This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today, we’re excited to present the Distributed Counter Abstraction. In this context, they refer to a count very close to accurate, presented with minimal delays. Both categories share common requirements, such as high throughput and high availability. The challenge lies in determining the appropriate number of buckets.
In the final post of this series, we will review the last solution, Patroni by Zalando, and compare all three at the end so you can determine which high availability framework is best for your PostgreSQL hosting deployment. Managing High Availability in PostgreSQL – Part I: PostgreSQL Automatic Failover. Kill the PostgreSQL process.
Ensuring smooth operations is no small feat, whether you’re in charge of application performance, IT infrastructure, or business processes. The market is saturated with tools for building eye-catching dashboards, but ultimately, it comes down to interpreting the presented information.
The application consists of several microservices that are available as pod-backed services. From here we jump directly into Dynatrace Distributed traces view, shown below, to understand code-level contributions to total processing time. Information about each of these topics will be available in upcoming announcements.
This feature, available by default for OTel-instrumented services, allows users a standard way to measure and compare response times across different services consistently. The span metrics connector creates these measurements and presents them as histograms, which can be analyzed in Dynatrace for deeper insights.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. Are the corresponding services running on those hosts?
Having been named as a Leader in the 2020 Gartner APM Magic Quadrant for the 10 th consecutive time proves that Dynatrace is the best-of-breed application performance monitoring tool available. But what happens if a service work perfectly but the underlying infrastructure, such as processes and hosts, experience an outage?
The Grail™ data lakehouse provides fast, auto-indexed, schema-on-read storage with massively parallel processing (MPP) to deliver immediate, contextualized answers from all data at scale. However, data overload and skills shortages present challenges that companies need to address to maximize the benefits of cloud and AI technologies.
Kickstart your creation journey using ready-made dashboards and notebooks Creating dashboards and notebooks from scratch can take time, particularly when figuring out available data and how to best use it. Kickstarting the dashboard creation process is, however, just one advantage of ready-made dashboards.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
Grafana Loki is a horizontally scalable, highly available log aggregation system. Logs can also be transformed appropriately for presentation, for example, or further pipeline processing. It is designed for simplicity and cost-efficiency. Loki can provide a comprehensive log journey.
As a result, requests are uniformly handled, and responses are processed cohesively. This data is processed from a real-time impressions stream into a Kafka queue, which our title health system regularly polls. Many of the metadata and assets involved in title setup have specific timelines for when they become available to members.
Heres what stands out: Key Takeaways Better Performance: Faster write operations and improved vacuum processes help handle high-concurrency workloads more smoothly. Improved Vacuuming: A redesigned memory structure lowers resource use and speeds up the vacuum process. Start your free trial today!
This article is the second in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Each format has a different production process and different patterns of cash spend, called our Content Forecast. Need to catch up?
Health information on SNMP devices is often isolated and discovered devices are not placed in the correct context, failing to fulfill the goal of the discovery process: associating SNMP device data with the IT environments where the devices reside. Start the configuration process for the SNMP Autodiscovery extension.
RabbitMQ is designed for flexible routing and message reliability, while Kafka handles high-throughput event streaming and real-time data processing. RabbitMQ follows a message broker model with advanced routing, while Kafkas event streaming architecture uses partitioned logs for distributed processing. What is Apache Kafka?
Available directly from the AWS Marketplace , Dynatrace provides full-stack observability and AI to help IT teams optimize the resiliency of their cloud applications from the user experience down to the underlying operating system, infrastructure, and services. How does Dynatrace help?
WebKit have recently announced their intent to implement the blocking=render attribute for and elements, bringing them in line with support already available in Blink and generally positive sentiment in Firefox. The resource is fetched and processed asynchronously while the browser is free to work on whatever other tasks there may be.
In this example, well deploy the OpenTelemetry demo application to send telemetry directly to Dynatrace using OTLP so you can see how Dynatrace presents the OTel data without the additional context OneAgent provides. Next, select one of the log lines to view the available attributes. metrics from span data.
Observability data presents executives with new opportunities to achieve this, by creating incremental value for cloud modernization , improved business analytics , and enhanced customer experience. With the latest advances from Dynatrace, this process is instantaneous.
Our partner community plays a vital role in facilitating this transition by effectively communicating the benefits of SaaS and ensuring a seamless migration process. Dynatrace SaaS presents a lower total cost of ownership (TCO), enabling customers to consolidate various tools, thereby optimizing costs and enhancing internal user experiences.
To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. This is especially true when the goal is to present information to non-technical users, but all technical teams can benefit from aligning raw metrics with higher-level KPIs and SLOs. Presentation matters.
Track changes via our change management process. All steps are fully automated, from source code being compiled to binaries, to the upload of the binaries to the AWS infrastructure where they are available for customers to download. The signatures are automatically verified during the update process on the customer infrastructure.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. These next-generation cloud monitoring tools present reports — including metrics, performance, and incident detection — visually via dashboards.
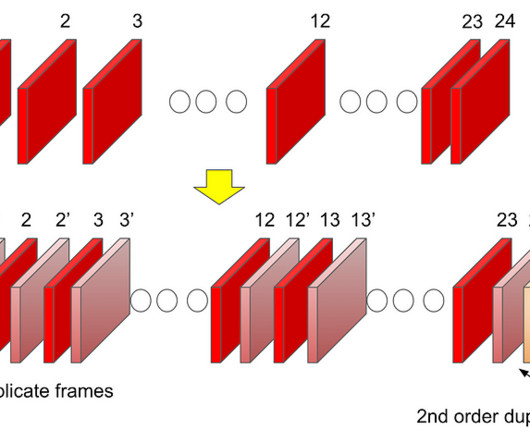
This essentially means that most of the time, our content goes through a process called frame rate conversion (aka FRC) on the source device which converts the content from its native frame rate to match the HDMI output frame rate by replicating frames. HDMI QMS is positioned to be the ideal solution to address the problem we are presenting.
Jamstack CMS: The Past, The Present and The Future. Jamstack CMS: The Past, The Present and The Future. Now there’s a massive range of Jamstack CMSs available, which bring all the advantages of static sites while allowing non-technical folk to update content. Mike Neumegen. 2021-08-20T08:00:00+00:00. 2021-08-20T09:19:47+00:00.
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data. This significantly increases event latency.
We present a systematic overview of the unexpected streaming behaviors together with a set of model-based and data-driven anomaly detection strategies to identify them. Manifest is requested by the client and gets delivered to the player before the license request, and it itemizes the available streams.
When a question gets asked, run its text through this same embedding model, determine which chunks are nearest neighbors , then present these chunks as a ranked list to the LLM to generate a response. While the overall process may be more complicated in practice, this is the gist. What is GraphRAG? Do LLMs Really Adapt to Domains?
Today, development teams suffer from a lack of automation for time-consuming tasks, the absence of standardization due to an overabundance of tool options, and insufficiently mature DevSecOps processes. This process begins when the developer merges a code change and ends when it is running in a production environment.
Keptn is currently leveraging Knative and installs Knative as well as other depending components such as Prometheus during the default keptn installation process. In my case, both prometheus.knative-monitoring pods jumped in Process CPU and I/O request bytes.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Shift-left using an SRE approach means that reliability is baked into each process, app and code change.
Remediation tracking now enables you to view the risk assessment for the process groups affected by a vulnerability. General Availability (Build 1.241.153). General Availability (Build 1.241.153). To stay tuned, keep an eye on our release notes. New features and enhancements. Application Security. Dashboards. Dynatrace API.
OneAgent processes rules precisely in this order, with host scope rules processed before host group and tenant scope rules. If a more granular rule is present on the host level, that rule will precede any blanket rule on, for example, the tenant level. Host group. Visit our trial page for a free 15-day Dynatrace trial.
However, that assumes he or she is available and has time to talk. In a distributed processing environment, message queuing is similar, although the speed and volume of messages are much greater. A producer creates the message, and a consumer processes it. A given consumer only processes each message once.
However, that assumes he or she is available and has time to talk. In a distributed processing environment, message queuing is similar, although the speed and volume of messages are much greater. A producer creates the message, and a consumer processes it. A given consumer only processes each message once.
Automation presents a solution. The following five-step approach is one that Andreas Grabner, DevOps activist at Dynatrace, and I recommend for organizations that want to incorporate SLOs within software delivery and incident management processes. Many organizations often start with the service availability and performance SLOs.
DevOps and SRE engineers experience a lot of pressure to deliver applications faster and that adhere to standards like “ the five nines ” of availability, resulting in many new service level requirements. Developers also need to automate the release process to speed up deployment and reliability.
Obviously not all tools are made with the same use case in mind, so we are planning to add more code samples for other (than classical batch ETL) data processing purposes, e.g. Machine Learning model building and scoring. This allows other processes, consuming our table, to be notified and start their processing.
Site reliability engineering (SRE) is the practice of applying software engineering principles to operations and infrastructure processes to help organizations create highly reliable and scalable software systems. Shift-left using an SRE approach means that reliability is baked into each process, app and code change.
Our previous blog post presented replay traffic testing — a crucial instrument in our toolkit that allows us to implement these transformations with precision and reliability. A process that doesn’t just minimize risk, but also facilitates a continuous evaluation of the rollout’s impact.
Secondly, knowing who is responsible is essential but not sufficient, especially if you want to automate your triage process. Keeping ownership teams and their properties up to date is essential, as is having the right contact information available when needed. Dynatrace offers several ways to ingest ownership team information.
As a Network Engineer, you need to ensure the operational functionality, availability, efficiency, backup/recovery, and security of your company’s network. Moreover, with the new metric browser , you can easily list and filter available metrics, chart metrics, and view automated multidimensional analysis. Events and alerts.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content