This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We’re excited to announce several log management innovations, including native support for Syslog messages, seamless integration with AWS Firehose, an agentless approach using Kubernetes Platform Monitoring solution with Fluent Bit, a new out-of-the-box ingest dashboard, and OpenPipeline ingest improvements.
Although this indexing strategy worked smoothly for a while, interesting challenges started coming up and we started to notice performance issues over time. It was time to take a step back and reevaluate our ES data indexing and sharding strategy. We also changed our mapping strategy to overcome these issues.
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
The three strategies we will discuss today are AB Testing , Replay Testing, and Sticky Canaries. Let’s discuss the three testing strategies in further detail. The control group’s traffic utilized the legacy Falcor stack, while the experiment population leveraged the new GraphQL client and was directed to the GraphQL Shim.
Based on what Andy Jassy, CEO of Amazon Web Services, presented at re:Invent 2018, it seems that the majority is moving their workloads to AWS: These stats tell us that there are a lot of Microsoft related workloads in the public cloud that can be optimized! Setup the Dynatrace AWS CloudWatch Integration. Step #1: Install Dynatrace.
In this post, we compare ScaleGrid’s Bring Your Own Cloud (BYOC) plan vs. the standard Dedicated Hosting model to help you determine the best strategy for your MySQL, PostgreSQL, Redis™ and MongoDB® database deployment. AWS , Azure. AWS , Azure. AWS , Azure. AWS , Azure. AWS , Azure. AWS , Azure.
com and the strategies we use to keep it up and running with high availability. The number of services that compose our product in order to scale our organization and handle the increases in traffic went from under 10 to over 30 services. A lot has changed since then in Auth0. Core service architecture.
Cloud services platforms like AWS, Azure, and GCP are reshaping how organizations deliver value to their customers, making cloud migration an increasingly attractive option for running applications. A cloud migration strategy, however, provides technical optimization that’s also firmly rooted in the business value chain.
Confused about multi-cloud vs hybrid cloud and which is the right strategy for your organization? Real-world examples like Spotify’s multi-cloud strategy for cost reduction and performance, and Netflix’s hybrid cloud setup for efficient content streaming and creation, illustrate the practical applications of each model.
A quick configuration change may do the trick in improving the performance of your AWS RDS for MySQL instance. Overall, adopting this practice promotes a structured and efficient storage strategy, fostering better performance, manageability, and, ultimately, a more robust database environment. and later v10 versions MySQL: 8.0.28
While you may assume a great majority of the cloud database deployments are run on AWS, Azure, or Google Cloud Platform, small to medium-sized businesses in particular are gravitating towards the developer-friendly cloud provider, DigitalOcean , for their hosting for MongoDB® needs. MongoDB Replication Strategies.
In order to achieve this level of availability, we leverage an N+1 architecture where we treat Amazon Web Services (AWS) regions as fault domains, allowing us to withstand single region failures. So, if we evacuate South American traffic to North America, demand for CE and Android DRM won’t grow uniformly.
Install Falco in AWS EKS to gather security-relevant events from all the happenings in Unguard. To keep it real, we have a load generator that creates benign traffic. For the demonstration in this blog post, we want to deploy Unguard in AWS EKS and hunt for attacks within that environment.
We took a hybrid head-based sampling approach that allows for recording 100% of traces for a specific and configurable set of requests, while continuing to randomly sample traffic per the policy set at ingestion point. This implies that the cost of storing traces grows linearly to the amount of data being stored.
At AWS, we don't mark many anniversaries. A concept that has changed infrastructure architecture is now at the core of both AWS and customer reliability and operations. Powering the virtual instances and other resources that make up the AWS Cloud are real physical data centers with AWS servers in them.
Expanding the Cloud - The AWS GovCloud (US) Region. Today AWS announced the launch of the AWS GovCloud (US) Region. The concept of regions gives AWS customers control over the placement of their resources and services. The US Federal Cloud Computing Strategy lays out a â??Cloud All Things Distributed. Comments ().
In this role, I am leading a global team that works closely with our strategic partners such as AWS, Microsoft, Google, Pivotal, Red Hat and others. Resource consumption & traffic analysis. If you want to read up on migration strategies check out my blog on 6-R Migration Strategies. What’s in your stack?”.
With Cloud, we are leveraging the largest cloud providers’ locations, including AWS, Azure, Alibaba and Google coming very soon. With most traffic coming from mobile for many of our customers, and the complexity of the “last mile,” do we really need to be troubleshooting core backbone ISP routing paths?
BT has modernized with AIOps at the center of its digital transformation strategy. For BT, AIOps and digital transformation are at the center of the company’s upcoming three-to-five-year digital transformation strategy. AIOps and digital transformation are at the forefront for BT. BT has 30 million consumer customers, 1.2
An automated deployment system needs to carefully sequence a software update across a fleet while it is actively receiving traffic. Since automated deployments are a fundamental requirement for agile software delivery, we created a new service called AWS CodeDeploy. The applications cannot afford any downtime, planned or otherwise.
With traffic growth, a single leader node handling all request volume started becoming overloaded. Implementation details We solved the cache synchronization problem (as stated above) with a combination of two strategies: Titus Gateway <-> Titus Job Coordinator synchronization protocol over the wire. queries/sec.
As we began growing the AWS business, we realized that external customers might find our Dynamo database just as useful as we found it within Amazon.com. So, we set out to build a fully hosted AWS database service based upon the original Dynamo design.
Nonetheless, we found a number of limitations that could not satisfy our requirements e.g. stalling the processing of log events until a dump is complete, missing ability to trigger dumps on demand, or implementations that block write traffic by using table locks. Blocking write traffic by locking tables. Writing events to any output.
Nonetheless, we found a number of limitations that could not satisfy our requirements e.g. stalling the processing of log events until a dump is complete, missing ability to trigger dumps on demand, or implementations that block write traffic by using table locks. Blocking write traffic by locking tables. Writing events to any output.
At its heart it uses Istio (for traffic control) and Knative (for event driven tool orchestration) and stores all configuration in Git – following the GitOps approach. Pitometer is used to validate a deployment after it was successfully tested based on the defined testing strategy. Bamboo, Azure DevOps, AWS CodePipeline ….
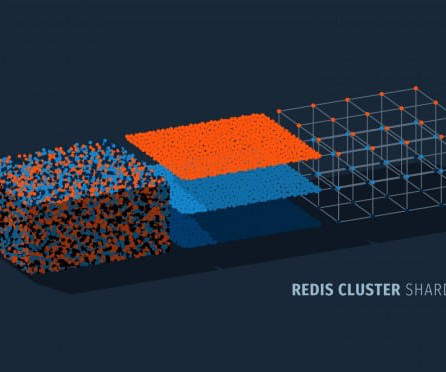
It enhances scalability and manages traffic surges, though it requires specific client support and limits multi-key operations to a single hash slot. Redis Sharding: An Overview Consider Redis Cluster as a multi-lane highway where the lanes represent hash slots, and traffic symbolizes data.
This is to handle the large volume of poll requests coming from subscribed clients without passing on the traffic to the Cassandra cluster. Data resiliency Pinning In the world of application development bad deployments happen, and a common mitigation strategy there is to roll back the deployment.
Despite the potential challenges associated with scaling AI in cloud computing, strategies such as: Obtaining leadership endorsement Establishing ROI indicators Utilizing responsible AI algorithms Addressing data ownership issues can be employed to ensure successful integration.
These pages serve as a pivotal tool in our digital marketing strategy, not only providing valuable information about our services but also designed to be easily discoverable through search engines. It increases our visibility and enables us to draw a steady stream of organic (or “free”) traffic to our site. Bookaway site search.
It was a fascinating read, shedding light on leveraging AWS snapshots’ capabilities to avoid initial data copy within the RDS environment. Then, we need a small downtime window just to move the traffic from the original instance to the upgraded one.
Together, we’ll develop an intuition for the strategies available to Django developers for serving these files to users worldwide in a secure, performant, and cost-effective manner. This strategy is very simple and closely resembles the development environment, but cannot handle large or inconsistent amounts of traffic effectively.
Implementing load balancing has several benefits when it comes to managing workload on the cloud – incoming traffic is equitably spread across various servers or resources, which reduces strain on each resource and ultimately enhances overall system efficiency. Daunting as this may seem initially. </p>
To verify that messages reach their intended recipients without fail, RabbitMQ has implemented diverse strategies for acknowledging message receipt by consumers. Using a message queue approach, RabbitMQ adeptly handles surges in traffic through data queuing. The process doesn’t conclude upon consumption, though.
Now that Database-as-a-service (DBaaS) is in high demand, there are multiple questions regarding AWS services that cannot always be answered easily: When should I use Aurora and when should I use RDS MySQL ? Amazon Aurora is a proprietary, cloud-native, fully managed relational database service developed by Amazon Web Services (AWS).
For instance, Sentinel policies can enforce rules such as "All AWS S3 buckets must have server-side encryption enabled" or "Only specific IAM roles can access certain resources." Restricting access to specific AWS services based on defined IAM roles. Checkov: Checkov is a static code analysis tool.
Building a successful UberEats clone requires a well-planned strategy that takes into account various aspects, including market research, feature prioritization, intuitive design, robust development, and targeted marketing campaigns. By clearly outlining your objectives, you can align your strategies and resources accordingly.
The term "synthetic" is used because it does not rely on traffic generated by real clients and end-users. Canary AWS refers to these synthetic monitors as "canaries" (like "canary in the coal mine"). A canary is a script that can be customized and is typically coded in JavaScript or Python.
It’s not just limited to cloud resources like AWS and Azure; Terraform is versatile, extending its capabilities to key performance areas like Content Delivery Network (CDN) management, ensuring efficient content delivery and optimal user experience.â€Started â€Terraform is a revolution in the way we handle infrastructure.
For example, as the traffic increases, you can allocate two more machines to a particular zone. Every company works on different strategies and is bound in different situations. Sometimes people change their strategy based on the functionalities that a tool has to offer. This is also called serverless computing in general.
That’s why it’s essential to implement the best practices and strategies for MongoDB database backups. In the absence of a proper backup strategy, the data can be lost forever, leading to significant financial and reputational damage. It also supports storing the backups on filesystem and AWS S3 buckets.
In fact, Amazon Web Services (AWS) paved the way with its service, CloudFormation, which introduced the concept of Infrastructure as Code (IaC). Taking inspiration from AWS's CloudFormation, HashiCorp introduced Terraform with a broader vision. Terraform is a revolution in the way we handle infrastructure.
MongoDB data modeling: Understand embedding vs. referencing data MongoDB offers two strategies for storing related data: embedding and referencing. This allows MongoDB to scale horizontally, handling large datasets and high traffic loads. This is because the setting has no use in modern PCIe/NVMe devices.
Starting with the purpose for the system, we can walk through all the steps that provide value to its users, see what might go wrong with each step, come up with an observability and mitigation strategy, and find ways to run chaos experiments to validate our design controls. This is why most AWS regions have three availability zones.
Starting with the purpose for the system, we can walk through all the steps that provide value to its users, see what might go wrong with each step, come up with an observability and mitigation strategy, and find ways to run chaos experiments to validate our design controls. This is why most AWS regions have three availability zones.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content