This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Find what you’re looking for faster with: Enhanced charting and data visualization: Easily filter, group, search, and visualize trace data to gain deeper insights into your system’s behavior. The new Services app is already available to all DPS and non-DPS customers. stay tuned for more enhancements and features.
By Ko-Jen Hsiao , Yesu Feng and Sudarshan Lamkhede Motivation Netflixs personalized recommender system is a complex system, boasting a variety of specialized machine learned models each catering to distinct needs including Continue Watching and Todays Top Picks for You. Refer to our recent overview for more details).
To this end, we developed a Rapid Event Notification System (RENO) to support use cases that require server initiated communication with devices in a scalable and extensible manner. In this blog post, we will give an overview of the Rapid Event Notification System at Netflix and share some of the learnings we gained along the way.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
For years, enterprises managed observability data on a team-by-team basis , using a combination of ticketing systems and configuration management tools. The application consists of several microservices that are available as pod-backed services. Stay tuned for more awesome Dynatrace Kubernetes announcements throughout the year.
Note that the developers of the respective services need to make these metrics available by exposing them via, for example, a Prometheus endpoint that can be used by the OpenTelemetry collector to ingest them and forward them to your Dynatrace tenant. So, stay tuned for more enhancements and features. This is just the beginning.
Both categories share common requirements, such as high throughput and high availability. Failures in a distributed system are a given, and having the ability to safely retry requests enhances the reliability of the service. The table below provides a detailed overview of the diverse requirements across these two categories.
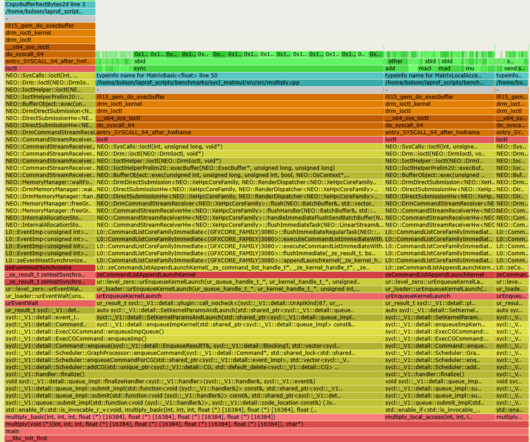
Part 3: System Strategies and Architecture By: VarunKhaitan With special thanks to my stunning colleagues: Mallika Rao , Esmir Mesic , HugoMarques This blog post is a continuation of Part 2 , where we cleared the ambiguity around title launch observability at Netflix. The request schema for the observability endpoint.
Having released this functionality in an Early Adopter Release with OneAgent version 1.173 and Dynatrace version 1.174 back in August 2019, we’re now happy to announce the General Availability of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux. Host-performance measures.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. As you went through these steps, you likely noticed some of the chart options available. Welcome, data enthusiasts! That’s where Dynatrace dashboards come in.
Introduction to Message Brokers Message brokers enable applications, services, and systems to communicate by acting as intermediaries between senders and receivers. This decoupling simplifies system architecture and supports scalability in distributed environments.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This technique facilitates validation on multiple fronts.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Key Takeaways RabbitMQ improves scalability and fault tolerance in distributed systems by decoupling applications, enabling reliable message exchanges.
Oracle Database is a commercial, proprietary multi-model database management system produced by Oracle Corporation, and the largest relational database management system (RDBMS) in the world. Compare PostgreSQL vs. Oracle functionality across available tools, capabilities and services. Not available. Not available.
We’re happy to announce the Early Adopter Release of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux (available with OneAgent version 1.173 and Dynatrace version 1.174). For details on available metrics, see our help page on host performance monitoring.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. Recovery time of the latency p90.
Our first version is available to customers in the Intel Tiber AI Cloud as a preview for the Intel Data Center GPU Max Series (previously called Ponte Vecchio). Earlier this year I posted about the final missing piece: Helping distros enable frame pointers so that profiling works across standard system libraries. Process tools.
So, those of you limited to Windows-only systems can now also enjoy all the goodness of having HTTP monitors deliver API testing right to your door! Support for Windows-based ActiveGates is now available with ActiveGate version 1.165. Internal application availability monitoring. Why use synthetic HTTP monitors?
These regulations place demands on providers to meet key requirements to ensure the operational resilience and availability of critical financial services. With an automatic observability platform, teams can receive alerts when the system has burned through the impact tolerance. For financial services firms in the U.K.,
We must quickly surface the most stand-out highlights from the titles available on our service in the form of images and videos in the member experience. We implemented a batch processing system for users to submit their requests and wait for the system to generate the output. Maintaining disparate systems posed a challenge.
Network Availability: The expected continued growth of our ecosystem makes it difficult to understand our network bottlenecks and potential limits we may be reaching. After several iterations of the architecture and some tuning, the solution has proven to be able to scale.
Do you keep an eye on the support of distributions and versions of operating systems within your environment? With this information, you can find answers to questions such as: Which operating systems and versions does Dynatrace support? Which operating systems and versions does Dynatrace support? What about ActiveGates?
This step lets you fine-tune your query to identify all matching data points, ensuring a thorough and accurate retrieval process. Once the data in Grail that matches the run query is returned, a second authorized user reviews the results in terms of volume (the number of log records, volume, data residency, and the number of systems).
However, setting the right parameters for Kubernetes clusters to ensure application availability, performance, and resilience while avoiding overspending isn’t a walk in the park. Tuning thousands of parameters has become an impossible task to achieve via a manual and time-consuming approach. The Akamas approach. lower than 2%.).
Get the latest insights on MySQL , MongoDB , PostgreSQL , Redis , and many others to see which database management systems are most favored this year. Based on our findings, SQL still holds 60% with rising demand for systems such as PostgreSQL: SQL Database Use: 60.48%. SQL vs. NoSQL. NoSQL Database Use: 39.52%. Most Popular Databases.
With the availability of Linux on IBM Z and LinuxONE, the IBM Z platform brings a familiar host operating system and sustainability that could yield up to 75% energy reduction compared to x86 servers. Deploying your critical applications on additional host operating systems increases the dependencies for observability.
With almost 100 public locations worldwide, Dynatrace Synthetic Monitoring enables 24/7 measurement of the availability and performance of your applications as experienced by your customers and coworkers worldwide. You can start monitoring the availability and performance of your applications now. Try it out for yourself. What’s next.
Observability is a topic at the top of mind for all architects, Site Reliability Engineers (SREs), and more – each wanting to use observability to proactively detect issues and guarantee the best experience and availability to users. Usual exceptions raised by our system that is now considered to be normal by Davis. Slow degradations.
The AB experiment results hinted that GraphQL’s correctness was not up to par with the legacy system. The Replay Testing framework leverages the @override directive available in GraphQL Federation. We set up a client-side AB experiment that tested Falcor versus GraphQL and reported coarse-grained quality of experience metrics ( QoE ).
We’re happy to announce that the new Environment API is now available in the Cluster API in an Early Adopter release. The endpoint is designed in a RESTful way, so the typical resource layout with all CRUD functionality is available. With POST , the system automatically creates an environment ID for you.
Running metric queries on a subset of entities for live monitoring and system overviews. The Metrics API v2 is the first v2 API available in Dynatrace. Metrics API v2 is designed in a RESTful way to allow you to discover which metrics are available, retrieve metadata, and to execute sophisticated time series queries.
In Part I , we introduced a High Availability (HA) framework for MySQL hosting and discussed various components and their functionality. Semisynchronous replication, which is natively available in MySQL, helps the HA framework to ensure data consistency and redundancy for committed transactions.
You’re half awake and wondering, “Is there really a problem or is this just an alert that needs tuning? Our streaming teams need a monitoring system that enables them to quickly diagnose and remediate problems; seconds count! Our Node team needs a system that empowers a small group to operate a large fleet. By Andrei U.,
Stay tuned for an upcoming blog series where we’ll give you a more hands-on walkthrough of how to ingest any kind of data from StatsD, Telegraf, Prometheus, scripting languages, or our integrated REST API. Once you send metrics via the OneAgent REST API, the relevant hosts are automatically enriched with all available monitoring dimensions.
I wanted to understand how I could tune Dynatrace’s problem detection, but to do that I needed to understand the situation first. This is what I wanted to optimize and avoid and many traditional (or homegrown) systems aren’t doing this. For example, invoking a webhook that creates a ticket in an ITSM system.
This is not a general rule, but as databases are responsible for a core layer of any IT system – data storage and processing — they require reliability. Availability solutions – Advanced backups, including physical backups and point-in-time recovery that are not available to MongoDB Community Edition.
This article gives an overview of the system. As the system evolves to solve more and more use cases, we have expanded its scope to handle not only the CDC use cases but also more general data movement and processing use cases such that: Events can be sourced from more generic applications (not only databases).
Today, we are excited to announce the release of Percona Monitoring and Management (PMM) V2.35 , including a tech preview of label-based access control, the general availability of Helm Chart, and a range of enhancements to our Database as a Service (DBaaS) offerings, among other improvements and features. Stay tuned!
Central to this infrastructure is our use of multiple online distributed databases such as Apache Cassandra , a NoSQL database known for its high availability and scalability. This flexibility allows our Data Platform to route different use cases to the most suitable storage system based on performance, durability, and consistency needs.
How viewers are able to watch their favorite show on Netflix while the infrastructure self-recovers from a system failure By Manuel Correa , Arthur Gonigberg , and Daniel West Getting stuck in traffic is one of the most frustrating experiences for drivers around the world. Logs and background requests are examples of this type of traffic.
Although model-based anomaly detection approaches are more scalable and suitable for real-time analysis, they highly rely on the availability of (often labeled) context-specific data. Streaming Platforms Commercial streaming platforms shown in Figure 1 mainly rely on Digital Rights Management (DRM) systems.
As we look at today’s applications, microservices, and DevOps teams, we see leaders are tasked with supporting complex distributed applications using new technologies spread across systems in multiple locations. For most systems, an optimum MTTR could be less than one hour while others have an MTTR of less than one day.
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. It’s low because certain machines and operating systems do not support higher values.
In addition, Davis provides automatic alerting of service-to-service communication problems using queues and other event systems. Within the next 90 days, all enhancements mentioned in this blog post will be available to all Dynatrace customers. Stay tuned for updates. 2 Automatic detected queues anomaly by AI engine Davis.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content