This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
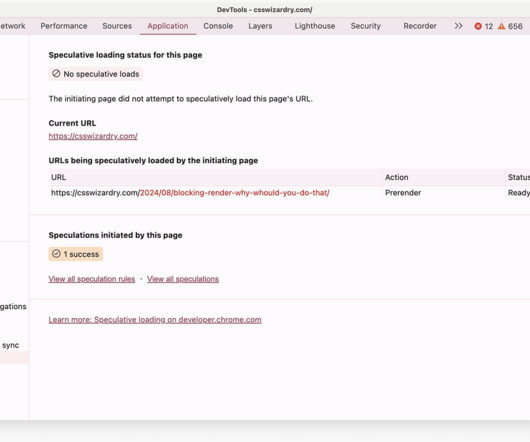
In this post I want to look at how CSS can prove to be a substantial bottleneck on the network (both in itself and for other resources) and how we can mitigate it, thus shortening the Critical Path and reducing our time to Start Render. Employ Critical CSS. This is on purpose. Test, test, test. It’s also very component friendly.
In response, many organizations are adopting a FinOps strategy. Flexible pricing models that offer discounts based on commitment or availability can greatly reduce cloud waste. This includes spot instances such as unused cloud capacity that’s available at a discounted price. Suboptimal architecture design.
For cloud operations teams, network performance monitoring is central in ensuring application and infrastructure performance. If the network is sluggish, an application may also be slow, frustrating users. Worse, a malicious attacker may gain access to the network, compromising sensitive application data.
From mobile applications to websites, government services must be accessible, available, and performant for those who rely on them. Citizens need seamless digital experiences, which is why the concept of a total experience (TX) strategy is gaining traction among government institutions. Everything impacts and influences each other.
For IT teams seeking agility, cost savings, and a faster on-ramp to innovation, a cloud migration strategy is critical. Define the strategy, assess the environment, and perform migration-readiness assessments and workshops. The seven Rs of a cloud migration strategy with Dynatrace. Dynatrace news. Mobilize and plan.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. Automatic failover is a critical strategy to achieve this.
Activate Davis AI to analyze charts within seconds Davis AI can help you expand your dashboards and dive deeper into your available data to extract additional information. For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline.
Youll also learn strategies for maintaining data safety and managing node failures so your RabbitMQ setup is always up to the task. Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. Website monitoring.
Compressing them over the network: Which compression algorithm, if any, will we use? What is the availability, configurability, and efficacy of each? ?️ Given that 66% of all websites (and 77% of all requests ) are running HTTP/2, I will not discuss concatenation strategies for HTTP/1.1 in this article.
Dynatrace provides up-to-date network maps, identifies critical services, and highlights gaps in coverage. Any incident can negatively impact service availability, and even a swift reaction might not prevent financial, reputational, or societal damage from happening.
Mastering Hybrid Cloud Strategy Are you looking to leverage the best private and public cloud worlds to propel your business forward? A hybrid cloud strategy could be your answer. Understanding Hybrid Cloud Strategy A hybrid cloud merges the capabilities of public and private clouds into a singular, coherent system.
To achieve optimal tracking results it is important to choose wisely among available tools like Prometheus or Grafana, which offer deeper insights into understanding your Redis instances for better performance optimization. Or even having limitations when trying vertical/horizontal scalability while ensuring availability at all times.
There are a wealth of options on how you can approach storage configuration in Percona Operator for PostgreSQL , and in this blog post, we review various storage strategies — from basics to more sophisticated use cases. This is done without downtime, but replication might introduce additional load on the primary node and the network.
They collect data from multiple sources through real user monitoring , synthetic monitoring, network monitoring, and application performance monitoring systems. How to improve digital experience monitoring Implementing a successful DEM strategy can come with challenges.
Infrastructure monitoring is the process of collecting critical data about your IT environment, including information about availability, performance and resource efficiency. Effective monitoring and diagnostics starts with availability monitoring. Dynatrace news. This stage is defined by the question “is it up?
This operational data could be gathered from live running infrastructures using software agents, hypervisors, or network logs, for example. Additionally, ITOA gathers and processes information from applications, services, networks, operating systems, and cloud infrastructure hardware logs in real time.
Replication Strategy. Our Dedicated Hosting plans are all-inclusive, including all machine, disk, and network costs, as well as 24/7 support. Is my database cluster still highly available? All of our high availability options are offered in DigitalOcean, including 2 Replicas + 1 Arbiter, 3 Replicas and custom replica set setups.
Besides the traditional system hardware, storage, routers, and software, ITOps also includes virtual components of the network and cloud infrastructure. A network administrator sets up a network, manages virtual private networks (VPNs), creates and authorizes user profiles, allows secure access, and identifies and solves network issues.
A well-planned multi cloud strategy can seriously upgrade your business’s tech game, making you more agile. Key Takeaways Multi-cloud strategies have become increasingly popular due to the need for flexibility, innovation, and the avoidance of vendor lock-in. Thinking about going multi-cloud?
The three strategies we will discuss today are AB Testing , Replay Testing, and Sticky Canaries. Let’s discuss the three testing strategies in further detail. The Replay Testing framework leverages the @override directive available in GraphQL Federation. To launch Phase 2 safely, we used Replay Testing and Sticky Canaries.
And because Dynatrace can consume CloudWatch metrics, almost all your AWS usage information is available to you within Dynatrace. Similarly, integrations for Azure and VMware are available to help you monitor your infrastructure both in the cloud and on-premises.
Confused about multi-cloud vs hybrid cloud and which is the right strategy for your organization? Real-world examples like Spotify’s multi-cloud strategy for cost reduction and performance, and Netflix’s hybrid cloud setup for efficient content streaming and creation, illustrate the practical applications of each model.
To achieve optimal tracking results it is important to choose wisely among available tools like Prometheus or Grafana, which offer deeper insights into understanding your Redis® instances for better performance optimization. Or even having limitations when trying vertical/horizontal scalability while ensuring availability at all times.
Let’s delve deeper into how these capabilities can transform your observability strategy, starting with our new syslog support. Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operating systems, security devices, network devices, and applications such as web servers and databases.
Let’s consider the business challenges of an online shop that is powered by a microservice architecture where several instances of each microservice run, including the shopping cart service, to ensure the highest possible availability. OneAgent implements network zones to create traffic routing rules and limit cross data-center traffic.
To make data count and to ensure cloud computing is unabated, companies and organizations must have highly available databases. This guide provides an overview of what high availability means, the components involved, how to measure high availability, and how to achieve it. How does high availability work?
This release extends auto-adaptive baselines to the following generic metric sources, all in the context of Dynatrace Smartscape topology: Built-in OneAgent infrastructure monitoring metrics (host, process, network, etc.). Availability. Built-in OneAgent service metrics (request duration, errors, resource consumption, etc.).
Enhanced customer confidence through excellent service availability. The good news: even for latecomers to the compliance party, compliance is perfectly doable within the timeframe given the right tools and strategies. Organisations typically waste valuable time discussing and deciding the right strategy for hunting down the problem.
IT infrastructure is the heart of your digital business and connects every area – physical and virtual servers, storage, databases, networks, cloud services. Simply put, infrastructure monitoring is the oxygen to your infrastructure, collecting all the data for a complete picture of availability, performance, and resource efficiency.
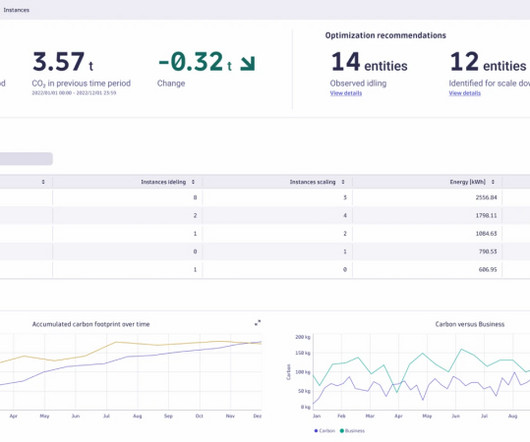
These metrics include CPU, memory, disk, and network I/O. As a result, this baseline measurement has become an important component of our sustainability strategy. Because it facilitates ongoing monitoring and tracks progress toward our sustainability goals, we can adjust our strategy to reduce our IT carbon footprint.
Because Google offers its own Google Cloud Architecture Framework and Microsoft its Azure Well-Architected Framework , organizations that use a combination of these platforms triple the challenge of integrating their performance frameworks into a cohesive strategy. This workflow uses the Dynatrace Site Reliability Guardian application.
Application availability measures the time an application is available and fully functional for end users. Organizational buy-in of DevOps automation reflects support for structural solutions that build community and strategies that scale. Automated network provisioning. Benefits of automation in DevOps. Cultural shift.
Group replication is a fault-tolerant/highly available replication topology that ensures if the primary node goes down, one of the other candidates or secondary members takes over so write and read operations can continue without any interruptions.
Cloud migration is the process of transferring some or all your data, software, and operations to a cloud-based computing environment that offers unlimited scale and high availability. A cloud migration strategy, however, provides technical optimization that’s also firmly rooted in the business value chain. Read eBook now!
Automatically connect distributed traces with logs for improved application availability, performance, and agility. Investigate network systems and application security incidents quickly for near-real-time remediation. One way to accomplish this is by implementing AIOps as part of an organization’s larger cloud adoption strategy.
According to one recent survey, more than 60% of respondents were adopting AIOps to improve service and application availability and performance. Each team had its favorite tool—whether for networking, development, or database management—and Odigo needed to centralize. “We Odigo instituted a schedule for decommissioning tools.
They can also develop proactive security measures capable of stopping threats before they breach network defenses. For example, an organization might use security analytics tools to monitor user behavior and network traffic. But, observability doesn’t stop at simply discovering data across your network.
Historically, NoSQL paid a lot of attention to tradeoffs between consistency, fault-tolerance and performance to serve geographically distributed systems, low-latency or highly available applications. However, consistency is a very expensive thing in distributed systems, so it can be traded not only to availability. Data Placement.
These metrics help to keep a network system up and running?, If one system has an MTTR of 24 hours and another has an MTTR of three days with equal time between failures, the first system is more valuable because its availability is higher. MTTF measures the reliability of a network and durability of its hardware.
Upgrades and modifications, if available, are complex and expensive, so it isn’t easy to keep them secure and functional. HHS tends to have large numbers of systems, networks, and devices, which collectively increase complexity and the potential for failure, as does unsupported legacy tech.
The possible navigation types are: Navigate: A hard navigation that resulted in an HTML page being fetched from the network. Navigate 70% of page views are Navigations , which means a user landed on them via a hard navigation and the file was fetched from the network. Cache: An HTML response returned from the HTTP cache.
Observability becomes mandatory for any serious sustainability strategy in IT. By predicting and resolving issues before they impact operations, organizations can ensure service availability, minimize downtime, and reduce operational overhead. This proactive, context-aware approach will soon become the industry standard.
In this post, we compare ScaleGrid’s Bring Your Own Cloud (BYOC) plan vs. the standard Dedicated Hosting model to help you determine the best strategy for your MySQL, PostgreSQL, Redis™ and MongoDB® database deployment. Both AWS EC2 instances and Azure VM instances are available as Reserved Instances, and can be used through the BYOC plan.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content