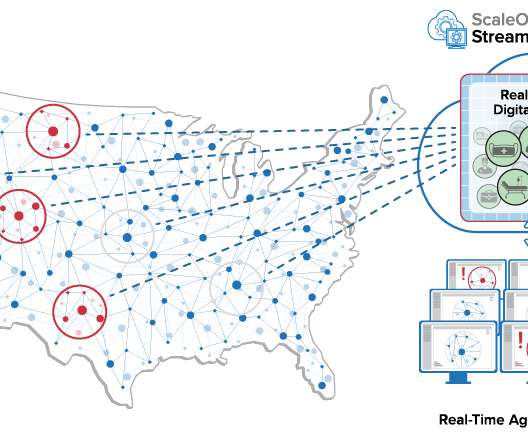
It’s not enough just to pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. In addition, the platform provides fast, in-memory data storage so that the application can easily and quickly record both telemetry and analytics results for each store.
It’s not enough just to pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. In addition, the platform provides fast, in-memory data storage so that the application can easily and quickly record both telemetry and analytics results for each store.
It’s not enough to just pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. In addition, the platform provides fast, in-memory data storage so that the application easily can keep track of both telemetry and analytics results for each store.
Incoming data is saved into data storage (historian database or log store) for query by operational managers who must attempt to find the highest priority issues that require their attention. The best they can usually do in real-time using general purpose tools is to filter and look for patterns of interest.
MongoDB is a non-relational document database that provides support for JSON-like storage. It’s very useful to check if any of the secondaries are behind the PRIMARY on data replication, as this would affect your ability to recover all your data in the event of something going wrong. Do backups of your data frequently!
In your back-end system, you might benefit from event-driven architecture, automatic message retries, and orchestration of long-running business processes. For example, if your order entry front end can benefit from rapid prototyping, you should be able to use Ruby on Rails and Active Record.
As a MongoDB user, it’s crucial to ensure that your data is safe and secure in the event of a disaster or system failure. The speed of backup also depends on allocated IOPS and type of storage since lots of read/writes would be happening during this process. Why are MongoDB database backups important? mongodump --host=mongodb1.example.net
Microsoft have a paper describing their new recovery mechanism in Azure SQL Database , the key feature being that it can recovery in constant time. Autoscaling tiered cloud storage in Anna. Microsoft have been able to guarantee consistent 3 minute recovery times for 99.999% of recovery cases in production. Research papers. (In
For example, the parameters for a ventilator could include its identifier, make and model, current location, status (in use, in storage, broken), time in use, technical issues and repairs, and contact information. Field personnel with mobile devices can send these messages over the Internet to the cloud service.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content