This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
This is a recording of a breakout session from AWS Heroes at re:Invent 2022, presented by AWS Hero Zainab Maleki. In software engineering, we've learned that building robust and stable applications has a direct correlation with overall organization performance. Posted with permission.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
by Shefali Vyas Dalal AWS re:Invent is a couple weeks away and our engineers & leaders are thrilled to be in attendance yet again this year! Technology advancements in content creation and consumption have also increased its data footprint. We’ve compiled our speaking events below so you know what we’ve been working on.
This post focuses on elevating our dataengineering game, streamlining your data workflows, and significantly cutting computing costs. The need to optimize offline data pipeline optimization has become a necessity with the growing complexity and scale of modern data pipelines.
All these micro-services are currently operated in AWS cloud infrastructure. As a micro-service owner, a Netflix engineer is responsible for its innovation as well as its operation, which includes making sure the service is reliable, secure, efficient and performant. Give us a holler if you are interested in a thought exchange.
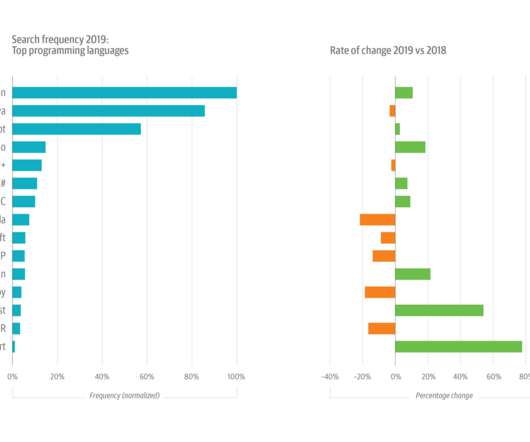
The results for data-related topics are both predictable and—there’s no other way to put it—confusing. Starting with dataengineering, the backbone of all data work (the category includes titles covering data management, i.e., relational databases, Spark, Hadoop, SQL, NoSQL, etc.). This follows a 3% drop in 2018.
We adopted the following mission statement to guide our investments: “Provide a complete and accurate data lineage system enabling decision-makers to win moments of truth.” We are loading the lineage data to a graph database to enable seamless integration with a REST data lineage service to address business use cases.
Finally, when all matching is done and data is written the new table is committed so it can be read by other jobs. Compute: Titus Whereas open-source users of Metaflow rely on AWS Batch or Kubernetes as the compute backend , we rely on our centralized compute-platform, Titus.
By Anupom Syam Background At Netflix, our current data warehouse contains hundreds of Petabytes of data stored in AWS S3 , and each day we ingest and create additional Petabytes. Some of the optimizations are prerequisites for a high-performance data warehouse.
Sustainability at AWS re:Invent 2022 -All the talks and videos I could find… Las Vegas MSG Sphere under construction next door to the Venetian Sands Expo Center — Photo by Adrian This blog post is long overdue — I spent too long trying to find time to watch all the videos, and finally gave up and listed a few below that I haven’t seen.
Service Segmentation: The ease of the cloud deployments has led to the organic growth of multiple AWS accounts, deployment practices, interconnection practices, etc. VPC Flow Logs VPC Flow Logs is an AWS feature that captures information about the IP traffic going to and from network interfaces in a VPC.
As I mentioned, we live in a world where massive volumes of data are being generated, every day, from connected devices, websites, mobile apps, and customer applications running on top of AWS infrastructure. Auto-discovery : One of the challenges with BI is discovering and accessing the data.
AWS recently announced the general availability (GA) of Amazon EC2 P5 instances powered by the latest NVIDIA H100 Tensor Core GPUs suitable for users that require high performance and scalability in AI/ML and HPC workloads. The GA is a follow-up to the earlier announcement of the development of the infrastructure. By Steef-Jan Wiggers
However, the data infrastructure to collect, store and process data is geared toward developers (e.g., In AWS’ quest to enable the best data storage options for engineers, we have built several innovative database solutions like Amazon RDS, Amazon RDS for Aurora, Amazon DynamoDB, and Amazon Redshift.
Learn the stuff they don't teach you in the AWS docs. Filter out the distracting hype, and focus on the parts of AWS that you'd be foolish not to use. Learn the Good Parts of AWS. Created by former senior-level AWSengineers of 15 years. Advertise your job here! Cool Products and Services.
Cloud certifications, specifically in AWS and Microsoft Azure, were most strongly associated with salary increases. As we’ll see later, cloud certifications (specifically in AWS and Microsoft Azure) were the most popular and appeared to have the largest effect on salaries. The top certification was for AWS (3.9% The Last Word.
The AWS team launched this week Amazon Glacier , a cold storage archive service at the very low price point of $0.01 Which makes this week a good moment to read up on some of the historical work around the costs of dataengineering. I am in the midst of my South America tour in the beautiful but very cold Santiago, Chile.
Canva evaluated different data massaging solutions for its Product Analytics Platform, including the combination of AWS SNS and SQS, MKS, and Amazon KDS, and eventually chose the latter, primarily based on its much lower costs. The company compared many aspects of these solutions, like performance, maintenance effort, and cost.
As the usage increased, we had to vertically scale the system to keep up and were approaching AWS instance type limits. increasing at > 100% a year, the need for a scalable data workflow orchestrator has become paramount for Netflix’s business needs. Meson was based on a single leader architecture with high availability.
Where aws ends and the internet begins is an exercise left to the reader. The folks on the Cloud DataEngineering (CDE) team, the ones building the paved path for internal data at Netflix, graciously helped us scale it up and make adjustments, but it ended up being an involved process as we kept growing.
I was fortunate to be both presenting a 2-day workshop (on AWS Serverless Architectures and Continuous Deployment) as well as hosting a full-day Serverless track of talks. This has proved especially true in the last couple of months, as we helped a company update it’s entire AWS infrastructure in a number of critical ways. Great stuff!
Airflow provides rich scheduling and execution semantics enabling dataengineers to easily define complex pipelines, running at regular intervals. In reality, a DAG lacks the necessary workflow context, and relying solely on it can result in incomplete solutions and missed opportunities.
Zendesk reduced its data storage costs by over 80% by migrating from DynamoDB to a tiered storage solution using MySQL and S3. The company considered different storage technologies and decided to combine the relational database and the object store to strike a balance between querybility and scalability while keeping the costs down.
By J Han , PallaviPhadnis Context At Netflix, we use Amazon Web Services (AWS) for our cloud infrastructure needs, such as compute, storage, and networking to build and run the streaming platform that we love. In turn, our self-serve platforms allow teams to create and deploy, sometimes custom, workloads more efficiently.
Entirely new paradigms rise quickly: cloud computing, dataengineering, machine learning engineering, mobile development, and large language models. It’s less risky to hire adjunct professors with industry experience to fill teaching roles that have a vocational focus: mobile development, dataengineering, and cloud computing.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content