This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This counting service, built on top of the TimeSeries Abstraction, enables distributed counting at scale while maintaining similar low latency performance. Both categories share common requirements, such as high throughput and high availability. Today, we’re excited to present the Distributed Counter Abstraction.
In the final post of this series, we will review the last solution, Patroni by Zalando, and compare all three at the end so you can determine which high availability framework is best for your PostgreSQL hosting deployment. Managing High Availability in PostgreSQL – Part I: PostgreSQL Automatic Failover. Standby Server Tests.
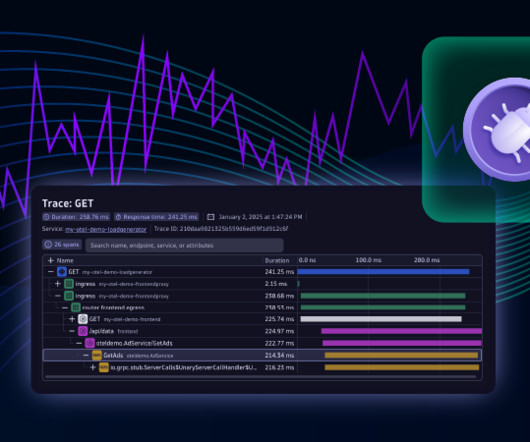
Using this data, developers can inspect local variables, server-process details, thread information, and trace data to identify the root cause of issues. Dynatrace Live Debugger will be generally available (GA) within the next 90 days. Upon GA this use case will be made available as a hands-on tutorial.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. It reduces downtime and supports business continuity.
To maintain system health and resolve issues quickly, teams must have reliable monitoring and performance insights across both Linux and Windows nodes within a single Kubernetes cluster. With Dynatrace, you can trace requests and monitor application performance end-to-end, no matter what OS the workloads run on.
MySQL does not limit the number of slaves that you can connect to the master server in a replication topology. A classic solution for this problem is to deploy a binlog server – an intermediate proxy server that sits between the master and its slaves. Ripple is an open source binlog server developed by Pavel Ivanov.
In a MySQL master-slave high availability (HA) setup, it is important to continuously monitor the health of the master and slave servers so you can detect potential issues and take corrective actions. MySQL Master Server Health Checks. Important Health Checks for your MySQL Master-Slave Servers Click To Tweet.
It also makes the process risky as production servers might be more exposed, leading to the need for real-time production data. This typically requires production server access, which, in most organizations, is difficult to arrange. Dynatrace servers never access, process, or store customer source code.
Breaking down the benefits of OpenTelemetry histograms OpenTelemetry instrumentation automatically generates histograms for HTTP client and server request durations. This feature, available by default for OTel-instrumented services, allows users a standard way to measure and compare response times across different services consistently.
HAProxy is one of the cornerstones in complex distributed systems, essential for achieving efficient load balancing and high availability. This open-source software, lauded for its reliability and high performance, is a vital tool in the arsenal of network administrators, adept at managing web traffic across diverse server environments.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. into NAM test definitions.
The end goal, of course, is to optimize the availability of organizations’ software. But moreover, business is the top priority; it never made sense to me to just monitor servers. And when outages do occur, Dynatrace AI-powered, automatic root-cause analysis can also help them to remediate issues as quickly as possible.
As organizations increasingly migrate their applications to the cloud, efficient and scalable load balancing becomes pivotal for ensuring optimal performance and high availability.
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization. Dynatrace news. Minimized cross-data center network traffic.
has been available since October. At Percona, we took the time to examine this release carefully, check performance, and guarantee it works perfectly, stand-alone, and with other tools like Percona Backup for MongoDB and Percona Monitoring and Management. MongoDB Community Edition 8.0
An access log is generated by the web server to log the details about the request that it has processed. While doing any performance analysis, these logs play an important role. Most people are aware of the application server log but many of them are not aware of the web server/load balancer access log.
Having released this functionality in an Preview Release back in September 2019, we’re now happy to announce the General Availability of our Citrix monitoring extension. This extends Dynatrace visibility into Citrix user experience and Citrix platform performance. Dynatrace Extension: SAP ABAP platform performance. SAP server.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. With Dashboards , you can monitor business performance, user interactions, security vulnerabilities, IT infrastructure health, and so much more, all in real time.
While Microsoft offers their own Azure Database product, there are other alternatives available that may be able to help you improve your MySQL performance. In this blog post, we compare Azure Database for MySQL vs. ScaleGrid MySQL on Azure so you can see which provider offers the best throughput and latency performance.
Benefits of Caching Improved performance: Caching eliminates the need to retrieve data from the original source every time, resulting in faster response times and reduced latency. Reduced server load: By serving cached content, the load on the server is reduced, allowing it to handle more requests and improving overall scalability.
address these limitations and brings new monitoring and analytical capabilities that weren’t available to Extensions 1.0: address these limitations and brings new monitoring and analytical capabilities that weren’t available to Extensions 1.0: available, and more are in the pipeline. Extensions 2.0 Extensions 2.0
Live Debugger enables developers to access real-time insights from runtime environments without requiring issue reproduction or redeployments, extract debugging information without performance impact, and leverage contextual insights for rapid problem resolution.
You can use it to visualize CPU utilization across your hosts, disk space used, server-side response time, web request/service failure rates, or any other area where you need to spot outliers immediately. To achieve the best visual outcome, we recommend experimenting with the available customization options. Try different cell shapes.
Database Availability Group (DAG) is a built-in framework in Microsoft Exchange Server that uses continuous replication and failover clustering to ensure high availability and site resilience. In DAG, there is one active server and a copy of the database on the active server is replicated across all passive servers.
In this blog, I will be going through a step-by-step guide on how to automate SRE-driven performance engineering. Step-by-step guide: SRE-driven performance analysis with Dynatrace. If you use your own application and it was already running before you installed the OneAgent, please restart your application and web servers.
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. Greenplum uses an MPP database design that can help you develop a scalable, high performance deployment.
In this post, well walk through some of the best MySQL GUI tools available in 2025covering both free and commercial optionsso you can find the one that fits your workflow. Built and maintained by Oracle, it provides an all-in-one solution for database modeling, query execution, user administration, and performance monitoring.
Secondly, determining the correct allocation of resources (CPU, memory, storage) to each virtual machine to ensure optimal performance without over-provisioning can be difficult. This presents a challenge for IT operations teams, specifically in identifying and addressing performance issues or planning how to prevent future issues.
Application servers use connection pools to maintain connections with the databases that they communicate with. Connection pools are also a great way to improve performance. New extensions enable AI-powered monitoring of connection pool performance. Automatically identify connection leaks in your application code.
These events are promptly relayed from the client side to our servers, entering a centralized event processing queue. This dual availability ensures immediate processing capabilities alongside comprehensive long-term data retention. This queue ensures we are consistently capturing raw events from our global userbase.
Amazon’s new general-purpose Linux for AWS is designed to provide a secure, stable, and high-performance execution environment to develop and run cloud applications. This is done by detecting availability and performance problems in real time across an entire technology stack while presenting teams with answers — not alert storms.
Facilitating remote access to other computers or servers with easier navigation. Advanced Features: Does the tool support stored procedures, triggers, indexing, and performance analysis? Learning Resources: Are there tutorials, guides, and comprehensive documentation available for the tool? Easy to use and highly customizable.
This results in performance issues or even downtime that could easily be prevented. For self-managed OCP operators, it’s particularly important to understand the health and performance of the platform’s control plane. Issues with the control plane could leave the platform in an unpredictable and uncontrollable state.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. APM provides real-time visibility into the status and performance of applications. Cloud-server monitoring. Website monitoring.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it.
IBM Power servers enable customers to respond faster to business demands, protect data from core to cloud, and streamline insights and automation. Intelligent root cause analysis: Use Davis® AI to automatically detect and analyze performance issues across the entire tech stack.
This blog post will share broadly-applicable techniques (beyond GraphQL) we used to perform this migration. Before GraphQL: Monolithic Falcor API implemented and maintained by the API Team Before moving to GraphQL, our API layer consisted of a monolithic server built with Falcor. To launch Phase 1 safely, we used AB Testing.
This article outlines the key differences in architecture, performance, and use cases to help determine the best fit for your workload. Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing.
Nowadays, many people migrate their applications from traditional, single-server relational databases to distributed database clusters. This helps improve availability, scalability, and performance.
The first phase involves validating functional correctness, scalability, and performance concerns and ensuring the new systems’ resilience before the migration. These include Quality-of-Experience(QoE) measurements at the customer device level, Service-Level-Agreements (SLAs), and business-level Key-Performance-Indicators(KPIs).
Too many concurrent server requests can lead to website crashes if youre not equipped to deal with them. The good news is that you can maximize availability and prevent website crashes by designing websites specifically for these events. You can free up space and reduce the load on your server by compressing and optimizing images.
If you must kill the script at this point, there are two options available: SCRIPT KILL command can be used to stop a script that hasn’t yet done any writes. If the script has already performed writes to the server and must still be killed, use the SHUTDOWN NOSAVE to shutdown the server completely. Expert Tip.
As an engineer, you probably know that serverperformance under heavy load is crucial for maintaining the availability and responsiveness of your services. In this post, we'll explore both strategies through a simple simulation in Colab, allowing you to see the impact of changing parameters on system performance.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content