This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this article, we are going to compare three of the most popular cloud providers, AWS vs. Azure vs. DigitalOcean for their database hosting costs for MongoDB® database to help you decide which cloud is best for your business. We compare AWS vs. Azure vs. DigitalOcean using the below instance types: AWS. Replication Strategy.
If you use AWS cloud services to build and run your applications, you may be familiar with the AWS Well-Architected framework. But this workflow can also help you implement your applications according to each of the AWS Well-Architected pillars.
The 2014 launch of AWS Lambda marked a milestone in how organizations use cloud services to deliver their applications more efficiently, by running functions at the edge of the cloud without the cost and operational overhead of on-premises servers. What is AWS Lambda? Where does Lambda fit in the AWS ecosystem? Dynatrace news.
The three strategies we will discuss today are AB Testing , Replay Testing, and Sticky Canaries. Let’s discuss the three testing strategies in further detail. To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render.
Today, I am very excited to announce our plans to open a new AWS Region in France! Based in the Paris area, the region will provide even lower latency and will allow users who want to store their content in datacenters in France to easily do so. Over the past 10 years, we have seen tremendous growth at AWS.
Mastering Hybrid Cloud Strategy Are you looking to leverage the best private and public cloud worlds to propel your business forward? A hybrid cloud strategy could be your answer. Understanding Hybrid Cloud Strategy A hybrid cloud merges the capabilities of public and private clouds into a singular, coherent system.
While you may assume a great majority of the cloud database deployments are run on AWS, Azure, or Google Cloud Platform, small to medium-sized businesses in particular are gravitating towards the developer-friendly cloud provider, DigitalOcean , for their hosting for MongoDB® needs. MongoDB Replication Strategies.
In this post, we compare ScaleGrid’s Bring Your Own Cloud (BYOC) plan vs. the standard Dedicated Hosting model to help you determine the best strategy for your MySQL, PostgreSQL, Redis™ and MongoDB® database deployment. AWS , Azure. AWS , Azure. AWS , Azure. AWS , Azure. AWS , Azure. AWS , Azure.
DevOps teams operating, maintaining, and troubleshooting Azure, AWS, GCP, or other cloud environments are provided with an app focused on their daily routines and tasks. Davis AI automatically correlates Amazon AWS EC2 and business backend logs.
However, not all cloud strategies are the same. Popular examples include AWS Lambda and Microsoft Azure Functions , but new providers are constantly emerging as this model becomes more mainstream. Reduced latency. By using cloud providers with multiple server sites, organizations can reduce function latency for end users.
A quick configuration change may do the trick in improving the performance of your AWS RDS for MySQL instance. DLVs are particularly advantageous for databases with large allocated storage, high I/O per second (IOPS) requirements, or latency-sensitive workloads. Who can benefit from DLV? and later v10 versions MySQL: 8.0.28
At AWS, we don't mark many anniversaries. A concept that has changed infrastructure architecture is now at the core of both AWS and customer reliability and operations. Powering the virtual instances and other resources that make up the AWS Cloud are real physical data centers with AWS servers in them.
In that scenario, the system would need to deal with the data propagation latency directly, for example, by use of timeouts or client-originated update tracking mechanisms. We started seeing increased response latencies and leader servers running at dangerously high utilization.
Cloud services platforms like AWS, Azure, and GCP are reshaping how organizations deliver value to their customers, making cloud migration an increasingly attractive option for running applications. A cloud migration strategy, however, provides technical optimization that’s also firmly rooted in the business value chain.
If we had an ID for each streaming session then distributed tracing could easily reconstruct session failure by providing service topology, retry and error tags, and latency measurements for all service calls. Using simple lookup indices in Cassandra gives us the ability to maintain acceptable read latencies while doing heavy writes.
Expanding the Cloud - The AWS GovCloud (US) Region. Today AWS announced the launch of the AWS GovCloud (US) Region. The concept of regions gives AWS customers control over the placement of their resources and services. The US Federal Cloud Computing Strategy lays out a â??Cloud All Things Distributed. Comments ().
Balancing Low Latency, High Availability and Cloud Choice Cloud hosting is no longer just an option — it’s now, in many cases, the default choice. For example, AWS offers ‘three nines’, but only if your application runs with triple redundancy in three separate availability zones in the same Amazon data center. Why are they refusing?
While IT organizations have the best of intentions and strategy, they often overestimate the ability of already overburdened teams to constantly observe, understand, and act upon an impossibly overwhelming amount of data and insights. This is also true for Kubernetes and containers that can spin up and down in seconds.
We use Keystone as it is easy to use, reliable, scalable, and provides aggregation of facts from different cloud regions into a single AWS region. Random sampling While the above two strategies combined can detect most data corruptions, they do occasionally miss. and we had no additional information to optimize our queries.
By Anupom Syam Background At Netflix, our current data warehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. These principles reduce resource usage by being more efficient and effective while lowering the end-to-end latency in data processing.
Netflix operates in multiple AWS regions. And we compared two buffering strategies: Fixed Sized Buffering — This is the old technique, where the buffer size is fixed at 8MB (we chose 8MB as a “one-size-fits-all” buffer size after running some experiments across MezzFS use cases at the time). Regional caching? —?Netflix
In this role, I am leading a global team that works closely with our strategic partners such as AWS, Microsoft, Google, Pivotal, Red Hat and others. If you want to read up on migration strategies check out my blog on 6-R Migration Strategies. Step 3: Detailed Traffic Dependency Analysis.
As we began growing the AWS business, we realized that external customers might find our Dynamo database just as useful as we found it within Amazon.com. So, we set out to build a fully hosted AWS database service based upon the original Dynamo design.
It takes you through the thinking processes and engineering practices behind the design of a key part of the control plane for AWS Elastic Block Storage (EBS): the Physalia database that stores configuration information. For Physalia, and for AWS more generally, the guiding principle is minimise the blast radius. NSDI’20.
Despite the potential challenges associated with scaling AI in cloud computing, strategies such as: Obtaining leadership endorsement Establishing ROI indicators Utilizing responsible AI algorithms Addressing data ownership issues can be employed to ensure successful integration.
As a part of that process, we also realized that there were a number of latency sensitive or location specific use cases like Hadoop, HPC, and testing that would be ideal for Spot. By shifting the unit of capacity we are pricing against, customers bidding strategy will directly determine whether or not they are fulfilled. Contact Info.
There are services at Netflix that use RDBMS kind of databases such as MySQL or PostgreSQL via AWS RDS. However, this strategy does not work for all databases. The destination may be a datastore or an external API. Supporting Relational Databases. In the latter case, write traffic is blocked until the dump completes.
There are services at Netflix that use RDBMS kind of databases such as MySQL or PostgreSQL via AWS RDS. However, this strategy does not work for all databases. The destination may be a datastore or an external API. Supporting Relational Databases. In the latter case, write traffic is blocked until the dump completes.
The fundamental principles at play include evenly distributing the workload among servers for better application performance and redirecting client requests to nearby servers to reduce latency. Daunting as this may seem initially. This can vary from simple programs to complex database systems handling numerous query demands. </p>
While ensuring that messages are durable brings several advantages, it’s important to note that it doesn’t significantly degrade performance regarding throughput or latency. To verify that messages reach their intended recipients without fail, RabbitMQ has implemented diverse strategies for acknowledging message receipt by consumers.
These pages serve as a pivotal tool in our digital marketing strategy, not only providing valuable information about our services but also designed to be easily discoverable through search engines. While paid marketing strategies like Google Ads play a part in our approach as well, enhancing our organic traffic remains a major priority.
Now that Database-as-a-service (DBaaS) is in high demand, there are multiple questions regarding AWS services that cannot always be answered easily: When should I use Aurora and when should I use RDS MySQL ? Amazon Aurora is a proprietary, cloud-native, fully managed relational database service developed by Amazon Web Services (AWS).
Twitch developer documentation hosted on AWS, edited on CloudCannon. Platforms such as Snipcart , CommerceLayer , headless Shopify , and Stripe enable you to manage products in a friendly UI while taking advantage of the benefits of Jamstack: Amazon’s famous study reported that for every 100ms in latency, they lose 1% of sales.
It also encompasses a strategy and set of practices and principles across service offerings and is closely tied to DevOps and operations. One minute an SRE might be provisioning storage in AWS, the next minute an SRE might have to talk to customers or go write some Python code for a new project. Monitoring. Incident Response.
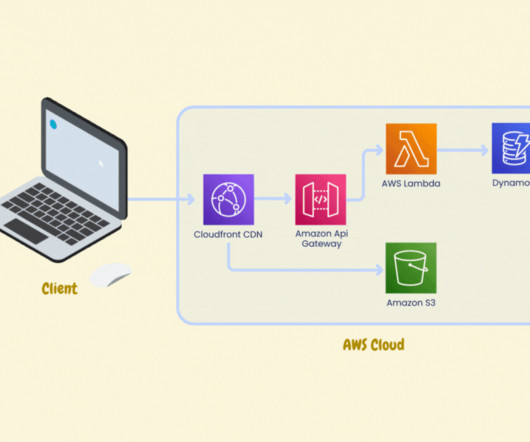
â€Think of a situation where you're asked to build a service in AWS that distributes static content to your users. Your first option is to use its native CDN - Amazon CloudFront, as it seamlessly integrates with all of your other AWS Services that you're using to build your service.â€For What is vendor lock-in?â€Think
Don’t wait till the AWS bill comes in before doing this! Maintain control This may sound a bit crazy, but if you’re going to own the latency/availability SLA, then you need to ‘own’ as much of the call path as possible. The cold truth is that ‘extra nines’ of reliability can add ‘extra zeros’ to the budget. What you own, you control.
In this blog post, we’re going to try to cut through some of the hype to explain why and where companies are struggling the most to monetize their AI/ML data, and explore some strategies around how to face these challenges. So if you’re in this boat with your applications, be sure to: Understand the needs of your audience as far as latency.
That’s why it’s essential to implement the best practices and strategies for MongoDB database backups. In the absence of a proper backup strategy, the data can be lost forever, leading to significant financial and reputational damage. It also supports storing the backups on filesystem and AWS S3 buckets.
Think of a situation where you're asked to build a service in AWS that distributes static content to your users. Later on, your service might require security, and you might use AWS Web Application Firewall, which directly integrates with Amazon CloudFront to help secure your service. What is vendor lock-in?Think
The CFQ works well for many general use cases but lacks latency guarantees. The deadline excels at latency-sensitive use cases ( like databases ), and noop is closer to no schedule at all. MongoDB data modeling: Understand embedding vs. referencing data MongoDB offers two strategies for storing related data: embedding and referencing.
coryodaniel : Rewrote an #AWS APIGateway & #lambda service that was costing us about $16000 / month in #elixir. 12 million requests / hour with sub-second latency, ~300GB of throughput / day. It is time for the world to move to an OS structure appropriate for 21st century security requirements. myelixirstatus !#Serverless.No
Collecting some critical metrics at one second intervals, with a total observability latency of ten seconds or less matches the human attention span much better. This is why most AWS regions have three availability zones. Try to measure your mean time to respond (MTTR) for incidents.
Collecting some critical metrics at one second intervals, with a total observability latency of ten seconds or less matches the human attention span much better. This is why most AWS regions have three availability zones. Try to measure your mean time to respond (MTTR) for incidents.
Its strategies for flow control are either stop-and-wait (i.e., AWS, Kafka, Google Cloud, Spring, ElasticSearch). blocking), discarding data, or none—which can lead to resilience problems, poor performance, or worse: rapid unscheduled disassembly in production. HTTP, TCP, FTP, MQTT, JMS), databases (i.e.,
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content