This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Greenplum Database is a massively parallel processing (MPP) SQL database that is built and based on PostgreSQL. Greenplum Database is an open-source , hardware-agnostic MPP database for analytics, based on PostgreSQL and developed by Pivotal who was later acquired by VMware. What is an MPP Database?
The strongest Kubernetes growth areas are security, databases, and CI/CD technologies. Most Kubernetes clusters in the cloud (73%) are built on top of managed distributions from the hyperscalers like AWS Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS), or Google Kubernetes Engine (GKE). Java, Go, and Node.js
Rural lifestyle retail giant Tractor Supply Co. Rural lifestyle retail giant Tractor Supply Co. discussed the 85-year-old retailer’s cloud migration journey and the importance of multicloud observability at Dynatrace Perform 2023. “We need to scale faster with shorter deployment times. Further, as Tractor Supply Co.
DevOps teams operating, maintaining, and troubleshooting Azure, AWS, GCP, or other cloud environments are provided with an app focused on their daily routines and tasks. For example, deleting the database is not an expected outcome when the function provided is to update a user profile.
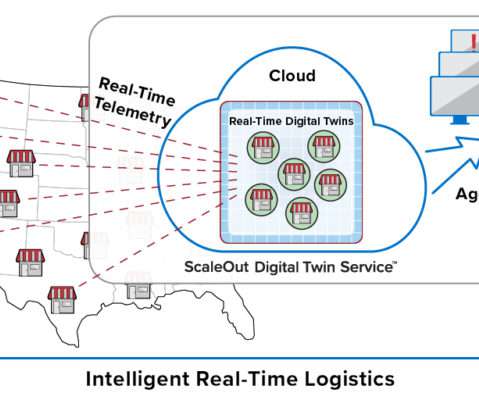
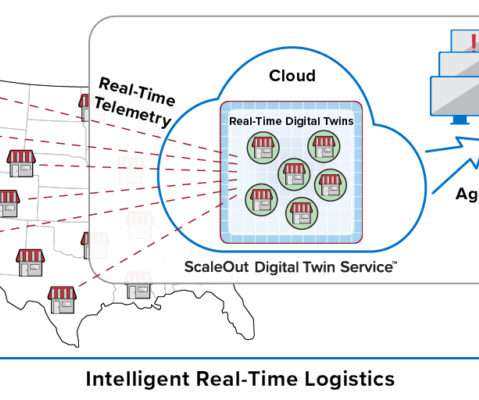
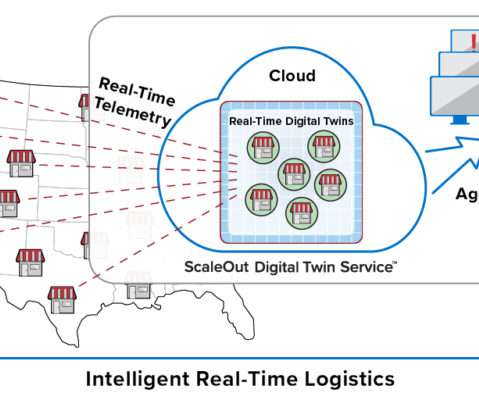
Consider a retail chain of stores or restaurants with tens of thousands of outlets. It’s not enough just to pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. Walgreens has more than 9,000, and McDonald’s has more than 14,000 in the U.S.
Consider a retail chain of stores or restaurants with tens of thousands of outlets. It’s not enough just to pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. Walgreens has more than 9,000, and McDonald’s has more than 14,000 in the U.S.
Consider a retail chain of stores or restaurants with tens of thousands of outlets. It’s not enough to just pick out interesting events from an aggregated data stream and then send them to a database for offline analysis using Spark. Walgreens has more than 9,000, and McDonald’s has more than 14,000 in the U.S.
Major cloud providers like AWS, Microsoft Azure, and Google Cloud all support serverless services. If you have a large database of user information stored on your servers, consider introducing multi-factor identification. Machine Learning AI is no longer restricted by its programmer’s inputs.
With their tightly integrated client-side caching, IMDGs typically provide much faster access to this shared data than backing stores, such as blob stores, database servers, and NoSQL stores. ScaleOut StateServer uses different techniques on EC2 and Azure to make use of available metadata support. The Need to Keep It Simple.
With their tightly integrated client-side caching, IMDGs typically provide much faster access to this shared data than backing stores, such as blob stores, database servers, and NoSQL stores. ScaleOut StateServer uses different techniques on EC2 and Azure to make use of available metadata support. The Need to Keep It Simple.
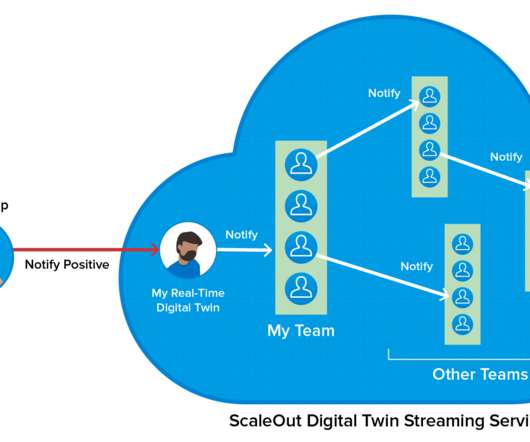
Using information from the company’s organizational database, it populates each twin with the employee’s ID, team ID, department type, and location. The demo application creates a memory-based real-time digital twin for each employee. The Benefits of an Integrated Streaming Service.
Using information from the company’s organizational database, it populates each twin with the employee’s ID, team ID, department type, and location. The demo application creates a memory-based real-time digital twin for each employee. The Benefits of an Integrated Streaming Service.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














Let's personalize your content