This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Furthermore, it was difficult to transfer innovations from one model to another, given that most are independently trained despite using common data sources. Yet, many are confined to a brief temporal window due to constraints in serving latency or training costs.
The standard dictionary subscript notation is also available. Scaling experiments with Metaboost bindingsbacked by MetaflowConfig Consider a Metaboost ML project named `demo` that creates and loads data to custom tables (ETL managed by Maestro), and then trains a simple model on this data (ML Pipeline managed by Metaflow).
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability.
address these limitations and brings new monitoring and analytical capabilities that weren’t available to Extensions 1.0: What’s available now and what’s coming later We’ve already started to migrate Dynatrace-developed Extensions 1.0 available, and more are in the pipeline. Extensions 2.0 to the Extension Framework 2.0.
Your trained eye can interpret them at a glance, a skill that sets you apart. Activate Davis AI to analyze charts within seconds Davis AI can help you expand your dashboards and dive deeper into your available data to extract additional information. This is where Davis AI for exploratory analytics can make all the difference.
On April 22, 2022, I received an out-of-the-blue text from Sam Altman inquiring about the possibility of training GPT-4 on OReilly books. And now, of course, given reports that Meta has trained Llama on LibGen, the Russian database of pirated books, one has to wonder whether OpenAI has done the same. We chose one called DE-COP.
As of C++26 almost the entire language and much of the standard library is available at compile time, and is UB-free when executed at compile time (but not when the code is executed at run time, hence the following additional work all of which is about run-time execution). (2) Most people just didnt notice.
The way we train juniors, whether it’s at university or in a boot camp or whether they train themselves from the materials we make available to them (Long Live the Internet), we imply from the very beginning that there’s a correct answer. If it has, it’s usually codified into a language, framework, or library.
Like OpenAIs GPT-4 o1, 1 its training has emphasized reasoning rather than just reproducing language. That seemed like something worth testing outor at least playing around withso when I heard that it very quickly became available in Ollama and wasnt too large to run on a moderately well-equipped laptop, I downloaded QwQ and tried it out.
In evaluating our model’s accuracy in understanding performance/errors and behavior, we use historical real user data and a standard 80-20 train-test split to train our model. Get started Opportunity Insights is available with the Dynatrace Business Insights service.
Observability is a topic at the top of mind for all architects, Site Reliability Engineers (SREs), and more – each wanting to use observability to proactively detect issues and guarantee the best experience and availability to users. The training program to proactively improve your services. We can now move to the training phase.
Dynatrace’s ability to ingest metrics from all 95 AWS services will be available within the next 60 days. Those in the left column are readily available now, with those in the right available soon. Available Now. Achieve full observability of all AWS services. Coming Soon. AWS AppSync. AWS CloudHSM. Amazon AppStream 2.0.
Augmenting LLM input in this way reduces apparent knowledge gaps in the training data and limits AI hallucinations. The LLM then synthesizes the retrieved data with the augmented prompt and its internal training data to create a response that can be sent back to the user. million AI server units annually by 2027, consuming 75.4+
Reasons for using RAG are clear: large language models (LLMs), which are effectively syntax engines, tend to “hallucinate” by inventing answers from pieces of their training data. See the primary sources “ REALM: Retrieval-Augmented Language Model Pre-Training ” by Kelvin Guu, et al., at Facebook—both from 2020.
A series of models are continuously trained on Dynatrace tenants to effectively set objectives. The training times and other quality metrics, such as the RMSE (Root Mean Squared Error), SMAPE (Scaled Mean Absolute Percentage Error), and coverage probability, are monitored using Dynatrace.
To address the first challenge, we use pre trained sentence-level embeddings, e.g. from an embedding model optimized for paraphrase identification , to represent text in both sources. However, it presupposes the availability of high-quality screenplays.
While this approach can be effective if the model is trained with a large amount of data, even in the best-case scenarios, it amounts to an informed guess, rather than a certainty. Because IT systems change often, AI models trained only on historical data struggle to diagnose novel events. That’s where causal AI can help.
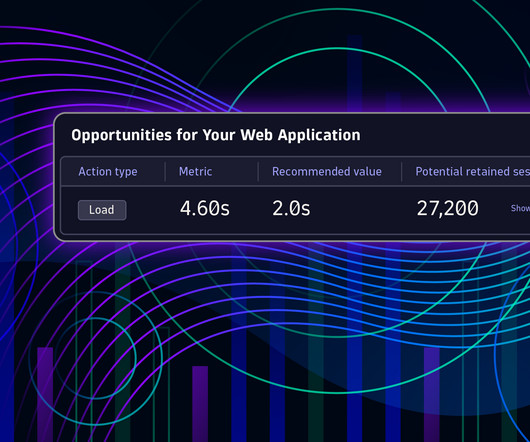
One effective capacity-management strategy is to switch from a reactive approach to an anticipative approach: all necessary capacity resources are measured, and those measurements are used to train a prediction model that forecasts future demand. Select any line in the chart to display the available actions for that line.
Although model-based anomaly detection approaches are more scalable and suitable for real-time analysis, they highly rely on the availability of (often labeled) context-specific data. In semi-supervised anomaly detection models, only a set of benign examples are required for training.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
Practical use cases for speech & music activity Audio dataset preparation Speech & music activity is an important preprocessing step to prepare corpora for training. Content, genre and languages Instead of augmenting or synthesizing training data, we sample the large scale data available in the Netflix catalog with noisy labels.
On the other hand, very few data scientists feel strongly about the nature of the data warehouse, the compute platform that trains and scores their models, or the workflow scheduler. In this hypothetical example, the flow trains two versions of a model in parallel and chooses the one with the highest score.
These integrations are implemented through Metaflow’s extension mechanism which is publicly available but subject to change, and hence not a part of Metaflow’s stable API yet. In addition to Spark, we want to support last-mile data processing in Python, addressing use cases such as feature transformations, batch inference, and training.
The combined ability of Dynatrace and our partners to address this growing TAM with efficient, high-speed land and expand deals is underpinned by the 530+ cloud services and technology integrations available on the Dynatrace Hub. Training & Certification Award: Accenture. Partner Pro Club. Rising Star Award: Evolving Solutions.
The combined ability of Dynatrace and our partners to address this growing TAM with efficient, high-speed land and expand deals is underpinned by the 530+ cloud services and technology integrations available on the Dynatrace Hub. Training & Certification Award: Accenture. Partner Pro Club. Rising Star Award: Evolving Solutions.
To avoid this issue, you have to implement extra steps in your continuous deployment process to make outdated resources available for longer periods of time. To enable user experience monitoring for the application, DevOps would have to configure the server to make the CSS resources available without authentication.
By carving the right AWS certification path, developers can even use their certification and training to advance their careers long term. What is the value of AWS training and certification? You and your peers – if you team up – can benefit on multiple levels from AWS training and certification.
Well, that’s exactly what the Dynatrace University team did to support Dynatrace’s hands-on training (HoT) days at Dynatrace’s annual user conference Perform in Las Vegas. The Dynatrace dashboard below that shows the thousands of EC2 instances coming up and then being removed at the close of the training. Quite impressive! The results.
These organizations rely heavily on performance, availability, and user satisfaction to drive sales and retain customers. While gyms and fitness studios have since reopened, these apps are still extremely popular for squeezing in short home workouts, tracking fitness goals, and receiving personalized training recommendations.
Benefits of a GUI in Database Management The following are the solutions to the problems with CLIs that GUIs bring 3 : Reducing the high degree of memorization and training needed to apply the syntax of the terminal commands by providing an intuitive visual interface. Lacks some advanced coding and debugging tools available in other products.
Some of the Greenplum Database analytics capabilities highlighted by Pivotal include the ability to analyze a multitude of data types, leverage existing SQL knowledge, and train more models in less time by using the MPP architecture.
Starting small is important for building a strong foundation, and an expert team will provide the necessary platform for training motivated staff to execute each mission with pride and precision. To hear more about VA’s journey to modernization, the full webinar, hosted by FCW and sponsored by Dynatrace, is available here.
It takes times to train statistics-based machine learning solutions, and this approach doesn’t scale easily with modern, dynamic cloud-native environments. While this statistics-based approach can find and prioritize many alerts, it still relies on humans to analyze the output and determine the root cause of any anomalies or errors.
Choose the most promising subset of tests out of thousands of test cases available when running continuous integration against a device. We thought that reinforcement learning would be a promising approach that could provide great flexibility in the training process. We also provide an API client in Python.
Large language models (LLMs), which are the foundation of generative AIs, are neural networks: they learn, summarize, and generate content based on training data. Davis AI with predictive AI and causal AI is generally available and used by all Dynatrace customers. Start your free trial now!
We built Axion primarily to remove any training-serving skew and make offline experimentation faster. These facts are managed and made available by services like viewing history or video metadata services outside of Axion. Our machine learning models train on several weeks of data. Time is a critical component of Axion?—?When
Such a solution needs to collect a substantial amount of data at first for then having a dataset (training data) that an algorithm can use to learn from. It works without identifying training data, then training and honing. Traditional AIOps is Slow. The first downside to the ML approach is that it is slow. Conclusion.
The team behind Dynatrace University has always pushed themselves to achieve more and provide its users with up to date content.And with that, we’re excited to announce Dynatrace University 2020 is now available! Now available in your language! What’s changing? And that’s not all.
You told us you wanted more hands-on training (HOT) Days, so you could attend more sessions, learn more about Dynatrace, and network with your fellow attendees. This year at Perform Las Vegas 2020 , we’re ramping up our Dynatrace University offerings because we know this is one of your favorite parts of attending Perform. Register now.
Resource consumption: Observing computational resource availability and saturation, whether deployed in cloud-native environments like Kubernetes or CPU-enabled servers. Data quality and drift: Monitoring the quality and characteristics of training and runtime data to detect significant changes that might impact model accuracy.
Another key benefit of cloud computing is its reliability and availability. Additionally, because cloud computing services are provided by large, established companies, they are typically highly reliable and available, with robust security and privacy measures in place to protect user data. Which cloud provider would you recommend?
Machine learning algorithms use vast amounts of data to train systems and allow them to draw accurate conclusions based on available information. Supervised learning uses already-labeled data to train algorithms for specific outputs. There are two broad types of machine learning: supervised and unsupervised.
Much of the ML literature focuses on model training, evaluation, and scoring. We must quickly surface the most stand-out highlights from the titles available on our service in the form of images and videos in the member experience. First, we must provide the content that will bring them joy. Artists and video editors must create them.
The subject line said: “Success Story: Major Issue in single AWS Frankfurt Availability Zone!” The problem started at 1:24PM PDT, with the services starting to become available again about 3 hours later. Fact #4: Multi-node, multi-availability zone deployment architecture. Ready to learn more? Rack-aware Cassandra deployments.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content