This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the final post of this series, we will review the last solution, Patroni by Zalando, and compare all three at the end so you can determine which high availability framework is best for your PostgreSQL hosting deployment. Managing High Availability in PostgreSQL – Part I: PostgreSQL Automatic Failover. Standby Server Tests.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. Effective management of failover and switchover operations is crucial for high availability.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. into NAM test definitions. Our script, available on GitHub , provides details.
Use Cases and Requirements At Netflix, our counting use cases include tracking millions of user interactions, monitoring how often specific features or experiences are shown to users, and counting multiple facets of data during A/B test experiments , among others. This setup simplifies facilitating idempotency checks and resetting counts.
Synthetic testing simulates real-user behaviors within an application or service to pinpoint potential problems. Here’s a look at why this testing matters, how it works, and what companies need to get the most from this approach. What is synthetic testing? RUM, meanwhile, requires actual users.
To verify the quality of everything that is rendered on the cloud environment, Cloud testing was performed running manual or automation testing or both. The entire process of Cloud Testing is operated online with the help of the required infrastructure.
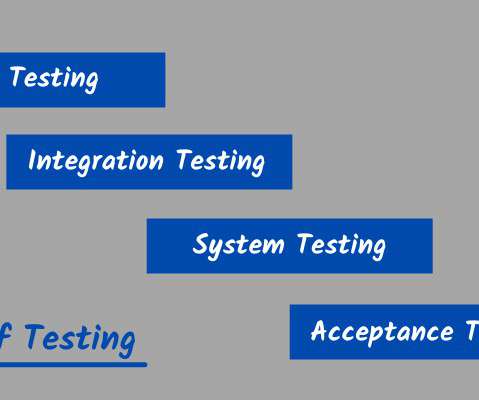
The goal of Levels of Testing is to make software testing more structured and efficient, as well as to make it easier to identify all availabletest cases and test scenarios at a given level. All of these steps go through the software testingprocess's tiers of testing.
This powerful tool can be leveraged across various environments, including production, to enhance development processes and ensure robust application performance. White box testing The nicest thing about deploying UI changes to production is that you can immediately see the changes in action.
As every developer knows, logs are crucial for uncovering insights and detecting fundamental flaws, such as process crashes or exceptions. Using Live Debugger, we immediately get insights into the running code, including variable values, process and thread information, and even a trace ID for the captured transaction.
Having released this functionality in an Early Adopter Release with OneAgent version 1.173 and Dynatrace version 1.174 back in August 2019, we’re now happy to announce the General Availability of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux. Release details.
Integration with existing systems and processes : Integration with existing IT infrastructure, observability solutions, and workflows often requires significant investment and customization. The certification results are now publicly available.
Wait.what is Monkey Testing? You may also like: Introduction to the World of Mobile Application Testing. What Is Monkey Testing? Android Monkey is the python-based testing script process that can be run by writing any specific python script or we can directly apply a test for the installed application using the command line.
DevOps platform engineers are responsible for cloud platform availability and performance, as well as the efficiency of virtual bandwidth, routers, switches, virtual private networks, firewalls, and network management. Open source automated browser and testing tool. ” What does a DevOps platform engineer do? Atlassian Jira.
A key learning from the outage caused by the faulty CrowdStrike “Rapid Response” update is how critical it is to understand your vendors’ quality control and release processes. Thorough testing reduces the risk of outages and vulnerabilities from untested updates, showcasing the vendor’s commitment to reliable and compatible solutions.
Automation testing tools are designed to execute automated test scripts to validate software requirements, both functional and non-functional. Automation testing technologies facilitate the creation, execution, and maintenance of tests effortlessly while providing a consolidated view of test result analytics.
Test tools are software or hardware designed to test a system or application. Various test tools are available for different types of testing, including unit testing, integration testing, and more.
This blog post will provide a detailed analysis of replay traffic testing, a versatile technique we have applied in the preliminary validation phase for multiple migration initiatives. In this testing strategy, we execute a copy (replay) of production traffic against a system’s existing and new versions to perform relevant validations.
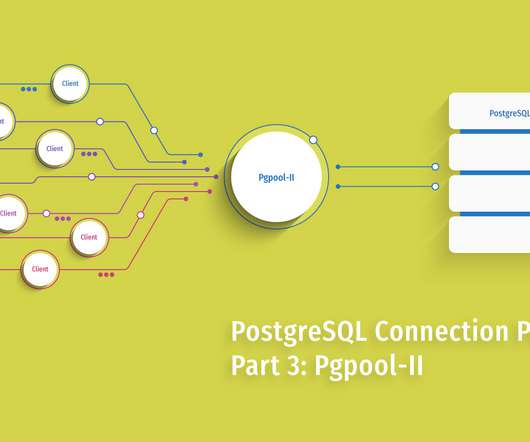
It supports high-availability, provides automated load balancing, and has the intelligence to balance load between masters and slaves so write loads are always directed at masters, while read loads are directed to slaves. The Pgpool-II parent process forks 32 child processes by default – these are available for connection.
In this blog post, we’ll discuss the methods we used to ensure a successful launch, including: How we tested the system Netflix technologies involved Best practices we developed Realistic Test Traffic Netflix traffic ebbs and flows throughout the day in a sinusoidal pattern. Basic with ads was launched worldwide on November 3rd.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
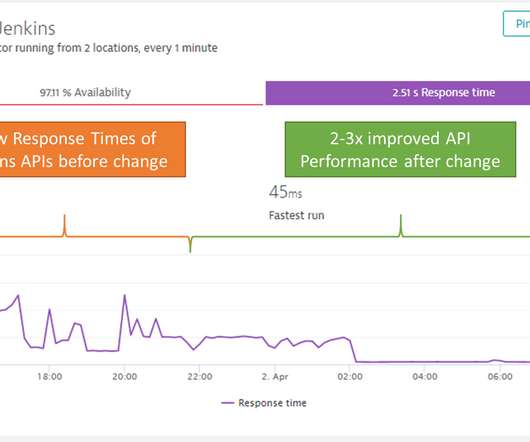
Dynatrace also alerted on intermittent outages throughout the day and especially after 8pm when the bulk of the nightly jobs were executed: On March 31st our Jenkins violated our SLAs from both availability and user experience.
With the increasing amount of sensitive information stored and processed, it’s essential to ensure that systems are secure and protected against potential threats. High false-positive rates: Traditional security testing tools generate numerous findings.
The most commonly used one is dataflow project , which helps folks in managing their data pipeline repositories through creation, testing, deployment and few other activities. Generally, we prefer to execute DDL commands as part of the workflow itself, instead of running outside of the schedule, because it simplifies the development process.
Automatically run thousands of automated tests. Ensure manual penetration testing. Track changes via our change management process. All steps are fully automated, from source code being compiled to binaries, to the upload of the binaries to the AWS infrastructure where they are available for customers to download.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Shift-left using an SRE approach means that reliability is baked into each process, app and code change.
Your next challenge is ensuring your DevOps processes, pipelines, and tooling meet the intended goal. For example, by measuring deployment frequency daily or weekly, you can determine how efficiently your team is responding to process changes. Lead time for changes helps teams understand how effective their processes are.
Today, development teams suffer from a lack of automation for time-consuming tasks, the absence of standardization due to an overabundance of tool options, and insufficiently mature DevSecOps processes. This process begins when the developer merges a code change and ends when it is running in a production environment.
Available directly from the AWS Marketplace , Dynatrace provides full-stack observability and AI to help IT teams optimize the resiliency of their cloud applications from the user experience down to the underlying operating system, infrastructure, and services. How does Dynatrace help?
These organizations rely heavily on performance, availability, and user satisfaction to drive sales and retain customers. AvailabilityAvailability SLO quantifies the expected level of service availability over a specific time period. Availability is typically expressed in 9’s, such as 99.9%. or 99.99% of the time.
DevOps is focused on optimizing software development and delivery, and SRE is focused on operations processes. DevOps is not a specific process, but rather a general collection of flexible software creation and delivery practices that looks to close the gap between software development and IT operations. DevOps as a philosophy.
Our previous blog post presented replay traffic testing — a crucial instrument in our toolkit that allows us to implement these transformations with precision and reliability. A process that doesn’t just minimize risk, but also facilitates a continuous evaluation of the rollout’s impact.
When organizations implement SLOs, they can improve software development processes and application performance. Stable, well-calibrated SLOs pave the way for teams to automate additional processes and testing throughout the software delivery lifecycle. Availability. SLOs improve software quality. SLOs promote automation.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Shift-left using an SRE approach means that reliability is baked into each process, app and code change.
Speed, UX, availability, and frequency of updates are increasingly important with mobile apps. The responsibility of developers keeps growing, and as mobile apps get more complex, new tools for mobile performance monitoring and testing are being born. But this process usually takes a couple of weeks.
Ideally, we would have causal estimates from an A/B test to use for validation, but since that is not available, we use another causal inference design as one of our ensemble of validation approaches. Each format has a different production process and different patterns of cash spend, called our Content Forecast.
In short, combining development and operations makes it possible for process to keep pace with progress. Consulting firm Deloitte notes that technology teams are now expected to deliver projects four times faster with the same budget, and most of that budget goes toward running the business — not process or software innovation.
Modern applications—enterprise and consumer—increasingly depend on third-party services to create a fast, seamless, and highly available experience for the end-user. API monitoring is the process of collecting and analyzing data about the performance of an API in order to identify problems that impact users. Dynatrace news.
You can also use it to test different OpenTelemetry features and evaluate how they appear on backends. All the needed components are available out of the box in the OpenTelemetry collector contrib distribution, which is included in the demo application. Next, select one of the log lines to view the available attributes.
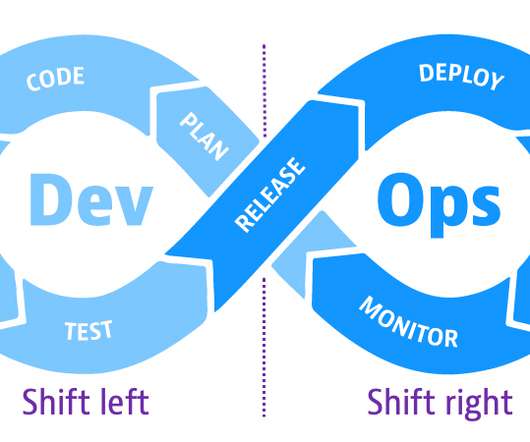
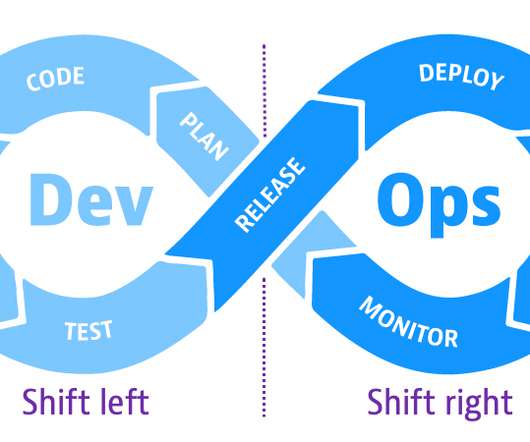
On the left side of the loop, teams plan, develop, and test software in pre-production. When teams release software into production on the right side of the loop, they make the software available to users. With shift right, DevOps teams test a built application to ensure performance, resilience, and software reliability.
On the left side of the loop, teams plan, develop, and test software in pre-production. When teams release software into production on the right side of the loop, they make the software available to users. With shift right, DevOps teams test a built application to ensure performance, resilience, and software reliability.
Container security is the practice of applying security tools, processes, and policies to protect container-based workloads. If containers are run with privileged flags, or if they receive details about host processes, they can easily become points of compromise for corporate networks. Source code tests.
WebKit have recently announced their intent to implement the blocking=render attribute for and elements, bringing them in line with support already available in Blink and generally positive sentiment in Firefox. The resource is fetched and processed asynchronously while the browser is free to work on whatever other tasks there may be.
When it comes to access to their applications, users demand instant, reliable, and secure interactions — and that means databases must be highly available. With database high availability (HA), services are largely uninterrupted, and end users are largely satisfied. The obvious answer is this: To achieve high availability.
Protect customers with software development lifecycle integrations Software testing is critical, yet issues can still make it into production that negatively impact the customer experience. It supports A/B testing, canary releases, and quick rollbacks, ensuring smoother transitions and more controlled feature releases.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content