This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.
Activate Davis AI to analyze charts within seconds Davis AI can help you expand your dashboards and dive deeper into your available data to extract additional information. For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline.
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
The Dynatrace Software Intelligence Platform gives you a complete Infrastructure Monitoring solution for the monitoring of cloud platforms and virtual infrastructure, along with log monitoring and AIOps. Ensure high quality network traffic by tracking DNS requests out-of-the-box. What’s next.
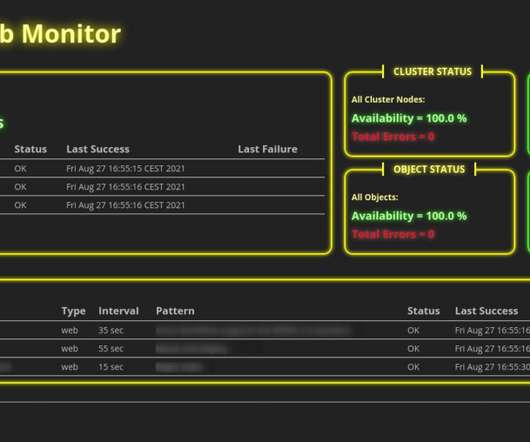
If you run several web servers in your organization or even public web servers on the internet, you need some kind of monitoring. For that reason, we use monitoring tools. And there are a lot of monitoring tools available providing all kinds of features and concepts.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
Real-time monitoring : The periodic reports from cloud service providers lack real-time monitoring and actionable insights, limiting IT teams’ ability to make immediate adjustments to reduce carbon footprints. The certification results are now publicly available. Static assumptions are: Local network traffic uses 0.12
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization. Minimized cross-data center network traffic.
Accurately Reflecting Production Behavior A key part of our solution is insights into production behavior, which necessitates our requests to the endpoint result in traffic to the real service functions that mimics the same pathways the traffic would take if it came from the usualcallers. there is a dedicated collector.
For retail organizations, peak traffic can be a mixed blessing. While high-volume traffic often boosts sales, it can also compromise uptimes. The nirvana state of system uptime at peak loads is known as “five-nines availability.” But is five nines availability attainable? Downtime per year. 90% (one nine).
In fact, according to a Dynatrace global survey of 1,300 CIOs , 99% of enterprises utilize a multicloud environment and seven cloud monitoring solutions on average. What is cloud monitoring? Cloud monitoring is a set of solutions and practices used to observe, measure, analyze, and manage the health of cloud-based IT infrastructure.
In the final post of this series, we will review the last solution, Patroni by Zalando, and compare all three at the end so you can determine which high availability framework is best for your PostgreSQL hosting deployment. Managing High Availability in PostgreSQL – Part I: PostgreSQL Automatic Failover. Patroni for PostgreSQL.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services.
Managing High Availability (HA) in your PostgreSQL hosting is very important to ensuring your database deployment clusters maintain exceptional uptime and strong operational performance so your data is always available to your application. Effective management of failover and switchover operations is crucial for high availability.
As businesses compete for customer loyalty, it’s critical to understand the difference between real-user monitoring and synthetic user monitoring. However, not all user monitoring systems are created equal. What is real user monitoring? Real-time monitoring of user application and service interactions.
Over the last two month s, w e’ve monito red key sites and applications across industries that have been receiving surges in traffic , including government, health insurance, retail, banking, and media. Monitoring with ?the The following day, a normally mundane Wednesday , traffic soared to 128,000 sessions.
With today’s high expectations for the speed and availability of applications, you need a deep understanding of real user experiences to make the best business decisions. Dynatrace Synthetic Monitoring ensures that your application is available and performs well from anywhere in the world to meet your SLAs. Dynatrace news.
For cloud operations teams, network performance monitoring is central in ensuring application and infrastructure performance. Network traffic growth is the main reason for increasing spending, largely because of the adoption of hybrid and multi-cloud architectures.
Over the years we’ve learned from on-call engineers about the pain points of application monitoring: too many alerts, too many dashboards to scroll through, and too much configuration and maintenance. Our streaming teams need a monitoring system that enables them to quickly diagnose and remediate problems; seconds count!
Having released this functionality in an Early Adopter Release with OneAgent version 1.173 and Dynatrace version 1.174 back in August 2019, we’re now happy to announce the General Availability of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux. What’s included.
Dynatrace OneAgent is great for monitoring the full stack. While this will give you a lot of information about the health of these components, sometimes a simple synthetic monitor is sufficient. Heading up the Platform Extension Services team at Dynatrace, we’re the go-to team for anything that isn’t available out of the box.
With the world’s increased reliance on digital services and the organizational pressure on IT teams to innovate faster, the need for DevOps monitoring tools has grown exponentially. But when and how does DevOps monitoring fit into the process? And how do DevOps monitoring tools help teams achieve DevOps efficiency?
Digital experience monitoring (DEM) allows an organization to optimize customer experiences by taking into account the context surrounding digital experience metrics. What is digital experience monitoring? Primary digital experience monitoring tools.
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
We’re proud to announce the general availability of OneAgent full-stack monitoring for the AIX operating system. We’ve already reached a percentage of monitored AIX hosts running OneAgent that is equivalent to AIX market share. The ones that are available are old generation. Installation.
Organizations can now accelerate innovation and reduce the risk of failed software releases by incorporating on-demand synthetic monitoring as a metrics provider for automatic, continuous release-validation processes. Dynatrace combines Synthetic Monitoring with automatic release validation for continuous quality assurance across the SDLC.
The F5 BIG-IP Local Traffic Manager (LTM) is an application delivery controller (ADC) that ensures the availability, security, and optimal performance of network traffic flows. Why monitor F5 BIG-IP load balancers? Business-critical applications typically rely on F5 for availability and success.
RabbitMQ can be deployed in distributed environments and includes monitoring tools through a built-in dashboard and CLI. Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing.
The control group’s traffic utilized the legacy Falcor stack, while the experiment population leveraged the new GraphQL client and was directed to the GraphQL Shim. This helped us successfully migrate 100% of the traffic on the mobile homepage canvas to GraphQL in 6 months. How does it work?
Percona Monitoring and Management (PMM) is a state-of-the-art piece of software that exists in part thanks to great open source projects like VictoriaMetrics, PostgreSQL, and ClickHouse. Being software composed of different, multiple technologies can add complexity to a well-known concept: High Availability (HA).
This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. Containers can be replicated or deleted on the fly to meet varying end-user traffic. Built-in monitoring. Needs third party tools for monitoring. Needs third party tools for monitoring.
Read Also: Best PostgreSQL GUI Incremental Backups PostgreSQL 17 introduces incremental backups , a game-changer for large and high-traffic databases. Get automated backups, high availability, and seamless scalingso you can focus on your applications, not database maintenance. Start your free trial today!
We’re happy to announce the Early Adopter Release of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux (available with OneAgent version 1.173 and Dynatrace version 1.174). Mainframe monitoring is an area of significant investment for Dynatrace. Dynatrace news.
Our enhanced host monitoring dashboard that highlights disk usage includes AI forecasting for CPU usage. While the Explore interface is useful for quickly visualizing known metrics, Davis CoPilot is great for exploring your data when you know your desired outcome but are unfamiliar with the available data. Looking for something?
Highlighting NewReleases For new content, impression history helps us monitor initial user interactions and adjust our merchandising efforts accordingly. This dual availability ensures immediate processing capabilities alongside comprehensive long-term data retention.
The subject line said: “Success Story: Major Issue in single AWS Frankfurt Availability Zone!” The email walked through how our Dynatrace self-monitoring notified users of the outage but automatically remediated the problem thanks to our platform’s architecture. Ready to learn more? Fact #2: No significant impact on Dynatrace Users.
Complex syslog ecosystems can be challenging Monitoring devices and applications that provide output via the syslog protocol is a must-have for many organizations. One change to send syslog to Dynatrace You can now use the syslog ingestion endpoint on Dynatrace Environment ActiveGate for performant network and system monitoring.
In a world where 99.999% availability is the standard, measuring MTTR is a crucial practice to ensure resiliency and stability. Anything that takes more than a day could indicate poor alerting or poor monitoring and can result in a larger number of affected systems. App availability. Application usage and traffic.
Monitor your cloud OpenPipeline ™ is the Dynatrace platform data-handling solution designed to seamlessly ingest and process data from any source, regardless of scale or format. Kubernetes log monitoring with Fluent Bit In an effort to further democratize data, Dynatrace provides a curated and supported OpenTelemetry collector.
In my last blog , I’ve provided an example of this happening, whereby the traffic spiked and quadrupled the usual incoming traffic. These are all interesting metrics from marketing point of view, and also highly interesting to you as they allow you to engage with the teams that are driving the traffic against your IT-system.
Even when the staging environment closely mirrors the production environment, achieving a complete replication of all potential scenarios, such as simulating extremely high traffic volumes to assess software performance, remains challenging. This can lead to a lack of insight into how the code will behave when exposed to heavy traffic.
These organizations rely heavily on performance, availability, and user satisfaction to drive sales and retain customers. AvailabilityAvailability SLO quantifies the expected level of service availability over a specific time period. Availability is typically expressed in 9’s, such as 99.9%. or 99.99% of the time.
Because of Dynatrace’s Real User Monitoring (RUM) capability, and insights from our AI engine, Davis, they were able to quickly prioritize and fix the issues to ensure their employees had an optimal remote work experience. Facilitating an understanding of traffic patterns and potential traffic spikes helps maintain customer experience.
Let’s consider the business challenges of an online shop that is powered by a microservice architecture where several instances of each microservice run, including the shopping cart service, to ensure the highest possible availability. With Dynatrace OneAgent you also benefit from support for traffic routing and traffic control.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content