This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In September, we announced the availability of the Dynatrace Software Intelligence Platform on Microsoft Azure as a SaaS solution and natively in the Azure portal. Today, we are excited to provide an update that Dynatrace SaaS on Azure is now generally available (GA) to the public through Dynatrace sales channels. Dynatrace news.
In IT and cloud computing, observability is the ability to measure a system’s current state based on the data it generates, such as logs, metrics, and traces. An advanced observability solution can also be used to automate more processes, increasing efficiency and innovation among Ops and Apps teams. What is observability?
As HTTP and browser monitors cover the application level of the ISO /OSI model , successful executions of synthetic tests indicate that availability and performance meet the expected thresholds of your entire technological stack. Our script, available on GitHub , provides details. Are the corresponding services running on those hosts?
From a cost perspective, internal customers waste valuable time sending tickets to operations teams asking for metrics, logs, and traces to be enabled. A team looking for metrics, traces, and logs no longer needs to file a ticket to get their app monitored in their own environments. This approach is costly and error prone.
The business process observability challenge Increasingly dynamic business conditions demand business agility; reacting to a supply chain disruption and optimizing order fulfillment are simple but illustrative examples. Most business processes are not monitored. First and foremost, it’s a data problem.
A Data Movement and Processing Platform @ Netflix By Bo Lei , Guilherme Pires , James Shao , Kasturi Chatterjee , Sujay Jain , Vlad Sydorenko Background Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users.
By leveraging Dynatrace observability on Red Hat OpenShift running on Linux, you can accelerate modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes. Dynatrace observability is available for Red Hat OpenShift on IBM Power.
Metrics matter. But without complex analytics to make sense of them in context, metrics are often too raw to be useful on their own. To achieve relevant insights, raw metrics typically need to be processed through filtering, aggregation, or arithmetic operations. Examples of metric calculations. Dynatrace news.
Dynatrace has recently extended its Kubernetes operator by adding a new feature, the Prometheus OpenMetrics Ingest , which enables you to import Prometheus metrics in Dynatrace and build SLO and anomaly detection dashboards with Prometheus data. Here we’ll explore how to collect Prometheus metrics and what you can achieve with them.
Micrometer is used for instrumenting both out-of-the-box and custom metrics from Spring Boot applications. Davis topology-aware anomaly detection and alerting for your Micrometer metrics. Topology-related custom metrics for seamless reports and alerts. Micrometer uses a registry to export metrics to monitoring systems.
Dynatrace Managed is intrinsically highly available as it stores three copies of all events, user sessions, and metrics across its cluster nodes. Our Premium High Availability comes with the following features: Active-active deployment model for optimum hardware utilization. Dynatrace news.
From reacting to keywords that signal special offers, browsing the latest products, adding items to the shopping cart, checking out, and handling shipping, all the details of each user journey is available in logs. For example, Dynatrace recently introduced the extraction of log-based metrics for JSON logs.
Speed, UX, availability, and frequency of updates are increasingly important with mobile apps. But this process usually takes a couple of weeks. Consumers and enterprises alike expect more from software. During that time, users can get frustrated with performance issues making them more likely to leave a bad review in the app store.
The end goal, of course, is to optimize the availability of organizations’ software. Dynatrace is widely recognized for its AI capabilities’ ability to predict and prevent issues, and automatically identify root causes, maximizing availability. Automation, however, should not be done in isolation of tech.
The five key metrics to improve customer satisfaction To help turn this around, Dynatrace makes available its unified observability platform, which captures all CX interactions and transactions in an automated, intelligent manner – including user session replays. When combined, key metrics will generate an accurate CX index score.
With Dynatrace, you only need to install a single OneAgent per host to collect all relevant metrics from 100% of your application-delivery chain. Given our relatively frequent releases, this means that you can benefit from 11 to 12 OneAgent updates a year that are deployed as soon as they are available for your environment.
Unrealized optimization potential of business processes due to monitoring gaps Imagine a retail company facing gaps in its business process monitoring due to disparate data sources. Due to separated systems that handle different parts of the process, the view of the process is fragmented.
The nirvana state of system uptime at peak loads is known as “five-nines availability.” In its pursuit, IT teams hover over system performance dashboards hoping their preparations will deliver five nines—or even four nines—availability. But is five nines availability attainable? Downtime per year. 90% (one nine).
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. Data is then dynamically routed into pipelines for further processing. Understanding the context.
To get a more granular look into telemetry data, many analysts rely on custom metrics using Prometheus. Named after the Greek god who brought fire down from Mount Olympus, Prometheus metrics have been transforming observability since the project’s inception in 2012.
Monitoring and observability are two key concepts that facilitate this process, offering valuable visibility into the health and performance of systems. It typically involves setting up specific metrics, thresholds, and alerting mechanisms to track the performance and availability of various components.
That is, relying on metrics, logs, and traces to understand what software is doing and where it’s running into snags. In addition to tracing, observability also defines two other key concepts, metrics and logs. When software runs in a monolithic stack on on-site servers, observability is manageable enough. What is OpenTelemetry?
One issue that often complicates this process is the "noisy neighbor" problem. To emit a run queue latency metric, we leveraged three eBPF hooks: sched_wakeup, sched_wakeup_new, and sched_switch. The sched_wakeup and sched_wakeup_new hooks are invoked when a process changes state from 'sleeping' to 'runnable.'
Open-source metric sources automatically map to our Smartscape model for AI analytics. We’ve just enhanced Dynatrace OneAgent with an open metric API. Here’s a quick overview of what you can achieve now that the Dynatrace Software Intelligence Platform has been extended to ingest third-party metrics. Dynatrace news.
By leveraging the Dynatrace Operator and Dynatrace capabilities on Red Hat OpenShift on IBM Power, customers can accelerate their modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes.
By implementing service-level objectives, teams can avoid collecting and checking a huge amount of metrics for each service. When organizations implement SLOs, they can improve software development processes and application performance. The performance SLO needs a custom SLI metric, which you can configure as follows.
Dynatrace’s ability to ingest metrics from all 95 AWS services will be available within the next 60 days. Those in the left column are readily available now, with those in the right available soon. Available Now. AWS SDK Metrics for Enterprise Support. Achieve full observability of all AWS services.
To transparently manage expectations and maintain trust with our customers, we expanded the Dynatrace SLA beyond accessing the user interface to cover the full range of relevant product categories, such as processing and retaining incoming data, accessing and working with data, and triggering automations.
The second phase involves migrating the traffic over to the new systems in a manner that mitigates the risk of incidents while continually monitoring and confirming that we are meeting crucial metrics tracked at multiple levels. It provides a good read on the availability and latency ranges under different production conditions.
Available directly from the AWS Marketplace , Dynatrace provides full-stack observability and AI to help IT teams optimize the resiliency of their cloud applications from the user experience down to the underlying operating system, infrastructure, and services. How does Dynatrace help?
As our customers adopt agile software development and continuous delivery to drive value faster, they face new risks that could impact availability, performance, and business KPIs. We’ll explore the process of defining SLOs and using the API to scale-out SLOs. An SLI is a measurement of the performance or availability of an entity.
Network Availability: The expected continued growth of our ecosystem makes it difficult to understand our network bottlenecks and potential limits we may be reaching. The Flow Exporter also publishes various operational metrics to Atlas. These metrics are visualized using Lumen , a self-service dashboarding infrastructure.
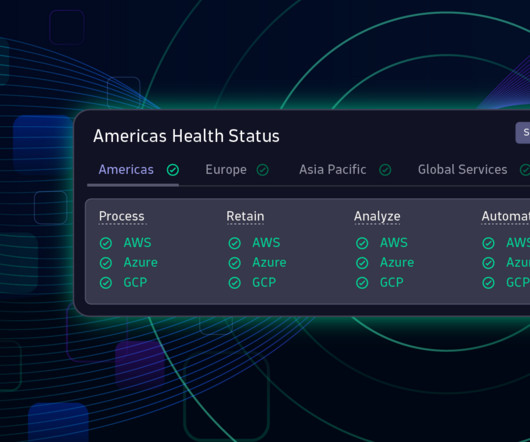
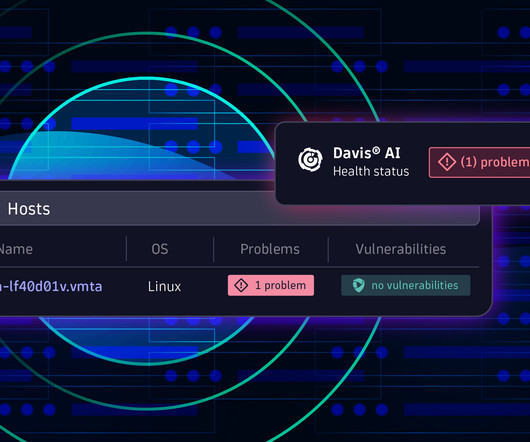
The newly introduced Network devices and Details view within Hosts provide comprehensive health status information, relevant networking signals, and machine metrics—all analyzed and provided by the industry-leading combination of Dynatrace Grail™ data lakehouse and Davis ® AI. Overview of a cloud-hosted frontend web application.
These technologies are poorly suited to address the needs of modern enterprises—getting real value from data beyond isolated metrics. As a result, we created Grail with three different building blocks, each serving a special duty: Ingest and process. Ingest and process with Grail. Thus, Grail was born. Retain data.
Event Prioritization Considering the use cases were wide ranging both in terms of their sources and their importance, we built segmentation into the event processing. We thus assigned a priority to each use case and sharded event traffic by routing to priority-specific queues and the corresponding event processing clusters.
Replay traffic testing gives us the initial foundation of validation, but as our migration process unfolds, we are met with the need for a carefully controlled migration process. A process that doesn’t just minimize risk, but also facilitates a continuous evaluation of the rollout’s impact.
You will need to know which monitoring metrics for Redis to watch and a tool to monitor these critical server metrics to ensure its health. Redis returns a big list of database metrics when you run the info command on the Redis shell. You can pick a smart selection of relevant metrics from these.
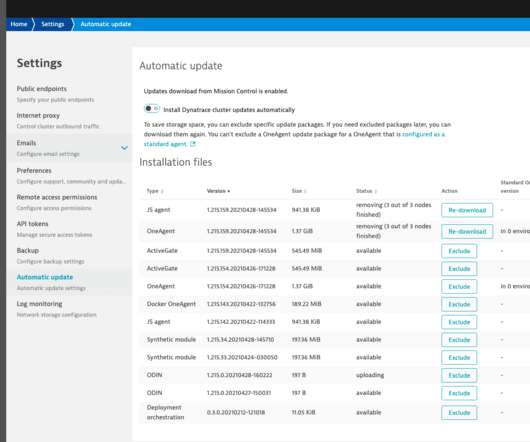
Self-service update packages management is now available. You can safe your disk space and have more control over what’s available to your cluster . Resolved issue in which incorrect target versions were available for OneAgent update on host, host group, and environment level settings. APM-294723). APM-290958).
A $20 billion Germany-based financial services company told us they found the process of pushing Syslog messages to Dynatrace natively to be seamless. Logs are immediately available for troubleshooting, security investigations, and auditing, becoming integral to the platform alongside traces and metrics.
Keeping pace with modern digital transformation requires ensuring that applications are responsive, resilient, and always available amid increased complexity. As a result, site reliability has emerged as a critical success metric for many organizations. That’s why good communication between SREs and DevOps teams is important.
This lets you build your SLOs around the indicators that matter to you and your customers—critical metrics related to availability, failure rates, request response times, or select logs and business events. Hence, having a dedicated dashboard tile visualizing the key parameters of each SLO simplifies the process of evaluating them.
Monitoring , by textbook definition, is the process of collecting, analyzing, and using information to track a program’s progress toward reaching its objectives and to guide management decisions. Monitoring focuses on watching specific metrics. Here’s a closer look at logs, metrics, and distributed traces.
As a Network Engineer, you need to ensure the operational functionality, availability, efficiency, backup/recovery, and security of your company’s network. As you might know, we recently simplified observability for all custom metrics by making it possible to ingest hundreds of custom data sources into Dynatrace. Events and alerts.
Listen, learn, improve, and repeat The latest update to the Citrix monitoring extension is now available. Effortlessly monitor your Citrix environment with Dynatrace The Citrix monitoring process now employs two methods to collect metrics and provide complete Citrix performance observability.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content