This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Expectations for network monitoring In today’s digital landscape, businesses rely heavily on their IT infrastructure to deliver seamless services to customers. However, network issues can lead to significant downtime, affecting user experience and business operations.
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Are all network devices up and running, and is the network providing reliable and swift access to your systems?
By Alok Tiagi , Hariharan Ananthakrishnan , Ivan Porto Carrero and Keerti Lakshminarayan Netflix has developed a network observability sidecar called Flow Exporter that uses eBPF tracepoints to capture TCP flows at near real time. Without having network visibility, it’s difficult to improve our reliability, security and capacity posture.
Managing SNMP devices at scale can be challenging SNMP (Simple Network Management Protocol) provides a standardized framework for monitoring and managing devices on IP networks. Its simplicity, scalability, and compatibility with a wide range of hardware make it an ideal choice for network management across diverse environments.
In September, we announced the availability of the Dynatrace Software Intelligence Platform on Microsoft Azure as a SaaS solution and natively in the Azure portal. Today, we are excited to provide an update that Dynatrace SaaS on Azure is now generally available (GA) to the public through Dynatrace sales channels. Dynatrace news.
Every browser available on iOS is simply a wrapper around Safari. Network Link Conditioner. In there, you should find a tool called Network Link Conditioner. This provides us with very accurate network throttling via a number of handy presets, or you can configure your own. Why This Is a Problem. Chrome for iOS?
In the final post of this series, we will review the last solution, Patroni by Zalando, and compare all three at the end so you can determine which high availability framework is best for your PostgreSQL hosting deployment. Managing High Availability in PostgreSQL – Part I: PostgreSQL Automatic Failover. Network Isolation Tests.
Traditional network-based security approaches are evolving. Enhanced security measures, such as encryption and zero-trust, are making it increasingly difficult to analyze security threats using network packets. While network security remains relevant, the emphasis is now on application observability and threat detection.
Kickstart your creation journey using ready-made dashboards and notebooks Creating dashboards and notebooks from scratch can take time, particularly when figuring out available data and how to best use it. An example of this is shown in the video above, where we incorporated network-related metrics into the Kubernetes cluster dashboard.
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. The network latency between cluster nodes should be around 10 ms or less. Minimized cross-data center network traffic. Dynatrace news.
To extend Dynatrace diagnostic visibility into network traffic, we’ve added out-of-the-box DNS request tracking to our infrastructure monitoring capabilities. Ensure high quality network traffic by tracking DNS requests out-of-the-box. Slower response times can be a sign of a stressed DNS server or network communication issues.
By minimizing bandwidth and preventing unrelated traffic between data centers, you can maintain healthy network infrastructure and save on costs. Dynatrace network zones provide an easy means of routing OneAgent traffic between data centers using a unique approach that separates Dynatrace from its competitors. How to get started.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. Effective management of failover and switchover operations is crucial for high availability.
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? Downtime per year. 90% (one nine).
Quick and easy network infrastructure monitoring. All of this convenient visibility is available with just a few clicks. Begin network monitoring by simply deploying an extension with just a few clicks. Tired of constantly switching between all your monitoring tools? Start monitoring in minutes.
For cloud operations teams, network performance monitoring is central in ensuring application and infrastructure performance. If the network is sluggish, an application may also be slow, frustrating users. Worse, a malicious attacker may gain access to the network, compromising sensitive application data.
Oftentimes, our customers demand CockroachDB be available in regions where we see low demand, and bringing those regions online is not cost-effective to the organization. As of this writing, we support the most popular regions in GCP and AWS; some regions are not exposed in the cloud console but are available via support ticket.
Monitoring modern IT infrastructure is difficult, sometimes impossible, without advanced network monitoring tools. While the market is saturated with many Network Administrator support solutions, Dynatrace can help you analyze the impact on your organization in an automated manner. How SNMP traps help detect problems. What’s next?
We’re happy to announce the General Availability of cross-environment dashboarding capabilities (having released this functionality in an Early Adopter release with Dynatrace version 1.172 back in June 2019). Keep the token secret available for the second and final configuration step. Dynatrace news.
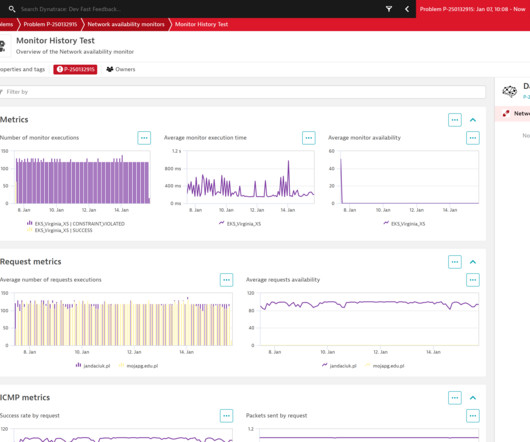
Thanks to the power of Grail, those details are available for all executions stored for the entire retention period during which synthetic results are kept. It now fully supports not only NetworkAvailability Monitors but also HTTP synthetic monitors. Details of requests sent during each monitor execution are also available.
The certification results are now publicly available. The calculations and methodology used are in line with the best available scientific approach, as well as with relevant reporting requirements. Network traffic power calculations rely on static power estimations for both public and private networks.
The problems with degraded service availability along with revenue impact occur mainly because of Kubernetes pod crashes along with resource exhaustion and network disruptions that hit during peak shopping seasons.
This allows them to innovate more quickly while ensuring maximum service availability — both of which are key for essential government agencies. This blog originally appeared in Federal News Network. The post How AI and observability help to safeguard government networks from new threats appeared first on Dynatrace news.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. Host Monitoring dashboards offer real-time visibility into the health and performance of servers and network infrastructure, enabling proactive issue detection and resolution.
As file sizes grow and workflows become more complex, these issues are magnified, leading to inefficiencies that slow down post-production and reduce the available time spent on creativework. Depending on the market, or production budget, cutting-edge technology might not be available or affordable. So what isit?
Activate Davis AI to analyze charts within seconds Davis AI can help you expand your dashboards and dive deeper into your available data to extract additional information. For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline.
Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services. Classic queues can be used in clusters, emphasizing their behavior during node failures, particularly regarding durability and availability.
While the Explore interface is useful for quickly visualizing known metrics, Davis CoPilot is great for exploring your data when you know your desired outcome but are unfamiliar with the available data. exploring your data when you know your desired outcome but are unfamiliar with the available data. Expand the Single value section.
With more organizations taking the multicloud plunge, monitoring cloud infrastructure is critical to ensure all components of the cloud computing stack are available, high-performing, and secure. Website monitoring examines a cloud-hosted website’s processes, traffic, availability, and resource use. Website monitoring.
How can you ensure that the measurements are always available and healthy? In order to detect all kinds of availability issues, you need AI-powered alerting for your third-party data sources, too. But how can you ensure that these data sources are always up and running?
A significant feature of Chronicle Queue Enterprise is support for TCP replication across multiple servers to ensure the high availability of application infrastructure. This is the first time I have benchmarked it with a realistic example.
And there are a lot of monitoring tools available providing all kinds of features and concepts. For example, you can monitor the behavior of your applications, the hardware usage of your server nodes, or even the network traffic between servers. For that reason, we use monitoring tools.
These include traditional on-premises network devices and servers for infrastructure applications like databases, websites, or email. A local endpoint in a protected network or DMZ is required to capture these messages. The key to success is making data in this complex ecosystem actionable, as many types of syslog producers exist.
HAProxy is one of the cornerstones in complex distributed systems, essential for achieving efficient load balancing and high availability. This open-source software, lauded for its reliability and high performance, is a vital tool in the arsenal of network administrators, adept at managing web traffic across diverse server environments.
The high likelihood of unreliable network connectivity led us to lean into mobile solutions for robust client side persistence and offline support. This translates to a large number of app configurations to toggle feature availability and optimize the in-app experience for each production. Networking Hendrix interprets rule set(s)?—?remotely
Analyze network flow logs Last but not least, your network logs are the ultimate source of data. Using the VPC flow log default pattern available in DPL Architect, we can extract the meaningful fields to see only the network traffic targeting the SSH port.
Errors could occur in any part of the system / or its ecosystem and there are different ways of handling these e.g. Datacenter - data center failure where the whole DC could become unavailable due to power failure, network connectivity failure, environmental catastrophe, etc. this is addressed through monitoring and redundancy.
Greenplum interconnect is the networking layer of the architecture, and manages communication between the Greenplum segments and master host network infrastructure. Here are the two different database management and support options available for Greenplum: ScaleGrid for Greenplum® Database – Open Source Version.
Dynatrace’s ability to ingest metrics from all 95 AWS services will be available within the next 60 days. The latest batch of services cover databases, networks, machine learning and computing. Those in the left column are readily available now, with those in the right available soon. Available Now. Coming Soon.
As a Network Engineer, you need to ensure the operational functionality, availability, efficiency, backup/recovery, and security of your company’s network. Moreover, with the new metric browser , you can easily list and filter available metrics, chart metrics, and view automated multidimensional analysis. A sneak peak.
Access to source code repositories is limited on both the network and the user level. Source code management systems are only accessible from within the Dynatrace corporate network. Remote access to the Dynatrace corporate network requires multi-factor authentication (MFA). No manual, error-prone steps are involved.
Firstly, managing virtual networks can be complex as networking in a virtual environment differs significantly from traditional networking. Therefore, we have redesigned this extension from scratch, replacing the previously available WMI-based extension. This leads to a more efficient and streamlined experience for users.
Available directly from the AWS Marketplace , Dynatrace provides full-stack observability and AI to help IT teams optimize the resiliency of their cloud applications from the user experience down to the underlying operating system, infrastructure, and services. How does Dynatrace help?
Native support for Syslog messages Syslog messages are generated by default in Linux and Unix operating systems, security devices, network devices, and applications such as web servers and databases. Native support for syslog messages extends our infrastructure log support to all Linux/Unix systems and network devices.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content