This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Our "serverless" order processing system built on AWS Lambda and API Gateway was humming along, handling 1,000 transactions/minute. A sudden spike in traffic caused Lambda timeouts, API Gateway threw 5xx errors, and customers started tweeting, Why cant I check out?! Then, disaster struck.
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
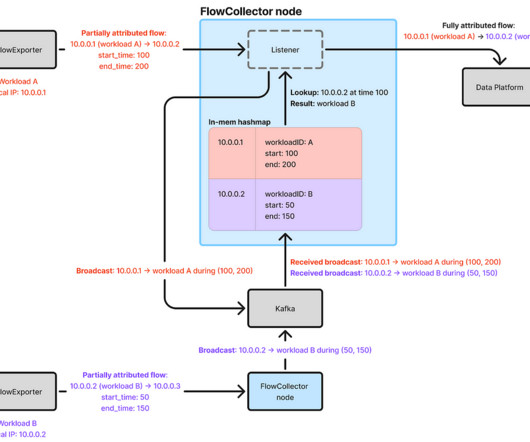
As noted in our previous blog post, our initial attribution approach relied on Sonar , an internal IP address tracking service that emits an event whenever an IP address in Netflixs AWS VPCs is assigned or unassigned to a workload. Netflixs cloud microservices operate across multiple AWS regions.
With the advent of cloud computing, managing network traffic and ensuring optimal performance have become critical aspects of system architecture. Amazon Web Services (AWS), a leading cloud service provider, offers a suite of load balancers to manage network traffic effectively for applications running on its platform.
Visibility into system activity and behavior has become increasingly critical given organizations’ widespread use of Amazon Web Services (AWS) and other serverless platforms. These challenges make AWS observability a key practice for building and monitoring cloud-native applications. What is AWS observability?
Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization. The certification focuses on accuracy and transparency in calculating greenhouse gas (GHG) emissions for AWS, Azure, GCP, and on-premises host instances.
We’re excited to announce several log management innovations, including native support for Syslog messages, seamless integration with AWS Firehose, an agentless approach using Kubernetes Platform Monitoring solution with Fluent Bit, a new out-of-the-box ingest dashboard, and OpenPipeline ingest improvements.
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
Dynatrace has added support for the newly introduced Amazon Virtual Private Cloud (VPC) Flow Logs for AWS Transit Gateway. What is AWS Transit Gateway? AWS Transit Gateway is a service offering from Amazon Web Services that connects network resources via a centralized hub. What is VPC Flow Logs.
As organizations plan, migrate, transform, and operate their workloads on AWS, it’s vital that they follow a consistent approach to evaluating both the on-premises architecture and the upcoming design for cloud-based architecture. AWS 5-pillars. Dynatrace and AWS. through our AWS integrations and monitoring support.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target.
For retail organizations, peak traffic can be a mixed blessing. While high-volume traffic often boosts sales, it can also compromise uptimes. The nirvana state of system uptime at peak loads is known as “five-nines availability.” How can IT teams deliver system availability under peak loads that will satisfy customers?
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems. ETL workflows), as well as downstream (e.g.
The control group’s traffic utilized the legacy Falcor stack, while the experiment population leveraged the new GraphQL client and was directed to the GraphQL Shim. The AB experiment results hinted that GraphQL’s correctness was not up to par with the legacy system. The Replay Tester tool samples raw traffic streams from Mantis.
The Qualys Threat Research Unit (TRU) has discovered a Remote Unauthenticated Code Execution (RCE) vulnerability in OpenSSH server (sshd) in glibc-based Linux systems. This can result in a complete system takeover, malware installation, data manipulation, and the creation of backdoors for persistent access.
In the latest enhancements of Dynatrace Log Management and Analytics , Dynatrace extends coverage for Native Syslog support: Use Dynatrace ActiveGate to automatically add context and optimize network traffic to your Syslog messages. AWS : Automate your AWS infrastructure with actions across EC2, S3, Lambda, and more.
The fact is, Reliability and Resiliency must be rooted in the architecture of a distributed system. The subject line said: “Success Story: Major Issue in single AWS Frankfurt Availability Zone!” Fact #1: AWS EC2 outage properly documented. Fact #1: AWS EC2 outage properly documented. Ready to learn more? Then read on!
Each of these models is suitable for production deployments and high traffic applications, and are available for all of our supported databases, including MySQL , PostgreSQL , Redis™ and MongoDB® database ( Greenplum® database coming soon). AWS , Azure. AWS , Azure. AWS , Azure. AWS , Azure. AWS , Azure.
Today, I am happy to announce our plans to open a new AWS Region in Italy! The AWS Europe (Milan) Region is the 25th AWS Region that we've announced globally. It's the sixth AWS Region in Europe, joining existing regions in France, Germany, Ireland, the UK, and the new Region that we recently announced in Sweden.
For example, to handle traffic spikes and pay only for what they use. Observability is essential to ensure the reliability, security and quality of any software system. Scale automatically based on the demand and traffic patterns. The elasticity of serverless services helps organizations scale as needed.
AWS EKS for Integration and Production. When focusing on the LanguageController service we learn that it’s currently deployed in three pods across three EKS nodes across two AWS Availability Zones (AZ). 4 AWS EFS monitoring. Their technology stack looks like this: Spring Boot-based Microservices. NGINX as an API Gateway.
VPC Flow Logs is an Amazon service that enables IT pros to capture information about the IP traffic that traverses network interfaces in a virtual private cloud, or VPC. By default, each record captures a network internet protocol (IP), a destination, and the source of the traffic flow that occurs within your environment.
In April 2017, Amazon Web Services announced that it would launch a new AWS infrastructure region Region in Sweden. Today, I'm happy to announce that the AWS Europe (Stockholm) Region, our 20th Region globally, is now generally available for use by customers. Public sector.
You also might be required to capture syslog messages from cloud services on AWS, Azure, and Google Cloud related to resource provisioning, scaling, and security events. One change to send syslog to Dynatrace You can now use the syslog ingestion endpoint on Dynatrace Environment ActiveGate for performant network and system monitoring.
Today, I'm happy to announce that the AWS GovCloud (US-East) Region, our 19th global infrastructure Region, is now available for use by customers in the US. With this launch, AWS now provides 57 Availability Zones, with another 12 zones and four Regions in Bahrain, Cape Town, Hong Kong SAR, and Stockholm expected to come online by 2020.
A quick configuration change may do the trick in improving the performance of your AWS RDS for MySQL instance. This segregation facilitates optimized I/O operations, preventing potential bottlenecks and enhancing overall system performance. Amazon RDS extends support for DLVs across various database engines: MariaDB: 10.6.7
We added monitoring and analytics for log streams from Kubernetes and multicloud platforms like AWS, GCP, and Azure, as well as the most widely used open-source log data frameworks. Key information about your system and applications comes from logs. Key information about your system and applications comes from logs.
To improve management of node capabilities , we added Enable/disable Web UI traffic operation for cluster node in Cluster Mission Control UI. Operating systems support. Future Dynatrace Managed operating systems support changes. Future Dynatrace Managed operating systems support changes. Linux: Amazon Linux AMI 2017.x.
Want to save money on your AWS RDS bill? I’ll show you some MySQL settings to tune to get better performance, and cost savings, with AWS RDS. Default settings can help you get started quickly – but they can also cost you performance and a higher cloud bill at the end of the month. After that, things went back to normal.
Cloud services platforms like AWS, Azure, and GCP are reshaping how organizations deliver value to their customers, making cloud migration an increasingly attractive option for running applications. In case of a spike in traffic, you can automatically spin up more resources, often in a matter of seconds. Inconsistent performance.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Netflix shares how Amazon EC2 Auto Scaling allows its infrastructure to automatically adapt to changing traffic patterns in order to keep its audience entertained and its costs on target.
Today, I am very excited to announce our plans to open a new AWS Region in Hong Kong! The new region will give Hong Kong-based businesses, government organizations, non-profits, and global companies with customers in Hong Kong, the ability to leverage AWS technologies from data centers in Hong Kong.
In order to achieve this level of availability, we leverage an N+1 architecture where we treat Amazon Web Services (AWS) regions as fault domains, allowing us to withstand single region failures. So, if we evacuate South American traffic to North America, demand for CE and Android DRM won’t grow uniformly.
takes place in Amazon Web Services (AWS), whereas everything that happens afterwards (i.e., Various software systems are needed to design, build, and operate this CDN infrastructure, and a significant number of them are written in Python. We have created streams of events from a number of systems that get unified into a single tool.
Data is proliferating in separate silos from containers and Kubernetes to open source APIs and software to serverless compute services, such as AWS and Azure. In this case, the bank group could not rely solely on Google Cloud Trace because they needed to collect traces and monitor the applications across all their systems.
Our streaming teams need a monitoring system that enables them to quickly diagnose and remediate problems; seconds count! Our Node team needs a system that empowers a small group to operate a large fleet. It usually has dependencies, talks to other services, and lives in different AWS regions. Regional traffic evacuations.
Today, I am very excited to announce our plans to open a new AWS Region in the Nordics! The new region will give Nordic-based businesses, government organisations, non-profits, and global companies with customers in the Nordics, the ability to leverage the AWS technology infrastructure from data centers in Sweden.
As the number of Titus users increased over the years, the load and pressure on the system increased substantially. cell): Titus Job Coordinator is a leader elected process managing the active state of the system. For example, a batch workflow orchestration system may create multiple jobs which are part of a single workflow execution.
which is difficult when troubleshooting distributed systems. Troubleshooting a session in Edgar When we started building Edgar four years ago, there were very few open-source distributed tracing systems that satisfied our needs. Investigating a video streaming failure consists of inspecting all aspects of a member account.
At AWS, we don't mark many anniversaries. A concept that has changed infrastructure architecture is now at the core of both AWS and customer reliability and operations. Powering the virtual instances and other resources that make up the AWS Cloud are real physical data centers with AWS servers in them.
Due to its popularity, the number of workflows managed by the system has grown exponentially. We started seeing signs of scale issues, like: Slowness during peak traffic moments like 12 AM UTC, leading to increased operational burden. The scheduler on-call has to closely monitor the system during non-business hours.
All these micro-services are currently operated in AWS cloud infrastructure. Can we adjust our auto-scaling policies to be more efficiency without risking our availability during traffic spikes? A majority of the Netflix product features are either partially or completely dependent on one of our many micro-services (e.g.,
Install Falco in AWS EKS to gather security-relevant events from all the happenings in Unguard. To keep it real, we have a load generator that creates benign traffic. For the demonstration in this blog post, we want to deploy Unguard in AWS EKS and hunt for attacks within that environment.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content