This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This extension provides fully app-centric Cassandra performance monitoring for Azure Managed Instance for Apache Cassandra. Azure Managed Instance for Apache Cassandra vs Azure Cosmos DB Cassandra API. Microsoft Azure offers multiple ways to manage Apache Cassandra databases.
As organizations adopt microservices architecture with cloud-native technologies such as Microsoft Azure , many quickly notice an increase in operational complexity. To guide organizations through their cloud migrations, Microsoft developed the Azure Well-Architected Framework. What is the Azure Well-Architected Framework?
Hopefully, this blog will explain ‘why,’ and how Microsoft’s Azure Monitor is complementary to that of Dynatrace. Do I need more than Azure Monitor? Azure Monitor features. A typical Azure Monitor deployment, and the views associated with each business goal. Available as an agent installer). How does Dynatrace fit in?
Findings provide insights into Kubernetes practitioners’ infrastructure preferences and how they use advanced Kubernetes platform technologies. Kubernetes infrastructure models differ between cloud and on-premises. Kubernetes infrastructure models differ between cloud and on-premises. Kubernetes moved to the cloud in 2022.
The RAG process begins by summarizing and converting user prompts into queries that are sent to a search platform that uses semantic similarities to find relevant data in vector databases, semantic caches, or other online data sources. Estimates show that NVIDIA, a semiconductor manufacturer, could release 1.5
AWS , Azure. AWS , Azure. AWS , Azure. AWS , Azure. AWS , Azure. AWS , Azure. AWS , Azure. AWS , Azure , DigitalOcean. Are you a startup that has free AWS or Azure hosting credits you’d like to use for your database hosting? Do you want to deploy in an AWS VPC or Azure VNET?
According to the Dynatrace “2022 Global CIO Report,” 79% of large organizations use multicloud infrastructure. Moreover, organizations have to balance maintaining security, retaining cloud management expertise, and managing infrastructure performance. Rural lifestyle retail giant Tractor Supply Co.
FUN FACT : In this talk , Rodrigo Schmidt, director of engineering at Instagram talks about the different challenges they have faced in scaling the data infrastructure at Instagram. We will use a cache having an LRU based eviction policy for caching user feeds of active users. System Components. Streaming Data Model.
Data lakehouses take advantage of low-cost object stores like AWS S3 or Microsoft Azure Blob Storage to store and manage data cost-effectively. A dynamic map of interactions and relationships between applications and the underlying infrastructure also helps to zoom in and out of an issue at different stages of analysis. Query language.
And how can you verify this performance consistently across a multicloud environment that also uses Microsoft Azure and Google Cloud Platform frameworks? Storing frequently accessed data in faster storage, usually in-memory caching, improves data retrieval speed and overall system performance. Beyond
One initial, easy step to moving your SQL Server on-premises workloads to the cloud is using Azure VMs to run your SQL Server workloads in an infrastructure as a service (IaaS) scenario. One important choice you will still have to make is what type and size of Azure virtual machine you want to use for your existing SQL Server workload.
Infrastructure Integration. From a developer perspective, not only static assets need to be cached on a CDN. Many headless CMSes cache content retrieved via RESTful or GraphQL APIs. While CDN caching is super useful, there are times when cache corruption or older cached items could create issues.
This paper presents Snowflake design and implementation along with a discussion on how recent changes in cloud infrastructure (emerging hardware, fine-grained billing, etc.) Customer data is persisted in S3 (or the equivalent services when running on Azure or GCP), and compute is handled in EC2 instances.
But long term we don’t want to run any of our own infrastructure (in Yammer) so we will look to move to Service Fabric or Azure Kubernetes Service. Then please recommend my well reviewed (30 reviews on Amazon and 72 on Goodreads!) book: Explain the Cloud Like I'm 10. They'll love it and you'll be their hero forever. $10
By integrating distributed storage solutions into their infrastructure, organizations can effectively manage increased data storage demands while maintaining optimal performance levels – a characteristic intrinsic to these systems’ design, enabling effortless scaling for handling greater quantities of stored content.
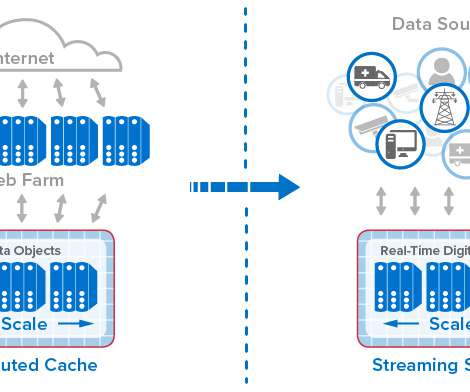
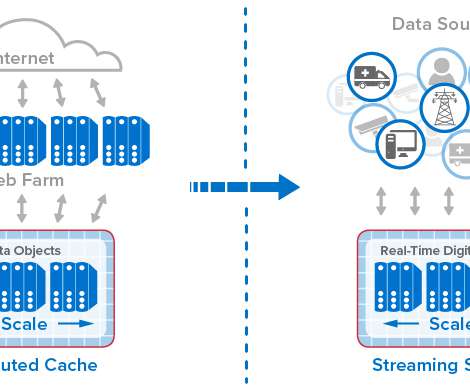
From Distributed Caches to Real-Time Digital Twins. The pace of these changes has made it challenging for server-based infrastructures to manage fast-growing populations of users and data sources while maintaining fast response times.
From Distributed Caches to Real-Time Digital Twins. The pace of these changes has made it challenging for server-based infrastructures to manage fast-growing populations of users and data sources while maintaining fast response times.
The code is declarative, which means you specify what you want the final configuration to look like, and Terraform ensures the infrastructure matches that desired state.â€So, â€Terraform is a revolution in the way we handle infrastructure. Backgroundâ€The idea of managing infrastructure through code wasn't initiated by HashiCorp.
Today, we’ll address storing and serving files for both single-server and scalable deployments while considering factors like compression, caching, and availability. Client-Side Caching. Caching is the process of storing the results of a computation or request so that they can be accessed repeatedly more quickly. In Conclusion.
In this case, we are not going to be talking about infrastructure services, such as a cloud computing platform like Microsoft Azure or a content distribution network like Akamai. The third-party in this case is someone (usually another commercial enterprise) other than you and your site visitors.
Cloud-based applications enjoy the unique elasticity that cloud infrastructures provide. With their tightly integrated client-side caching, IMDGs typically provide much faster access to this shared data than backing stores, such as blob stores, database servers, and NoSQL stores.
Cloud-based applications enjoy the unique elasticity that cloud infrastructures provide. With their tightly integrated client-side caching, IMDGs typically provide much faster access to this shared data than backing stores, such as blob stores, database servers, and NoSQL stores.
The code is declarative, which means you specify what you want the final configuration to look like, and Terraform ensures the infrastructure matches that desired state.So, What Exactly is Terraform?Terraform Terraform is a revolution in the way we handle infrastructure. This level of granularity is not found in UI-managed systems.
In addition, setting up a debuggable environment is a serious challenge as we need to understand the components involved in the scenario we’re debugging, which could span different solutions, repositories, or endpoints, each of which may require additional infrastructure to be available. Summary Ready to try it out on your own?
So it is convenient for all to use irrespective of internet speed and it works offline using cached data. This architecture runs on cloud technology, and developers can focus on the code instead of the scaling, maintenance, and infrastructure facilities. Besides that, these apps do well in areas with a slow internet connection.
Cons of logical backups As it reads all data, it can be slow and will require disk reads too for databases that are larger than the RAM available for the WT cache—the WT cache pressure increases, which slows down the performance. Hence, the node would still be available for other operations.
Device level flushing may have an impact on your I/O caching, read ahead or other behaviors of the storage system. Neal, Matt, and others from Windows Storage, Windows Azure Storage, Windows Hyper-V, … validating Windows behaviors. · This flag does NOT imply flush behaviors, only the avoidance of the system file cache.
That means multiple data indirections mean multiple cache misses. Mark LaPedus : MRAM, a next-generation memory type, is being touted as a replacement for embedded flash and cache applications. The third wing of the architecture piece is the “domain specific system-on-chip.” They are very expensive.
You should expect one-time implementation cost (depending CMS and business requirements it can cost 200,000 USD to 3M USD) and yearly hosting infrastructure cost (proportional to load and traffic but typically 30,000 USD - 300,000 USD per year). Pure CMS licensing cost can be anywhere between 50,000 - 500,000 USD a year.
Edge caching. Infrastructure Optimization. In general, Egnyte connect architecture shards and caches data at different levels based on: Amount of data. Nginx for disk based caching. Tens of petabytes of data stored in our servers and other object stores such as GCS, S3 and Azure Blobstore. Disk based caching.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content