This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When first working on a new site-speed engagement, you need to work out quickly where the slowdowns, blindspots, and inefficiencies lie. In a separate sheet—available at the same link as before —I’ve simply graphed the data by page type. Now, let’s move on to gaps between First Contentful Paint and Speed Index.
This dual-path approach leverages Kafkas capability for low-latency streaming and Icebergs efficient management of large-scale, immutable datasets, ensuring both real-time responsiveness and comprehensive historical data availability. Thus, all data in one region is processed by the Flink job deployed within thatregion.
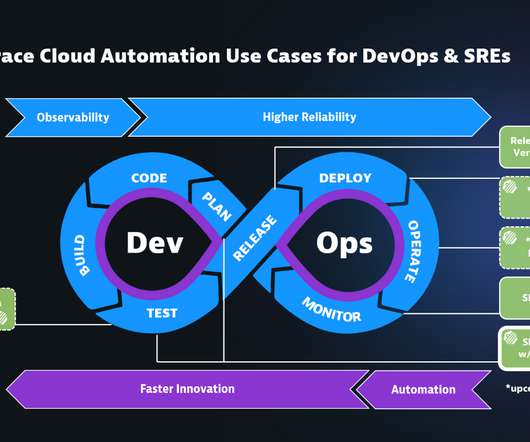
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. As you went through these steps, you likely noticed some of the chart options available. Also, explore additional dashboards available on the Dynatrace Playground.
Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing. It follows a push-based approach, ensuring messages are distributed to consumers as soon as they become available.
Optimized fault recovery We’re also interested in exploring the potential of tuning configurations to improve recovery speed and performance after failures and avoid the demand for additional computing resources. In Kafka Streams, a large configuration space is available for potential optimizations.
However, setting the right parameters for Kubernetes clusters to ensure application availability, performance, and resilience while avoiding overspending isn’t a walk in the park. Tuning thousands of parameters has become an impossible task to achieve via a manual and time-consuming approach. The Akamas approach. Additional resources.
In Part I , we introduced a High Availability (HA) framework for MySQL hosting and discussed various components and their functionality. Semisynchronous replication, which is natively available in MySQL, helps the HA framework to ensure data consistency and redundancy for committed transactions.
Automate delivery processes: Ideally, an improvement entails introducing automation to eliminate manual tasks, foster collaboration, or speed up processes. Stay tuned Currently, the API allows for the configuration of an event processing pipeline. In-depth analysis of delivery tasks using tools like Notebooks.
Dynatrace Synthetic Monitoring allows you to proactively monitor the availability of your public as well as your internal web applications and API endpoints from locations around the globe or important internal locations such as branch offices. These metrics are tightly connected to the perceived load speed of your application.
With today’s high expectations for the speed and availability of applications, you need a deep understanding of real user experiences to make the best business decisions. Dynatrace Synthetic Monitoring ensures that your application is available and performs well from anywhere in the world to meet your SLAs. Dynatrace news.
This enables effective DevSecOps collaboration, as well as observability-driven automation against all critical metrics (speed, security, stability, availability, productivity, and business metrics) at enterprise scale. All Dynatrace enhancements mentioned in this blog post will be available within the next 90 days.
Other category, including migrations, queries, comparing, tuning, and replication. Query speed is an extremely important metric to track on a continuous basis so you can identify slow-running queries that could be affecting your application performance. The more memory you have available, the better your database should perform.
Did this issue result from the order in which the user added the data or the speed with which they selected the UI controls? . In such cases, the crash can be analyzed only by using the information that’s available on the session details page. What makes this session different from other sessions that follow the same path?
As companies strive to innovate and deliver faster, modern software architecture is evolving at near the speed of light. Dynatrace is thrilled to announce the General Availability of support for both the 2.x So stay tuned! Dynatrace news. AI-powered observability and end-to-end tracing of serverless applications.
Since becoming General Availability in the fall of 2019 , GitHub Actions has helped teams automate continuous integration and continuous delivery (CI/CD) workflows for code builds, tests, and deployments. Keeping business stakeholders in the loop with end-to-end observability with deep insight and continuous feedback loops?. #2
Let’s consider the business challenges of an online shop that is powered by a microservice architecture where several instances of each microservice run, including the shopping cart service, to ensure the highest possible availability. Stay tuned for upcoming announcements around OpenTracing and OpenTelemetry. What’s next?
In today’s world, the speed of innovation is key to business success. We will further enhance the detection and blocking capability to cover additional attack types, so stay tuned for updates! Real-time attack detection and blocking for Java will be available in the next 120 days. Dynatrace news. How to get started.
And if you absolutely have to have it on a device, most of them are available via Kindle as well. If you’re looking to read optimization ideas from one of the greatest minds in speed performance, look no further. If these rules can be applied to improving speeds at Yahoo! Let’s get started! – Aurel V.
To speed up release frequency, they’re investing in delivery-pipeline automation. The flip side of speeding up delivery, however, is that each software release comes with the risk of impacting your goals of availability, performance, or any business KPIs.
As teams try to gain insight into this data deluge, they have to balance the need for speed, data fidelity, and scale with capacity constraints and cost. In most cases, especially with more complex queries, Grail gives you answers at five to 100 times more speed than any other database you can use right now.”
Establishing clear, consistent, and effective quality gates that are automatically validated at each phase of the delivery pipeline is essential for improving software quality and speeding up delivery. Automating quality gates creates reliable checks and balances and speeds up the process by avoiding manual intervention.
In this post, we will discuss some important kernel parameters that can affect database server performance and how these should be tuned. vm.overcommit_ratio is the percentage of RAM that is available for overcommitment. You need to set a value of vm.dirty_background_bytes depending on your disk speed. SHMMAX / SHMALL.
Measuring the speed of time Is there already a microbenchmark for os::javaTimeMillis()? Checking those available: $ cat /sys/devices/system/clocksource/clocksource0/available_clocksource. Microbenchmark os::javaTimeMillis() on both systems. Try changing the kernel clocksource.
These can include business metrics, such as conversion rates, uptime, and availability; service metrics, such as application performance; or technical metrics, such as dependencies to third-party services, underlying CPU, and the cost of running a service. availability of a website over a year, your error budget is.05%. Be adaptable.
This week my colleague Michael Winkler announced the general availability of Cloud Automation quality gates , a new capability that aims to provide answer-driven release validation as part of your delivery process. We have seen users who joined our preview program “speed up their release validation by 90%”.
To achieve this goal, the Encoding Technologies team made the following design decisions about AV1 encoding recipes: We always encode at the highest available source resolution and frame rate. The Encoding Technologies team took a first stab at this problem by fine-tuning the encoding recipe. Stay tuned!
In our increasingly digital world, the speed of innovation is key to business success. As a result, e xisting application security approaches can’t keep up with this speed and vari ability of modern development processes. . Stay tuned – this is only the start. Dynatrace news.
As companies strive to innovate and deliver faster, modern software architecture is evolving at near the speed of light. Dynatrace is thrilled to announce the General Availability of support for both the 2.x So stay tuned! Dynatrace news. AI-powered observability and end-to-end tracing of serverless applications.
Indexes are generally considered to be the panacea when it comes to SQL performance tuning, and PostgreSQL supports different types of indexes catering to different use cases. I keep seeing many articles and talks on “tuning” discussing how creating new indexes speeds up SQL but rarely ones discussing removing them.
Network Availability: The expected continued growth of our ecosystem makes it difficult to understand our network bottlenecks and potential limits we may be reaching. It is easier to tune a large Spark job for a consistent volume of data. And in order to gain visibility into these logs, we need to somehow ingest and enrich this data.
the brilliant synth-pop score or the perfectly mixed soundscape of a high speed chase?—?is The top graph shows both the audio and video bitrate, along with the available network throughput. Imagine this scene without the sound. Even taking away one part of the soundtrack?—?the is the story nearly as thrilling and emotional?
Storage mount points in a system might be larger or smaller, local or remote, with high or low latency, and various speeds. Sometimes these locations landed on mount points which, due to capacity, availability, or access constraints, weren’t well suited for large runtime storage. Stay tuned for upcoming news about these changes.
While many AWS users default to their managed database solution, Amazon RDS, there are alternatives available that can improve your MySQL performance on AWS through advanced customization options and unlimited EC2 instance type support. Reads and writes to your Primary, and even reads from Slave-1 will work at SSD speed.
Nowadays, solid-state drives (SSDs) or non-volatile memory express (NVMe) drives are preferred over traditional hard disk drives (HDDs) for database servers due to their faster read and write speeds, lower latency, and improved reliability. Typically a good value is 70%-80% of available memory.
Log analysis can reveal potential bottlenecks and inefficient configurations so teams can fine-tune system performance. Digital experience monitoring including real-user monitoring, synthetic monitoring, and mobile app monitoring to ensure every application is available, responsive, fast, and efficient across every channel.
By adding Flutter support, we’re giving you more freedom to choose what best fits your use case and available resources. Be sure to fine-tune the anomaly detection settings for your mobile app so that you can focus on those anomalies that are most relevant to the experience of your end users.
For that, we focused on OpenTelemetry as the underlying technology and showed how you can use the available SDKs and libraries to instrument applications across different languages and platforms. Here, we can find statistics on the overall availability of the database, connections, queries, and errors. What is OneAgent?
With Dynatrace version 1.194, the following new metrics are immediately available on your Multidimensional analysis, Waterfall analysis, and User action details pages: First paint : The time spent from navigation to when the browser renders the first non-default background element. Get started with just a few clicks. Prerequisites.
Kubernetes was architected to allow for additional technologies and services to assist in speed, scalability and reducing the overall complexity which can arise from a Microservices environment. Yet as a platform, it is in no way considered a standalone environment, containing all the functionality needed for Cloud Native development.
Throughout this evolution, we’ve been able to maintain high availability and a consistent message delivery rate, with Pushy successfully maintaining 99.999% reliability for message delivery over the last few months. This delicate balance led to us doing a deep evaluation of many instance types and performance tuning options.
The eval process combines: Human review Model-based evaluation A/B testing The results then inform two parallel streams: Fine-tuning with carefully curated data Prompt engineering improvements These both feed into model improvements, which starts the cycle again. The AI is taking too long to reply; we need to speed it up.
For many traditional web applications , User action duration is considered the best metric available for web-performance optimization. There are other applications where the UI isn’t as important as the speed of interaction with the application. You’ll have at least 30 days of historical performance data available.
Sample GraphQL Schema Once entities like the above are available in the graph, it’s very common for folks to want to query for a particular entity based on attributes of related entities, e.g. give me all movies that are currently in photography with Ryan Reynolds as an actor. We continue to manage tradeoffs between reindexing speed and load.
Out of the box, the default PostgreSQL configuration is not tuned for any particular workload. It is primarily the responsibility of the database administrator or developer to tune PostgreSQL according to their system’s workload. What is PostgreSQL performance tuning? Why is PostgreSQL performance tuning important?
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content