This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When handling large amounts of complex data, or bigdata, chances are that your main machine might start getting crushed by all of the data it has to process in order to produce your analytics results. Greenplum features a cost-based query optimizer for large-scale, bigdata workloads. Query Optimization.
Introduction With bigdata streaming platform and event ingestion service Azure Event Hubs , millions of events can be received and processed in a single second. Any real-time analytics provider or batching/storage adaptor can transform and store data supplied to an event hub.
Built on Azure Blob Storage, AzureData Lake Storage Gen2 is a suite of features for bigdata analytics. AzureData Lake Storage Gen1 and Azure Blob Storage's capabilities are combined in Data Lake Storage Gen2.
Google Cloud does offer their own wide column store and bigdata database called Bigtable which is actually ranked #111, one under ScyllaDB at #110 on DB-Engines. Azure followed in third place representing 17.4% Azure followed in third place representing 17.4% AWS vs. Azure vs. GCP Click To Tweet.
As adoption rates for Microsoft Azure continue to skyrocket, Dynatrace is developing a deeper integration with the platform to provide even more value to organizations that run their businesses on Azure or use it as a part of their multi-cloud strategy. Azure Batch. Azure DB for MariaDB. Azure DB for MySQL.
A hybrid cloud, however, combines public infrastructure and services with on-premises resources or a private data center to create a flexible, interconnected IT environment. Hybrid environments provide more options for storing and analyzing ever-growing volumes of bigdata and for deploying digital services.
Most Kubernetes clusters in the cloud (73%) are built on top of managed distributions from the hyperscalers like AWS Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS), or Google Kubernetes Engine (GKE). Bigdata : To store, search, and analyze large datasets, 32% of organizations use Elasticsearch.
Agent and open technologies make it easy to ingest large volumes of observability, security, and business data. Data management. Data lakehouses take advantage of low-cost object stores like AWS S3 or Microsoft Azure Blob Storage to store and manage data cost-effectively. Data warehouses. Query language.
Part of its popularity owes to its availability as a managed service through the major cloud providers, such as Amazon Elastic Kubernetes Service , Google Kubernetes Engine , and Microsoft Azure Kubernetes Service. Likewise, Kubernetes is both an enterprise platform and managed services with Red Hat OpenShift.
Experiences with approximating queries in Microsoft’s production big-data clusters Kandula et al., Microsoft’s bigdata clusters have 10s of thousands of machines, and are used by thousands of users to run some pretty complex queries. VLDB’19. For the larger more production-like query analysed in §4.2.1,
These systems enable vast amounts of data to be spread over multiple nodes, allowing for simultaneous access and boosting processing efficiency. Amazon S3 and Microsoft Azure Blob Storage leverage distributed storage solutions. These distributed storage services also play a pivotal role in bigdata and analytics operations.
Workloads from web content, bigdata analytics, and artificial intelligence stand out as particularly well-suited for hybrid cloud infrastructure owing to their fluctuating computational needs and scalability demands.
And it can maintain contextual information about every data source (like the medical history of a device wearer or the maintenance history of a refrigeration system) and keep it immediately at hand to enhance the analysis.
Microsoft engineering is actually sending quite a few folks over the Atlantic to come talk about SQL Server 2017, SQL Server on Linux, GDPR, Performance, Security, AzureData Lake, Azure SQL Database, Azure SQL Data Warehouse, and Azure CosmosDB. SELECT * FROM Azure Cosmos DB – Andrew Liu.
Microsoft have a paper describing their new recovery mechanism in Azure SQL Database , the key feature being that it can recovery in constant time. Hyper Dimension Shuffle describes how Microsoft improved the cost of data shuffling, one of the most costly operations, in their petabyte-scale internal bigdata analytics platform, SCOPE.
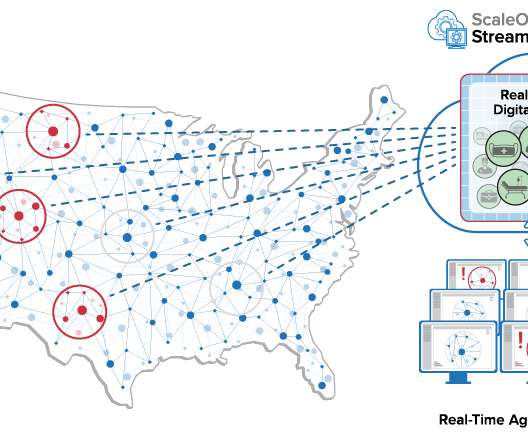
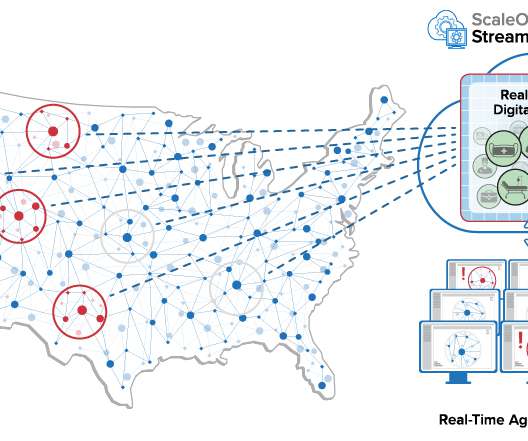
Unlike powerful bigdata platforms which focus on deep and often lengthy analysis to make future projections, what real-time digital twins offer is timeliness in obtaining quick answers to pressing questions using the most current data.
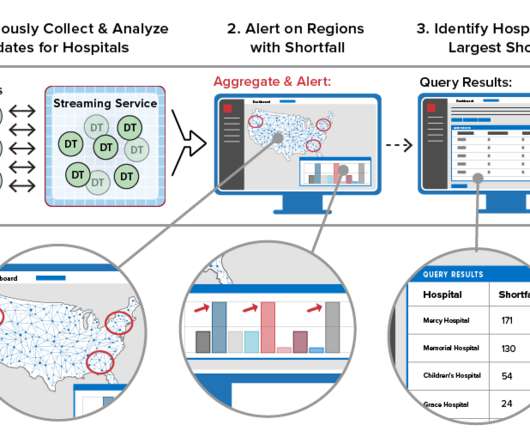
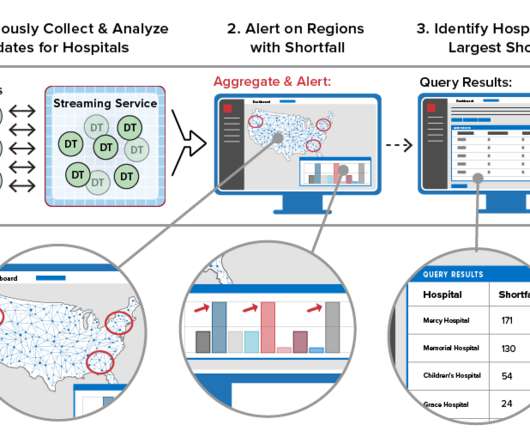
Instead, most applications just sift through the telemetry for patterns that might indicate exceptional conditions and forward the bulk of incoming messages to a data lake for offline scrubbing with a bigdata tool such as Spark. Maintain State Information for Each Data Source.
Instead, most applications just sift through the telemetry for patterns that might indicate exceptional conditions and forward the bulk of incoming messages to a data lake for offline scrubbing with a bigdata tool such as Spark. Maintain State Information for Each Data Source.
Unlike powerful bigdata platforms which focus on deep and often lengthy analysis to make future projections, what real-time digital twins offer is timeliness in obtaining quick answers to pressing questions using the most current data.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content