This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the final post of this series, we will review the last solution, Patroni by Zalando, and compare all three at the end so you can determine which high availability framework is best for your PostgreSQL hosting deployment. Managing High Availability in PostgreSQL – Part I: PostgreSQL Automatic Failover. Standby ServerTests.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. Effective management of failover and switchover operations is crucial for high availability.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. into NAM test definitions. Our script, available on GitHub , provides details.
In a MySQL master-slave high availability (HA) setup, it is important to continuously monitor the health of the master and slave servers so you can detect potential issues and take corrective actions. MySQL Master Server Health Checks. Important Health Checks for your MySQL Master-Slave Servers Click To Tweet.
MySQL does not limit the number of slaves that you can connect to the master server in a replication topology. A classic solution for this problem is to deploy a binlog server – an intermediate proxy server that sits between the master and its slaves. Ripple is an open source binlog server developed by Pavel Ivanov.
Use Cases and Requirements At Netflix, our counting use cases include tracking millions of user interactions, monitoring how often specific features or experiences are shown to users, and counting multiple facets of data during A/B test experiments , among others. With this approach, the counts continually converge to their latest value.
When deploying in production, it’s highly recommended to setup in a MongoDB replica set configuration so your data is geographically distributed for high availability. We often undertake testing of failover characteristics of various MongoDB drivers to qualify them for production use cases, or when our customers ask us for advice.
We will show you exactly how to deploy a Nodejs app to the server using Docker containers, RDS Amazon Aurora, Nginx with HTTPS, and access it using the Domain Name. Amazon Aurora is a MySQL and PostgreSQL-compatible relational database available on AWS. We will deploy a Nodejs app to the server, Nginx, and Certbot as Docker containers.
As you may agree, it is important to test your code. Often I saw that this is not tested thoroughly or not at all. With Testcontainers , writing integration tests has become a commodity. The library is available on Maven Central and Github for everyone.
Wondering which high availability framework to use for your PostgreSQL deployments ? We compared the top 3 frameworks, PostgreSQL Automatic Failover (PAF) vs. Replication Manager (repmgr) vs. Patroni , in our Managing High Availability in PostgreSQL series. PostgreSQL High Availability Framework Infographic.
Having released this functionality in an Early Adopter Release with OneAgent version 1.173 and Dynatrace version 1.174 back in August 2019, we’re now happy to announce the General Availability of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux. Host-performance measures.
The three strategies we will discuss today are AB Testing , Replay Testing, and Sticky Canaries. Before GraphQL: Monolithic Falcor API implemented and maintained by the API Team Before moving to GraphQL, our API layer consisted of a monolithic server built with Falcor. To launch Phase 1 safely, we used AB Testing.
You can use it to visualize CPU utilization across your hosts, disk space used, server-side response time, web request/service failure rates, or any other area where you need to spot outliers immediately. To achieve the best visual outcome, we recommend experimenting with the available customization options. Try different cell shapes.
This blog post will provide a detailed analysis of replay traffic testing, a versatile technique we have applied in the preliminary validation phase for multiple migration initiatives. In this testing strategy, we execute a copy (replay) of production traffic against a system’s existing and new versions to perform relevant validations.
DevOps platform engineers are responsible for cloud platform availability and performance, as well as the efficiency of virtual bandwidth, routers, switches, virtual private networks, firewalls, and network management. Open source CI/CD pipeline tool with extensible server automation for distributed builds and scaling. Atlassian Jira.
If you must kill the script at this point, there are two options available: SCRIPT KILL command can be used to stop a script that hasn’t yet done any writes. If the script has already performed writes to the server and must still be killed, use the SHUTDOWN NOSAVE to shutdown the server completely. 26379 @ test 172.31.2.48
An example launchpad for developer audiences Summary It doesn’t matter if you shift left to fix bugs early in your Software Development Life Cycle or shift right to ensure code quality, testing, and release of a new feature. Enhance your developers experience with analytics and automation throughout the software delivery process.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it.
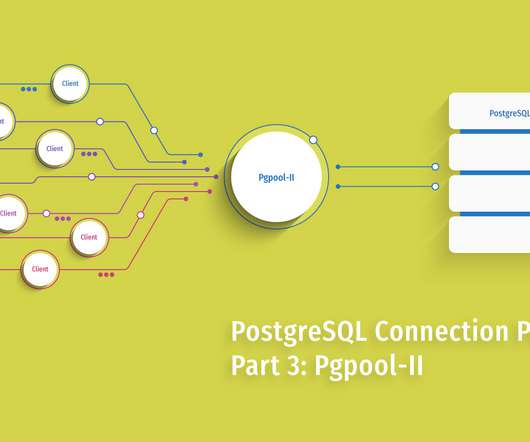
It supports high-availability, provides automated load balancing, and has the intelligence to balance load between masters and slaves so write loads are always directed at masters, while read loads are directed to slaves. Once installed, we must configure Pgpool-II to enable the services we want, and connect to the PostgreSQL server.
Too many concurrent server requests can lead to website crashes if youre not equipped to deal with them. The good news is that you can maximize availability and prevent website crashes by designing websites specifically for these events. You can free up space and reduce the load on your server by compressing and optimizing images.
Available directly from the AWS Marketplace , Dynatrace provides full-stack observability and AI to help IT teams optimize the resiliency of their cloud applications from the user experience down to the underlying operating system, infrastructure, and services. How does Dynatrace help?
This article is to simply report the YCSB bench test results in detail for five NoSQL databases namely Redis, MongoDB, Couchbase, Yugabyte and BangDB and compare the result side by side. I have also used the default six test scenarios as defined by the YCSB framework. I have restricted it to 10M records for each test.
They were either running their own infrastructure and installing and deploying Brotli everywhere proved non-trivial, or they were using a CDN who didn’t have readily available support for the new algorithm. Taking a very reductive and simplistic view of how files are transmitted from server to client, we need to look at TCP.
We’re happy to announce the Early Adopter Release of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux (available with OneAgent version 1.173 and Dynatrace version 1.174). For details on available metrics, see our help page on host performance monitoring. Dynatrace news.
Development and QA process Assessing a vendor’s testing and quality assurance (QA) capabilities reveals their approach and commitment to validating changes and preventing new issues. Vendors take different testing and QA approaches, ranging from simple crash testing to newer strategies such as canary and blue-green.
Recently I covered some of the T-SQL improvements in SQL Server 2022 here , and Aaron Bertrand covered additional improvements here. Microsoft just announced the release of SQL Server 2022 CTP 2.1. For example, suppose that prior to SQL Server 2022 you had the following query: SELECT. So far so good. FROM T1 INNER JOIN T2 ON T1.
Facilitating remote access to other computers or servers with easier navigation. Learning Resources: Are there tutorials, guides, and comprehensive documentation available for the tool? Cross-Platform Compatibility: Is the tool available on multiple operating systems (Windows, macOS, Linux)?
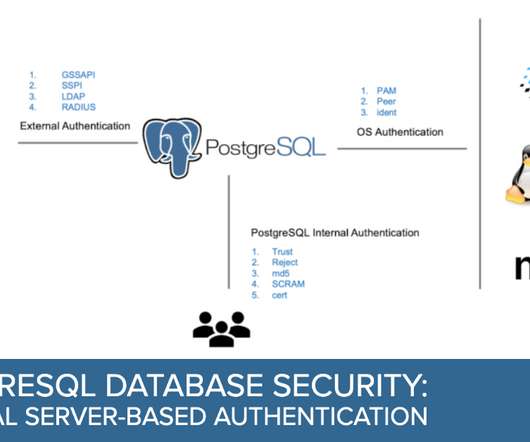
PostgreSQL server authentication refers to verifying the identity of a user trying to connect to the PostgreSQL server. The pg_hba.conf file is used to configure the authentication methods the PostgreSQL server uses and can specify different methods for different types of connections.
In this post, we outline the best way to host MySQL on Azure , including managed solutions, instance types, high availability replication, backup, and disk types to use to optimize your cloud database performance. High Availability Deployment. So, how do we configure high availability for MySQL on Azure?
When it comes to access to their applications, users demand instant, reliable, and secure interactions — and that means databases must be highly available. With database high availability (HA), services are largely uninterrupted, and end users are largely satisfied. The obvious answer is this: To achieve high availability.
It looks like we succeeded, and I’m happy to announce that Percona Distribution for PostgreSQL 16 is now available! To highlight some: Logical replication from standby servers is now supported natively by PostgreSQL. We plan to make Percona images for PostgreSQL available on Docker Hub shortly.
Cloud providers then manage physical hardware, virtual machines, and web server software management. This enables teams to quickly develop and test key functions without the headaches typically associated with in-house infrastructure management. Increased availability. Increased testing complexity. Limited visibility.
When deploying MongoDB in production, it is strongly recommended that you use an SSL-enabled geo-distributed replica-set configuration for maximum security and availability. One option is purchasing your own CA-signed SSL certificates and configuring them on the MongoDB server. ScaleGrid provides you two options for setting up SSL.
Automatically run thousands of automated tests. Ensure manual penetration testing. All steps are fully automated, from source code being compiled to binaries, to the upload of the binaries to the AWS infrastructure where they are available for customers to download. Automatically sign and verify during installation.
Is my database cluster still highly available? All of our high availability options are offered in DigitalOcean, including 2 Replicas + 1 Arbiter, 3 Replicas and custom replica set setups. DigitalOcean does not have the concept of availability zones (AZ), so we distribute the nodes across different regions. High performance.
We continue to grow our public synthetic monitoring locations, but customers using Dynatrace Synthetic still need to monitor the performance and availability of internal web applications. With private synthetic browser monitors, we bring the testing capabilities available in public locations right into your own environment.
Comprehensive documentation is available on the website but let’s walk through an example to show you how easy it is to use this framework. Just start the Spring Boot application, and the /graphql endpoint will be available, along with the GraphiQL query editor on /graphiql that comes out of the box. Let’s start with a simple schema.
Common user action metrics (or performance testing metrics) measured and monitored in DEM include the following: User action duration. The time from browser request to the first byte of information from the server. Use synthetic monitoring to conduct regular tests and identify potential issues before they impact real users.
After a new build gets deployed and automated tests executed, SLIs are evaluated against their SLOs and, depending on that result, a build is considered good (promoted) or bad (rolled back). “ The app description and supporting files such as load testing scripts are on the Keptn Example GitHub. This is what this blog is all about.
EXPLAIN without the ANALYSE gives you the server’s estimated analysis of the performance of your query. Add in INVISIBLE INDEXes, and you can test the efficiency of an index without risking a disastrous rebuild after a delete. But before going with the MySQL Community Edition, you should look at Percona Server for MySQL.
With the average cost of unplanned downtime running from $300,000 to $500,000 per hour , businesses are increasingly using high availability (HA) technologies to maximize application uptime. Where a high availability design once worked well, it can no longer keep up with more complex requirements.
The transition to Apple Silicon (the M1, M2 ARM-based CPUs) has been great for macOS fans in many ways, but it’s added some friction when you want to run containers locally for testing or development. The good news is we’ve got you covered with ARM64 container images for Percona Server for MongoDB 6. Prefer working with Podman?
MySQL Server – Community Edition The problem applies to all versions of the upstream MySQL Community up to 8.0.23. Here is an example scenario you may end up here: mysql > select @@version,@@version_comment; + --+ + | @@version | @@version_comment | + --+ + | 5.7.43 | MySQL Community Server (GPL) | + --+ + 1 row in set (0.00
Stable, well-calibrated SLOs pave the way for teams to automate additional processes and testing throughout the software delivery lifecycle. In this example, “Reverse proxy” and “Front-end server” are clearly in the critical path. Availability. SLOs promote automation. SLOs minimize downtime. Reliability.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content