This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A Dynatrace API token with the following permissions: Ingest OpenTelemetry traces ( openTelemetryTrace.ingest ) Ingest metrics ( metrics.ingest ) Ingest logs ( logs.ingest ) To set up the token, see Dynatrace API – Tokens and authentication in Dynatrace documentation. So, stay tuned for more enhancements and features.
Whether you’re a seasoned IT expert or a marketing professional looking to improve business performance, understanding the data available to you is essential. Even if infrastructure metrics aren’t your thing, you’re welcome to join us on this creative journey simply swap out the suggested metrics for ones that interest you.
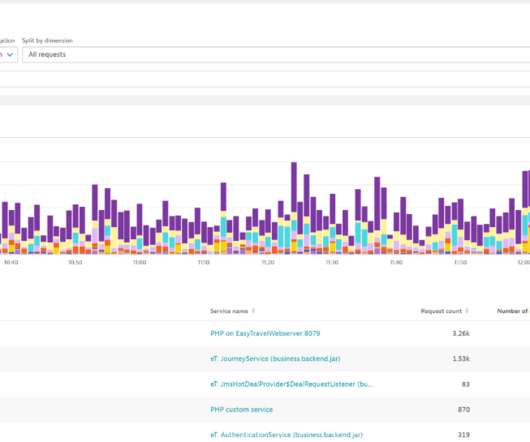
Dynatrace collects a huge number of metrics for each OneAgent-monitored host in your environment. Depending on the types of technologies you’re running on individual hosts, the average number of metrics is about 500 per computational node. Running metric queries on a subset of entities for live monitoring and system overviews.
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. This approach is costly and error prone.
Welcome back to the blog series where we provide you with deep dives into the latest observability awesomeness from Dynatrace , demonstrating how we bring scale, zero configuration, automatic AI driven alerting, and root cause analysis to all your custom metrics, including open source observability frameworks like StatsD, Telegraf, and Prometheus.
The emerging concepts of working with DevOps metrics and DevOps KPIs have really come a long way. DevOps metrics to help you meet your DevOps goals. Like any IT or business project, you’ll need to track critical key metrics. Here are nine key DevOps metrics and DevOps KPIs that will help you be successful.
This dual-path approach leverages Kafkas capability for low-latency streaming and Icebergs efficient management of large-scale, immutable datasets, ensuring both real-time responsiveness and comprehensive historical data availability. These alerts promptly notify us of any potential issues, enabling us to swiftly address regressions.
With the advent and ingestion of thousands of custom metrics into Dynatrace, we’ve once again pushed the boundaries of automatic, AI-based root cause analysis with the introduction of auto-adaptive baselines as a foundational concept for Dynatrace topology-driven timeseries measurements. In many cases, metric behavior changes over time.
Having released this functionality in an Early Adopter Release with OneAgent version 1.173 and Dynatrace version 1.174 back in August 2019, we’re now happy to announce the General Availability of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux. Release details.
In an existing application landscape, however, it can be difficult to get to those metrics. Dynatrace customers have the ability to leverage PurePath distributed tracing functionality in driving adhoc multidimensional analysis (MDA) on any kind of data available within their microservices. Here’s how Dynatrace customers do it.
OpenTelemetry metrics are useful for augmenting the fully automatic observability that can be achieved with Dynatrace OneAgent. OpenTelemetry metrics add domain specific data such as business KPIs and license relevant consumption details. Enterprise-grade observability for custom OpenTelemetry metrics from AWS. Dynatrace news.
This challenge has given rise to the discipline of observability engineering, which concentrates on the details of telemetry data to fine-tune observability use cases. To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus.
Dynatrace Synthetic Monitoring allows you to proactively monitor the availability of your public as well as your internal web applications and API endpoints from locations around the globe or important internal locations such as branch offices. Ensure better user experience with paint-focused performance metrics. Dynatrace news.
The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data. The configuration also includes an optional span metrics connector, which generates Request, Error, and Duration (R.E.D.) metrics from span data.
As the application owner of an e-commerce application, for example, you can enrich the source code of your application with domain-specific knowledge by adding actionable semantics to collected performance or business metrics. New OpenTelemetry metrics exporters provide the broadest language support on the market.
To provide you with more value when monitoring hosts in infrastructure mode, we’re extending our infrastructure mode with a range of metrics that have until now only been available in full-stack mode. Until now JMX and PMI extensions were only available in full-stack monitoring mode. Monitor additional metrics.
Welcome back to the second part of our blog series on how easy it is to get enterprise-grade observability at scale in Dynatrace for your OpenTelemetry custom metrics. In Part 1 , we announced our new OpenTelemetry custom-metric exporters that provide the broadest language coverage on the market, including Go , .NET record(value); }.
After being available in an Early Adopter Release, we’re happy to announce that AWS supporting services are now Generally Available (GA). Supporting services include every service that isn’t available with out-of-the-box Dynatrace monitoring. Get up to 300 new AWS metrics out of the box. Everything is customizable.
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. The batch job creates a high-level summary that captures some key comparison metrics.
We’re happy to announce the Early Adopter Release of OneAgent full-stack monitoring for Linux on the IBM Z platform, sometimes informally referred to as Z/Linux (available with OneAgent version 1.173 and Dynatrace version 1.174). For details on availablemetrics, see our help page on host performance monitoring.
In my last post , I started to outline the process I go through when tuning queries – specifically when I discover that I need to add a new index, or modify an existing one. This is where index tuning becomes an art. Then I roll through and force each index with a hint, capturing the plan and performance metrics for each execution.
Implementing clustering and quorum queues in RabbitMQ significantly improves load distribution and data redundancy, ensuring high availability and fault tolerance for messaging services. Classic queues can be used in clusters, emphasizing their behavior during node failures, particularly regarding durability and availability.
Its design prioritizes high availability and efficient data transfer with minimal overhead, making it a practical choice for handling real-time data pipelines and distributed event processing. It follows a push-based approach, ensuring messages are distributed to consumers as soon as they become available.
Open-source metric sources automatically map to our Smartscape model for AI analytics. We’ve just enhanced Dynatrace OneAgent with an open metric API. Here’s a quick overview of what you can achieve now that the Dynatrace Software Intelligence Platform has been extended to ingest third-party metrics. Dynatrace news.
After being available in an Early Adopter Release, we’re happy to announce that AWS supporting services are now Generally Available (GA). Supporting services include every service that isn’t available with out-of-the-box Dynatrace monitoring. Get up to 300 new AWS metrics out of the box. Everything is customizable.
Network Availability: The expected continued growth of our ecosystem makes it difficult to understand our network bottlenecks and potential limits we may be reaching. The Flow Exporter also publishes various operational metrics to Atlas. These metrics are visualized using Lumen , a self-service dashboarding infrastructure.
Optimized fault recovery We’re also interested in exploring the potential of tuning configurations to improve recovery speed and performance after failures and avoid the demand for additional computing resources. In Kafka Streams, a large configuration space is available for potential optimizations.
To provide “quality signals that are essential to delivering a great user experience on the web,” Google introduced their Core Web Vitals initiative last year, advocating the Largest contentful paint , Cumulative layout shift , and First input delay metrics. with: Aggregated field metrics?rather?than?valuable?details
So, we relied on higher-level metrics-based testing: AB Testing and Sticky Canaries. To determine customer impact, we could compare various metrics such as error rates, latencies, and time to render. We spent the next few months diving into these high-level metrics and fixing issues such as cache TTLs, flawed client assumptions, etc.
The training times and other quality metrics, such as the RMSE (Root Mean Squared Error), SMAPE (Scaled Mean Absolute Percentage Error), and coverage probability, are monitored using Dynatrace. Our data scientists utilize metrics and events to store these quality metrics. For full details, see Dynatrace Documentation.
Dynatrace Visually complete is a point-in-time web performance metric that measures when the visual area of a page has finished loading. Dynatrace is the only solution that provides these user experience metrics consistently for real user monitoring as well as for synthetic monitors. More precisely, you can now: . What you can achieve.
Defining a comprehensive user-experience metric gives rise to questions such as: How do we compare the user experience of one session to another? Which metric can be used for the purpose of reporting user experience and tracking it over a period of time? A single metric for user experience segmentation. Error metrics.
Are you applying AI to the unique metrics and KPIs that matter most to the success of your digital business? Do you provide dashboards and analytics that combine technical and business metrics that are specific to your business? Dynatrace out-of-the-box metrics generally focus on availability, failure rate, and performance.
Similar to the observability desired for a request being processed by your digital services, it’s necessary to comprehend the metrics, traces, logs, and events associated with a code change from development through to production. Stay tuned Currently, the API allows for the configuration of an event processing pipeline.
However, understanding the performance of different application types requires an emphasis on different performance metrics, that is, key performance metrics. For many traditional web applications , User action duration is considered the best metricavailable for web-performance optimization.
Observability is a topic at the top of mind for all architects, Site Reliability Engineers (SREs), and more – each wanting to use observability to proactively detect issues and guarantee the best experience and availability to users. Metric 2: number of requests in error. Let’s start by creating a dashboard to follow our metrics.
Although model-based anomaly detection approaches are more scalable and suitable for real-time analysis, they highly rely on the availability of (often labeled) context-specific data. Manifest is requested by the client and gets delivered to the player before the license request, and it itemizes the available streams.
With the availability of Linux on IBM Z and LinuxONE, the IBM Z platform brings a familiar host operating system and sustainability that could yield up to 75% energy reduction compared to x86 servers. You can now install OneAgent on Linux with s390 architecture. Next, set up log ingest.
A metric crossed a threshold. You’re half awake and wondering, “Is there really a problem or is this just an alert that needs tuning? Telltale learns what constitutes typical health for an application, no alert tuning required. Metrics are a key part of understanding application health. Client metrics and QoE changes.
To stay tuned, keep an eye on our release notes. General Availability (Build 1.241.153). General Availability (Build 1.241.153). Improved efficiency and response time of filter operators in metric selectors that both apply an entity selector and filter a dimension called `Container` or `Process`. (APM-368260).
But this is hard to achieve at scale: Development teams need specific insights into the microservices they are responsible for, reflecting particular metrics, dashboards, custom alerts, service-level objectives (SLOs), or even automatic remediation steps. , or “Did the last update cause the application issue or was it something else?”
Great news: OpenTelemetry endpoint detection, analyzing OpenTelemetry services, and visualizing Istio service mesh metrics just got easier. As a CNCF open source incubating project, OpenTelemetry provides a standardized set of APIs, libraries, agents, instrumentation, and specifications for logging, metrics, and tracing.
Every service and component exposes observability data (metrics, logs, and traces) that contains crucial information to drive digital businesses. The “three pillars of observability,” metrics, logs, and traces, still don’t tell the whole story. Track log metrics and receive alerts without manually setting thresholds.
While Dynatrace provides software intelligence to accelerate your company’s digital transformation, web analytics tools like Adobe Analytics help you deeply understand your user journeys, segmentation, behavior, and strategic business metrics such as revenue, orders, and conversion goals. Alert based on your new metric.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content