This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enhancing data separation by partitioning each customer’s data on the storage level and encrypting it with a unique encryption key adds an additional layer of protection against unauthorized data access. A unique encryption key is applied to each tenant’s storage and automatically rotated every 365 days.
Organizations are now looking into solutions that unify security capabilities to protect their environments efficiently. Cloud platforms (AWS, Azure, GCP, etc.) Integrations: Can work across multi-cloud and hybrid-cloud environments, such as AWS, Azure, and Google Cloud Platform, and provide unified visibility and management.
Amazon Web Services (AWS), offers a wide range of serverless solutions. To get a better understanding of AWS serverless, we’ll first explore the basics of serverless architectures, review AWS serverless offerings, and explore common use cases. AWS serverless offerings. Reliability.
We’re excited to announce several log management innovations, including native support for Syslog messages, seamless integration with AWS Firehose, an agentless approach using Kubernetes Platform Monitoring solution with Fluent Bit, a new out-of-the-box ingest dashboard, and OpenPipeline ingest improvements.
If you use AWS cloud services to build and run your applications, you may be familiar with the AWS Well-Architected framework. This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud.
At the AWS re:Invent 2023 conference, generative AI is a centerpiece. The first goal is to demonstrate how generative AI can bring key business value and efficiency for organizations. AWS re:Invent 2023: IT automation in AWS environments through a multipronged AI approach In almost every industry, generative AI has become a key topic.
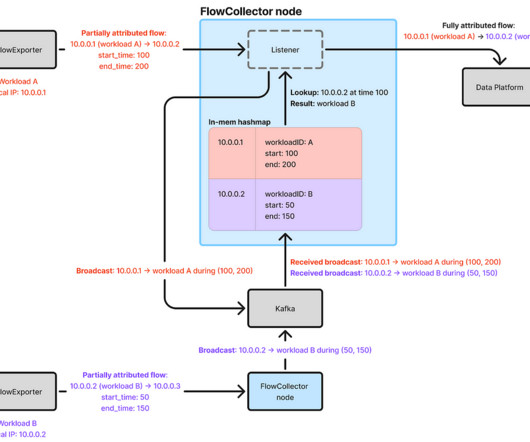
As noted in our previous blog post, our initial attribution approach relied on Sonar , an internal IP address tracking service that emits an event whenever an IP address in Netflixs AWS VPCs is assigned or unassigned to a workload. Netflixs cloud microservices operate across multiple AWS regions. With 30 c7i.2xlarge
Recently, 53 Dynatracers convened in a Zoom room for 5 action-packed hours to take on our first AWS GameDay challenge, an event we participated in to help our developers accelerate their AWS certification path. What is the value of AWS training and certification?
We kick off with a few topics focused on how were empowering Netflix to efficiently produce and effectively deliver high quality, actionable analytic insights across the company. Subsequent posts will detail examples of exciting analytic engineering domain applications and aspects of the technical craft.
This growth was spurred by mobile ecosystems with Android and iOS operating systems, where ARM has a unique advantage in energy efficiency while offering high performance. Energy efficiency and carbon footprint outshine x86 architectures The first clear benefit of ARM in the enterprise IT landscape is energy efficiency.
By Anupom Syam Background At Netflix, our current data warehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. We built AutoOptimize to efficiently and transparently optimize the data and metadata storage layout while maximizing their cost and performance benefits.
The certification focuses on accuracy and transparency in calculating greenhouse gas (GHG) emissions for AWS, Azure, GCP, and on-premises host instances. Storage calculations assume that one terabyte consumes 1.2 Cloud storage is replicated twice, which doubles the energy consumption per terabyte.
Dynatrace has added support for the newly introduced Amazon Virtual Private Cloud (VPC) Flow Logs for AWS Transit Gateway. This new service enhances the user visibility of network details with direct delivery of Flow Logs for Transit Gateway to your desired endpoint via Amazon Simple Storage Service (S3) bucket or Amazon CloudWatch Logs.
Besides the need for robust cloud storage for their media, artists need access to powerful workstations and real-time playback. Local storage and compute services are connected through the Netflix Open Connect network (Netflix Content Delivery Network) to the infrastructure of Amazon Web Services (AWS).
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! To sustain this data growth at Netflix, it has deployed open-source software Ceph using AWS services to achieve the required SLOs of some of the post-production workflows.
Mounting object storage in Netflix’s media processing platform By Barak Alon (on behalf of Netflix’s Media Cloud Engineering team) MezzFS (short for “Mezzanine File System”) is a tool we’ve developed at Netflix that mounts cloud objects as local files via FUSE. Our object storage service splits objects into many parts and stores them in S3.
High performance, query optimization, open source and polymorphic data storage are the major Greenplum advantages. Greenplum’s high performance eliminates the challenge most RDBMS have scaling to petabtye levels of data, as they are able to scale linearly to efficiently process data. Polymorphic Data Storage. Major Use Cases.
In November 2015, Amazon Web Services announced that it would launch a new AWS infrastructure region in the United Kingdom. Today, I'm happy to announce that the AWS Europe (London) Region, our 16th technology infrastructure region globally, is now generally available for use by customers worldwide.
The second focused on the OTel community, with more technical talks by representatives from companies like AWS, Elastic, and more. Trace-based sampling can help you save storage costs. This can help you save money in storage costs in the long run. AWS aims to support the streamlining of observability.
While data lakes and data warehousing architectures are commonly used modes for storing and analyzing data, a data lakehouse is an efficient third way to store and analyze data that unifies the two architectures while preserving the benefits of both. Unlike data warehouses, however, data is not transformed before landing in storage.
Below is a broad technical overview of how to go from an AWS instance to a Netflix Workstation. They could need a GPU when doing graphics-intensive work or extra large storage to handle file management. We rely on our internal partner teams to support components installed on the workstation, such as storage and artist tools.
Anna is not only incredibly fast, it’s incredibly efficient and elastic too: an autoscaling, multi-tier, selectively-replicating cloud service. No, I don’t think that is because AWS is earning a 355x margin on DynamoDB! Each storage server collects statistics about the requests it serves, the data it stores, etc.
A quick configuration change may do the trick in improving the performance of your AWS RDS for MySQL instance. A Dedicated Log Volume (DLV) is a specialized storage volume designed to house database transaction logs separately from the volume containing the database tables. Who can benefit from DLV? and later v13 versions, 14.7
Figure 1: A Simplified Video Processing Pipeline With this architecture, chunk encoding is very efficient and processed in distributed cloud computing instances. From chunk encoding to assembly and packaging, the result of each previous processing step must be uploaded to cloud storage and then downloaded by the next processing step.
Our distributed tracing infrastructure is grouped into three sections: tracer library instrumentation, stream processing, and storage. We earned the trust of our engineers by developing empathy for their operational burden and by focusing on providing efficient tracer library integrations in runtime environments.
At Netflix, we've been using these technologies as they've been made available for instance types in the AWS EC2 cloud. The latest AWS hypervisor, Nitro, uses everything to provide a new hardware-assisted hypervisor that is easy to use and has near bare-metal performance. AWS called this [enhanced networking]. The first was c3.
In April 2017, Amazon Web Services announced that it would launch a new AWS infrastructure region Region in Sweden. Today, I'm happy to announce that the AWS Europe (Stockholm) Region, our 20th Region globally, is now generally available for use by customers. Public sector.
In this blog, we share three log ingestion strategies from the field that demonstrate how building up efficient log collection can be environment-agnostic by using our generic log ingestion application programming interface (API). 3: Ingest AWS Fargate logs with Fluent Bit. Let’s take this example of AWS Fargate.
With Amazon Web Services, the main sources from which to ingest logs—Simple Storage Service, or S3, and CloudWatch —come with an additional cost. As of today’s announcement, AWS and Dynatrace strengthen their commitment to their customers to continue to deliver quality and value. The Dynatrace VPC Flow Log analysis capability.
The processed data is typically stored as data warehouse tables in AWS S3. Therefore, we must efficiently move data from the data warehouse to a global, low-latency and highly-reliable key-value store. As the paved path for moving data to key-value stores, Bulldozer provides a scalable and efficient no-code solution.
Building an elastic query engine on disaggregated storage , Vuppalapati, NSDI’20. Snowflake is a data warehouse designed to overcome these limitations, and the fundamental mechanism by which it achieves this is the decoupling (disaggregation) of compute and storage. joins) during query processing. Disaggregation (or not).
The containerization craze has continued for enterprises, with benefits such as portability, efficiency, and scalability. Serverless container offerings such as AWS Fargate enable companies to manage and modify containers while abstracting server layers to offer customization without increased complexity. million in 2020.
OpenPipeline high-performance filtering and preprocessing provides full ingest and storage control for the Dynatrace platform. As an example, in early preview usage, AWS GuardDuty events were reduced by 84% by filtering out security-irrelevant events, which reduced cost and alert noise at the same time.
Driving this growth is the increasing adoption of hyperscale cloud providers (AWS, Azure, and GCP) and containerized microservices running on Kubernetes. Log analytics also help identify ways to make infrastructure environments more predictable, efficient, and resilient. billion in 2020 to $4.1 Accelerated innovation.
Buckets are similar to folders, a physical storage location. Debug-level logs, which also generate high volumes and have a shorter lifespan or value period than other logs, could similarly benefit from dedicated storage. Suppose a single Grail environment is central storage for pre-production and production systems.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! To sustain this data growth at Netflix, it has deployed open-source software Ceph using AWS services to achieve the required SLOs of some of the post-production workflows.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! To sustain this data growth at Netflix, it has deployed open-source software Ceph using AWS services to achieve the required SLOs of some of the post-production workflows.
Building your applications with only managed components has become very popular, and AWS Lambda plays a crucial role in that. The Mobile Backend reference architecture demonstrates how to use AWS Lambda along with other services to build a serverless backend for a mobile application. about teletext.io are read eagerly around the globe.
Driving Compute Cost Down for AWS Customers. AWS today announced a substantial price drop from March 1, 2012 for many of the Amazon EC2, Amazon RDS, and Amazon ElastiCache instances types around the world. Driving costs down for our customers is part of the DNA of Amazon and therefore also part of the DNA of AWS. Comments ().
Building your applications with only managed components has become very popular, and AWS Lambda plays a crucial role in that. The Mobile Backend reference architecture demonstrates how to use AWS Lambda along with other services to build a serverless backend for a mobile application. about teletext.io are read eagerly around the globe.
Additionally, we’ve implemented security measures in the ScaleGrid Control Panel and introduced Point in Time Restore (PITR) for PostgreSQL on AWS , a feature soon available across all clouds and databases.
The first version of our logger library optimized for storage by deduplicating facts and optimized for network i/o using different compression methods for each fact. Since we were optimizing at the logging level for storage and performance, we had less data and metadata to play with to optimize the query performance.
Driving Bandwidth Cost Down for AWS Customers. Any work we can do to improve over these dimensions generates long term benefits for AWS customers. Our account managers periodically call customers to work with them to see if there are opportunities to create better efficiencies and lower bills. Countdown to What is Next in AWS.
The second focused on the OTel community, with more technical talks by representatives from companies like AWS, Elastic, and more. Trace-based sampling can help you save storage costs. This can help you save money in storage costs in the long run. AWS aims to support the streamlining of observability.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content